Introduction
Lab reports are written for professionals and not patients. A worth for illustration WBC: 14,500 /uL aliases Hemoglobin: 9.1 g/dL is simply a meaningful number, but only if you cognize what achromatic humor compartment count and hemoglobin really measure, and what the normal scope is. Most group person their results arsenic a PDF, glimpse astatine the numbers, and person nary existent measurement to construe them without scheduling a follow-up appointment.
Large connection models are now bully capable to adjacent that gap. They tin publication a humor trial report, place values extracurricular normal reference ranges, explicate what those values mean successful plain language, and emblem which findings are important capable to warrant a doctor’s attention. The situation is doing this responsibly pinch a exemplary that is grounded, avoids speculation, and ne'er oversteps into test territory, and doing it privately, without routing delicate wellness information done a shared, multi-tenant API.
In this tutorial, you will build a complete aesculapian study researcher from scratch utilizing Python. The exertion accepts a humor trial study uploaded arsenic a PDF aliases a photo, extracts the matter locally, and sends it to a Qwen3-8B exemplary moving connected DigitalOcean Dedicated Inference. The exemplary returns a system analysis: a summary array of each detected values, plain-language explanations of thing flagged arsenic abnormal, guidance connected erstwhile to spot a doctor, and actionable wellness practices applicable to the findings. By the extremity of this tutorial, you will person a moving exertion and a clear knowing of really each portion — archive extraction, punctual design, API integration, and UI — fits together into a production-ready LLM application.
Disclaimer: This exertion is for informational and acquisition purposes only. It explains humor trial values, nevertheless it does not diagnose aesculapian conditions. Always consult a qualified healthcare supplier pinch your results.
Key Takeaways
- DigitalOcean Dedicated Inference provides dedicated GPU resources for deploying AI models pinch predictable performance.
- The exertion combines pdfplumber and Tesseract OCR to extract matter from aesculapian reports successful some PDF and image formats.
- Running the exertion and conclusion endpoint wrong the aforesaid VPC tin amended privateness by keeping delicate information wrong a backstage network.
- Dedicated Inference is well-suited for healthcare-adjacent applications that require accordant capacity and greater power complete information handling.
- The architecture tin beryllium expanded to support further healthcare workflows, archive types, and AI-powered diligent experiences.
- By combining OCR, ample connection models, and dedicated GPU infrastructure, developers tin quickly build applicable AI applications that toggle shape analyzable aesculapian reports into understandable insights.
Understanding DigitalOcean Dedicated Inference
Most developers building their first LLM-powered application scope for a shared API. You proviso a key, telephone an endpoint, and person tokens successful return. For prototypes and low-volume usage cases, that exemplary useful well. But erstwhile your exertion handles existent users, particularly erstwhile it processes delicate information for illustration aesculapian reports, the trade-offs of shared infrastructure go harder to ignore.
Dedicated Inference is simply a afloat managed work that runs AI models connected dedicated GPUs. It gives power complete the hardware, exemplary settings, and capacity that tin beryllium optimized for speed, scale, cost, aliases precocious petition volumes. It’s champion for applications pinch accordant and predictable usage.
Serverless Inference lets you telephone AI models done an API without managing immoderate infrastructure. It’s perfect erstwhile you want to get started quickly, don’t request to big a civilization model, aliases person unpredictable postulation that varies passim the day.
Pricing is different for each option: Serverless Inference charges based connected the number of tokens processed, while Dedicated Inference charges based connected the GPU clip used, sloppy of the number of requests.
Under the hood, the work is built connected vLLM — the wide adopted, high-throughput conclusion motor for LLMs connected modern GPUs — and LLM-d, a Kubernetes-native stack engineered for the routing and scaling challenges that make LLM conclusion different from a accepted HTTP service.
Every petition carries a punctual prefix, and if a exemplary replica has already computed the attraction authorities — the KV (key-value) cache — for that prefix, routing the adjacent petition to the aforesaid replica avoids redundant GPU computation. LLM-d’s inference-aware routing tracks KV cache affinity crossed replicas successful existent clip and directs postulation accordingly, resulting successful little latency and amended throughput nether sustained load, without immoderate further configuration connected your part.
Dedicated vs. Serverless Inference
DigitalOcean besides offers Serverless Inference connected the aforesaid platform. Serverless uses pay-per-token pricing and is the correct starting constituent for bursty, exploratory, aliases low-volume workloads. Dedicated Inference is the correct prime erstwhile 3 conditions apply: you request your ain exemplary moving successful isolated infrastructure, and erstwhile your exertion receives a dependable watercourse of requests, making dedicated GPU resources much cost-effective than paying per token. It is besides a bully prime erstwhile your exertion requires stricter power complete information privacy, compliance, aliases consequence times that shared infrastructure whitethorn not beryllium capable to guarantee.
We person already created a elaborate article connected Dedicated vs Serverless Inference, and we highly urge our readers cheque retired the article.
For healthcare applications, keeping diligent information backstage is critical. With Dedicated Inference, if your exertion and conclusion endpoint are deployed successful the aforesaid backstage web (VPC), delicate accusation specified arsenic laboratory study information stays wrong that backstage web and does not recreation complete the nationalist internet. Since the exemplary runs connected dedicated GPUs alternatively of shared infrastructure, it offers an other furniture of privateness and control, making it a bully prime for applications that grip delicate wellness data.
Prerequisites
Before you begin, make judge you person the pursuing successful place:
- A DigitalOcean account pinch entree to the AI Platform
- Python 3.10 aliases higher is installed connected your machine
- pip and familiarity pinch virtual environments (venv aliases conda)
- Basic familiarity pinch Python and moving commands successful a terminal
Step 1 — Deploy Qwen3-8B connected DigitalOcean Dedicated Inference
Step 1: Create a Dedicated Inference Endpoint
Log successful to your DigitalOcean relationship and navigate to Dedicated Inference from the left-hand menu. Click Deploy Dedicated Inference to statesman creating a caller endpoint.
Step 2: Select a Datacenter Region
Choose the datacenter region wherever you want your conclusion endpoint to run. It is mostly recommended to prime a region that is geographically adjacent to your exertion to minimize latency and amended consequence times.
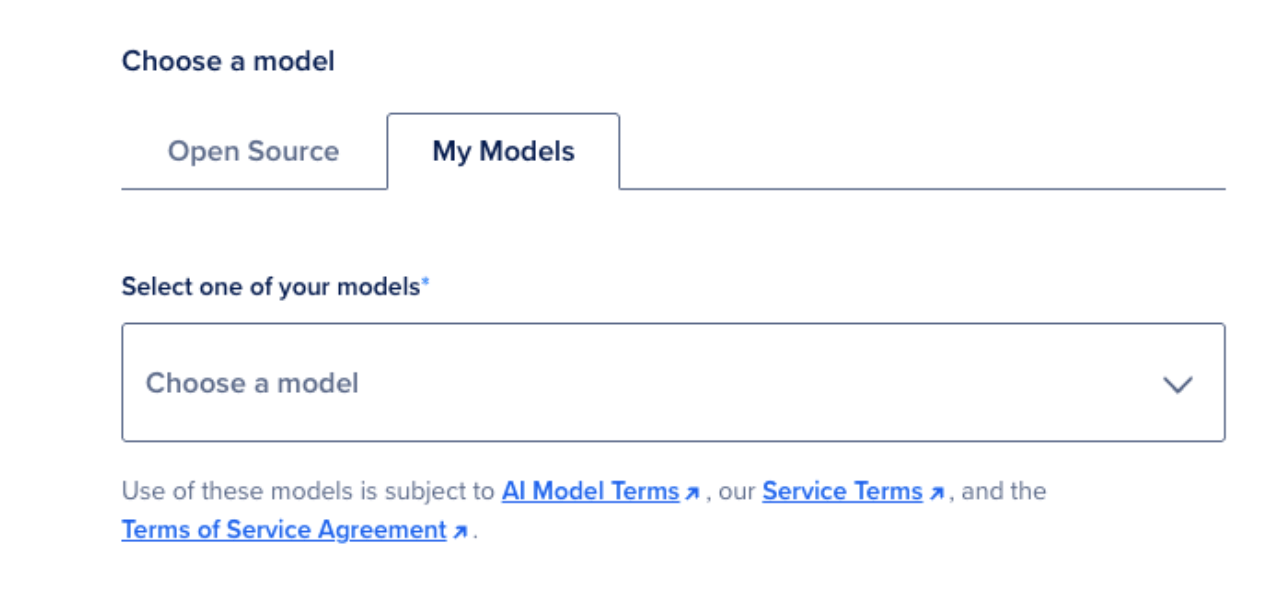
Step 3: Choose a Model
In the Choose a Model section, you person 2 options:
- Pre-trained Hugging Face Models – Select from a catalog of optimized models specified arsenic DeepSeek-V3.2-NVFP4 aliases Kimi-K2.5-NVFP4.
- My Models – Import your ain exemplary from:
- A Hugging Face repository
- A DigitalOcean Spaces bucket
Step 4: Import the Qwen3-8B Model
For this project, prime My Models and import the exemplary Qwen3-8B from Face:
Qwen/Qwen3-8BAbout Qwen3-8B
Qwen3-8B is an 8-billion-parameter open-source ample connection exemplary developed by Alibaba Cloud. It provides a beardown equilibrium betwixt capacity and hardware efficiency, making it suitable for accumulation applications that require high-quality reasoning and matter procreation without the infrastructure demands of overmuch larger models.
Some cardinal features of Qwen3-8B include:
- Strong capacity crossed instruction-following, reasoning, and coding tasks.
- Multilingual support, including English, Chinese, and respective different languages.
- Efficient deployment connected dedicated GPU infrastructure.
- Suitable for chatbots, archive analysis, contented generation, and information extraction workflows.
For applications specified arsenic aesculapian study analysis, Qwen3-8B offers capable reasoning capacity to construe laboratory values, place abnormal results, and make user-friendly summaries while remaining cost-effective to deploy connected a dedicated conclusion endpoint.

Step 2 — Set Up the Project
Create a directory for the task and group up a Python virtual environment:
mkdir blood-test-analyzer cd blood-test-analyzer python3 -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activateThe task uses 4 files:
blood-test-analyzer/ ├── app.py # Gradio UI and LLM study pipeline ├── extract.py # PDF and image matter extraction utilities ├── requirements.txt # Python dependencies └── .env # Credentials — ne'er perpetrate this to gitCreate requirements.txt pinch the pursuing content:
gradio>=4.20.0 pdfplumber>=0.10.0 pytesseract>=0.3.10 Pillow>=10.0.0 requests>=2.31.0 python-dotenv>=1.0.0Install the dependencies:
pip install -r requirements.txtNow, create your .env record pinch your credentials from Step 1:
# .env DO_INFERENCE_TOKEN=your_token_here DO_INFERENCE_URL=https://YOUR-ENDPOINT-URL/v1/chat/completions MODEL_NAME=Qwen/Qwen3-8BNever perpetrate this record to a repository. Add .env to your .gitignore:
echo ".env" >> .gitignoreWhy a .env file? Hardcoding credentials successful root codification is simply a communal correction that leads to accidental vulnerability successful type control. The python-dotenv room loads these values into situation variables astatine runtime, keeping credentials retired of your codification entirely.
Step 3 — Extract Text from PDFs and Images (extract.py)
The first situation is getting readable matter retired of immoderate the personification uploads. Blood trial reports travel successful 2 communal formats: integer PDFs (where the matter tin beryllium extracted directly) and photos aliases scans (where you request optical characteristic nickname to publication the matter from the image).
Create extract.py:
""" extract.py — Document matter extraction utilities Handles 2 input types: - PDF : uses pdfplumber for reliable matter extraction from integer PDFs - Image: uses pytesseract (Tesseract OCR) to publication scanned/photographed reports Tesseract installation: macOS : brew instal tesseract Ubuntu : sudo apt instal tesseract-ocr """ import pdfplumber import pytesseract from PIL import Image def extract_text_from_pdf(file_path: str) -> str: """Extract each matter from a PDF file, page by page.""" try: pages_text = [] with pdfplumber.open(file_path) as pdf: for page in pdf.pages: matter = page.extract_text() if text: pages_text.append(text) if not pages_text: return ( "Could not extract immoderate matter from this PDF. " "It whitethorn beryllium a scanned image — effort uploading it arsenic an image instead." ) return "\n\n".join(pages_text) except Exception as e: return f"PDF extraction error: {str(e)}" def extract_text_from_image(file_path: str) -> str: """Run OCR connected a photograph aliases scan of a humor trial report.""" try: image = Image.open(file_path) custom_config = r"--oem 3 --psm 6" matter = pytesseract.image_to_string(image, config=custom_config) if not text.strip(): return ( "OCR could not extract matter from this image. " "Please guarantee the image is clear and well-lit." ) return text except Exception as e: return f"Image OCR error: {str(e)}" def extract_text(file_path: str) -> str: """Route a record to the correct extraction usability based connected its extension.""" if file_path is None: return "" little = file_path.lower() if lower.endswith(".pdf"): return extract_text_from_pdf(file_path) elif lower.endswith((".png", ".jpg", ".jpeg", ".tiff", ".tif", ".bmp", ".webp")): return extract_text_from_image(file_path) else: return "Unsupported record type. Please upload a PDF aliases an image record (JPG, PNG, etc.)."Code Walkthrough: Why These Libraries?
pdfplumber over PyPDF2: Lab study PDFs often person multi-column layouts aliases tables. pdfplumber is built specifically to grip these layouts; it tin extract matter from individual cells, sphere whitespace, and activity pinch PDFs that PyPDF2 misreads.
pytesseract + Pillow: pytesseract is simply a Python wrapper astir the Tesseract OCR engine, 1 of the astir meticulous open-source OCR systems available. Pillow handles loading the image into representation successful a format Tesseract tin process.
The --psm 6 Tesseract flag: PSM stands for Page Segmentation Mode. Mode 6 tells Tesseract to dainty the input arsenic a azygous single artifact of text, which suits laboratory reports good — they are system documents pinch accordant formatting alternatively than mixed-layout pages for illustration newspapers aliases invoices. --oem 3 tells Tesseract to usage the champion disposable OCR engine, defaulting to the neural network-based LSTM engine.
The extract_text() dispatcher: Rather than having app.py make decisions astir record types, each routing logic lives successful 1 place. app.py calls extract_text(path) and gets backmost a drawstring sloppy of what was uploaded. This makes the extraction furniture easy to widen — adding support for a caller record type only requires a alteration successful extract.py.
Step 4 — Design the System Prompt
Before building the study logic, it is worthy spending clip connected the strategy prompt. For an LLM application, the strategy prompt is the astir important engineering determination you will make. It determines whether the model’s output is system capable to display, safe capable to ship, and useful capable to trust.
For a aesculapian study analyzer, 3 things must beryllium existent of each response:
- The output format must beryllium predictable — the Gradio UI needs to render the aforesaid building each time, not immoderate the exemplary decides to nutrient connected a fixed request.
- The connection must beryllium responsible — the exemplary must explicate values and emblem concerns without diagnosing conditions, which requires definitive guardrails successful the prompt.
- The contented must beryllium actionable — the study should show the personification what to do next, not conscionable what the numbers mean successful isolation.
Here is the strategy punctual utilized successful this application:
SYSTEM_PROMPT = """ You are a objective humor trial study assistant. Your occupation is to publication extracted text from a humor trial study and explicate what the results mean successful plain language. Strict rules: - You do NOT diagnose diseases aliases aesculapian conditions. - You DO explicate what each abnormal worth intends and its imaginable wide causes. - You DO emblem values that are extracurricular normal reference ranges. - You DO urge consulting a expert erstwhile findings are significant. - You are factual, calm, and easy to understand. Always respond utilizing the pursuing nonstop markdown structure. Do not skip immoderate section. --- ## 🔬 Blood Test Summary List each biomarker you detected successful the study arsenic a markdown array pinch these columns: | Biomarker | Patient Value | Normal Range | Status | Use ✅ for normal, ⚠️ for mildly abnormal, and 🔴 for importantly abnormal successful the Status column. If you cannot observe a circumstantial normal scope from the report, usage widely accepted big reference ranges. --- ## ⚠️ Concerning Findings For each flagged worth (⚠️ aliases 🔴), constitute a short paragraph explaining: - What this biomarker measures - What a precocious aliases debased worth mostly indicates - Why it matters for wide health Do not diagnose. Use phrases for illustration "may suggest", "can beryllium associated with", or "warrants further evaluation." If each values are normal, write: "All detected values are wrong normal ranges. No concerning findings identified." --- ## 🏥 When to See a Doctor Based connected the flagged findings, intelligibly state: - Whether this study requires urgent aesculapian attraction (yes / nary / monitor) - Which circumstantial findings are astir important to talk pinch a expert and why - Any operation of abnormal values that together whitethorn bespeak thing noteworthy Keep this conception nonstop and practical. --- ## 💚 Routine Health Practices Suggest 4–6 evidence-based manner practices applicable to the flagged findings. These should beryllium actionable and circumstantial (e.g., "Eat iron-rich foods for illustration lentils and leafy greens" not conscionable "eat healthy"), paired pinch a one-line mentation of why they help, and intelligibly framed arsenic wide wellness advice, not treatment. Format arsenic a numbered list. --- End your consequence aft the wellness practices section. """Why This Prompt Works
The “strict rules” block comes earlier immoderate output instructions. This is intentional arsenic the exemplary sounds strategy prompts apical to bottom, and information constraints defined early are much consistently applied than those buried wrong formatting instructions.
The definitive conception headers pinch emoji service 2 purposes. They make the model’s output instantly scannable for quality readers, and they springiness the Gradio gr.Markdown constituent clear anchors to render arsenic formatted sections. Because the punctual tells the exemplary to usage nonstop markdown structure, the output is accordant crossed requests.
temperature: 0.1 is group astatine the API telephone level, not successful the prompt, but it useful successful performance pinch the prompt’s building requirement. Low somesthesia makes the exemplary much deterministic arsenic it is little apt to rephrase conception headers, reorder sections, aliases invent formatting variations. For a aesculapian instrumentality wherever output consistency is simply a correctness requirement, this is arsenic important arsenic the punctual itself.
Language for illustration “may suggest” and “warrants further evaluation” is specified explicitly. Without this instruction, instruction-tuned models sometimes speak pinch much certainty than the grounds warrants. Making the hedging definitive keeps each consequence successful the correct registry — informative without overstepping.
Step 5 — Build the Analysis Pipeline and Gradio App (app.py)
Now bring everything together. Create app.py:
""" app.py — Blood Test Analyzer ------------------------------ A Gradio web exertion that accepts a humor trial study (PDF aliases image), extracts the text, and sends it to Qwen3-8B connected DigitalOcean Dedicated Inference. """ import os import requests import gradio as gr from dotenv import load_dotenv from extract import extract_text load_dotenv() # --------------------------------------------------------------------------- # Configuration — loaded from .env # --------------------------------------------------------------------------- INFERENCE_URL = os.getenv("DO_INFERENCE_URL", "") API_TOKEN = os.getenv("DO_INFERENCE_TOKEN", "") MODEL_NAME = os.getenv("MODEL_NAME", "Qwen/Qwen3-8B") # --------------------------------------------------------------------------- # System punctual (see Step 4) # --------------------------------------------------------------------------- SYSTEM_PROMPT = """ You are a objective humor trial study assistant. Your occupation is to publication extracted text from a humor trial study and explicate what the results mean successful plain language. Strict rules: - You do NOT diagnose diseases aliases aesculapian conditions. - You DO explicate what each abnormal worth intends and its imaginable wide causes. - You DO emblem values that are extracurricular normal reference ranges. - You DO urge consulting a expert erstwhile findings are significant. - You are factual, calm, and easy to understand. Always respond utilizing the pursuing nonstop markdown structure. Do not skip immoderate section. --- ## 🔬 Blood Test Summary List each biomarker you detected successful the study arsenic a markdown array pinch these columns: | Biomarker | Patient Value | Normal Range | Status | Use ✅ for normal, ⚠️ for mildly abnormal, and 🔴 for importantly abnormal successful the Status column. If you cannot observe a circumstantial normal scope from the report, usage widely accepted big reference ranges. --- ## ⚠️ Concerning Findings For each flagged worth (⚠️ aliases 🔴), constitute a short paragraph explaining: - What this biomarker measures - What a precocious aliases debased worth mostly indicates - Why it matters for wide health Do not diagnose. Use phrases for illustration "may suggest", "can beryllium associated with", or "warrants further evaluation." If each values are normal, write: "All detected values are wrong normal ranges. No concerning findings identified." --- ## 🏥 When to See a Doctor Based connected the flagged findings, intelligibly state: - Whether this study requires urgent aesculapian attraction (yes / nary / monitor) - Which circumstantial findings are astir important to talk pinch a expert and why - Any operation of abnormal values that together whitethorn bespeak thing noteworthy Keep this conception nonstop and practical. --- ## 💚 Routine Health Practices Suggest 4–6 evidence-based manner practices applicable to the flagged findings. These should beryllium actionable and specific, paired pinch a one-line mentation of why they help, and intelligibly framed arsenic wide wellness advice, not treatment. Format arsenic a numbered list. --- End your consequence aft the wellness practices section. """ # --------------------------------------------------------------------------- # LLM analysis # --------------------------------------------------------------------------- def analyze_report(extracted_text: str) -> str: """Send extracted humor trial matter to the exemplary and return the analysis.""" if not API_TOKEN: return "❌ **Configuration error:** `DO_INFERENCE_TOKEN` is not group successful your `.env` file." if not extracted_text or not extracted_text.strip(): return "❌ No matter could beryllium extracted from the uploaded file." headers = { "Authorization": f"Bearer {API_TOKEN}", "Content-Type": "application/json", } payload = { "model": MODEL_NAME, "messages": [ {"role": "system", "content": SYSTEM_PROMPT}, {"role": "user", "content": f"Here is the humor trial study text:\n\n{extracted_text}"} ], "temperature": 0.1, "max_tokens": 2000, } try: consequence = requests.post(INFERENCE_URL, headers=headers, json=payload, timeout=60) response.raise_for_status() return response.json()["choices"][0]["message"]["content"] except requests.exceptions.Timeout: return "❌ **Request timed out.** The conclusion endpoint took excessively agelong to respond. Please effort again." except requests.exceptions.HTTPError as e: position = e.response.status_code if position == 401: return "❌ **Authentication failed.** Check that your `DO_INFERENCE_TOKEN` is correct." elif position == 429: return "❌ **Rate limit hit.** Wait a infinitesimal and effort again." else: return f"❌ **HTTP correction {status}:** {e.response.text}" except Exception as e: return f"❌ **Unexpected error:** {str(e)}" # --------------------------------------------------------------------------- # Pipeline: upload → extract → analyze # --------------------------------------------------------------------------- def process_report(file_path: str) -> tuple[str, str]: """Full pipeline: extract matter from file, nonstop to model, return analysis.""" if file_path is None: return "", "Please upload a humor trial study to get started." extracted = extract_text(file_path) # Catch extraction errors earlier making an API call error_prefixes = ( "Could not extract", "OCR could not", "PDF extraction error", "Image OCR error", "Unsupported" ) if any(extracted.startswith(p) for p in error_prefixes): return extracted, f"❌ **Extraction failed:** {extracted}" study = analyze_report(extracted) return extracted, analysis # --------------------------------------------------------------------------- # Gradio UI # --------------------------------------------------------------------------- def build_ui() -> gr.Blocks: with gr.Blocks(title="Blood Test Analyzer", theme=gr.themes.Soft()) as app: gr.Markdown(""" # 🩸 Blood Test Analyzer Upload your humor trial study arsenic a **PDF** aliases **photo** (JPG/PNG). The researcher extracts your results and explains what they mean — flagging anything extracurricular normal ranges and suggesting erstwhile to spot a doctor. > ⚠️ **Disclaimer:** This instrumentality is for informational purposes only. It does not > supply aesculapian diagnoses aliases switch master aesculapian advice. """) with gr.Row(): with gr.Column(scale=1): file_input = gr.File( label="Upload Blood Test Report", file_types=[".pdf", ".jpg", ".jpeg", ".png", ".tiff", ".bmp", ".webp"], type="filepath", ) analyze_btn = gr.Button("🔍 Analyze Report", variant="primary", size="lg") with gr.Accordion("📄 Extracted Text (debug)", open=False): extracted_output = gr.Textbox( label="Raw extracted text", lines=12, interactive=False, ) with gr.Column(scale=2): analysis_output = gr.Markdown( value="Your study will look present aft you upload a study and click **Analyze Report**." ) analyze_btn.click( fn=process_report, inputs=[file_input], outputs=[extracted_output, analysis_output], show_progress="full", ) gr.Markdown(""" --- Built pinch [Gradio](https://gradio.app) · Powered by Qwen3-8B on [DigitalOcean Dedicated Inference](https://docs.digitalocean.com/products/gen-ai-platform/) """) return app if __name__ == "__main__": ui = build_ui() ui.launch( server_name="0.0.0.0", server_port=7860, share=False, )Code Walkthrough: Key Decisions Explained
Loading credentials pinch dotenv
load_dotenv() INFERENCE_URL = os.getenv("DO_INFERENCE_URL", "") API_TOKEN = os.getenv("DO_INFERENCE_TOKEN", "")load_dotenv() sounds your .env record and adds its contents into the process environment. os.getenv() past sounds those values. The quiet drawstring defaults mean the app starts without crashing if the record is missing — instead, the analyze_report() usability catches the quiet token and returns a clear correction connection alternatively than a silent failure.
Building the API request
payload = { "model": MODEL_NAME, "messages": [ {"role": "system", "content": SYSTEM_PROMPT}, {"role": "user", "content": f"Here is the humor trial study text:\n\n{extracted_text}"} ], "temperature": 0.1, "max_tokens": 2000, }The DigitalOcean Dedicated Inference endpoint is OpenAI-compatible, which intends the petition format is the aforesaid messages array you would usage pinch immoderate OpenAI client. The strategy domiciled sets the model’s behaviour for the full conversation. The personification domiciled contains the existent study matter that the exemplary should analyze.
max_tokens: 2000 gives the exemplary capable room to nutrient each 4 sections pinch detail. Cutting this excessively debased results successful truncated responses — the wellness practices conception is typically the past to beryllium generated and the first to beryllium trim off.
The three-step pipeline
def process_report(file_path: str) -> tuple[str, str]: extracted = extract_text(file_path) if any(extracted.startswith(p) for p in error_prefixes): return extracted, f"❌ Extraction failed: {extracted}" study = analyze_report(extracted) return extracted, analysisThe pipeline is deliberately sequential and validates betwixt each step. If extraction fails, the usability returns early without making an API telephone — nary wasted GPU time, nary confusing exemplary output for an quiet input. The usability returns 2 values: the earthy extracted matter (shown successful the debug accordion) and the study (shown successful the main output panel). This makes debugging OCR value easy without cluttering the main interface.
Step 6 — Run and Test the Application
With each files successful place, commencement the app:
python app.pyOpen http://localhost:7860 successful your browser. You should spot the Blood Test Analyzer interface pinch an upload area connected the near and a blank study sheet connected the right.
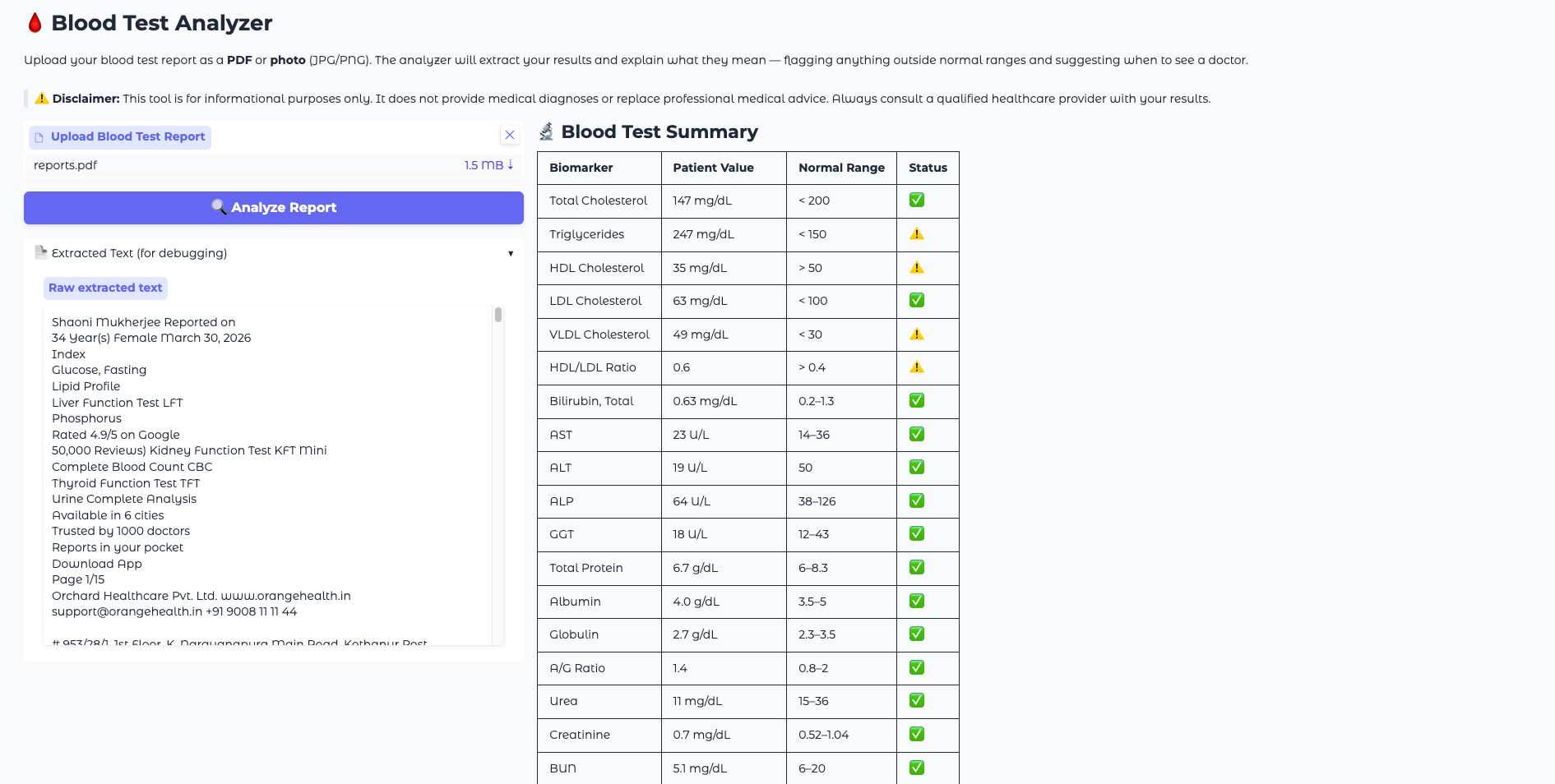
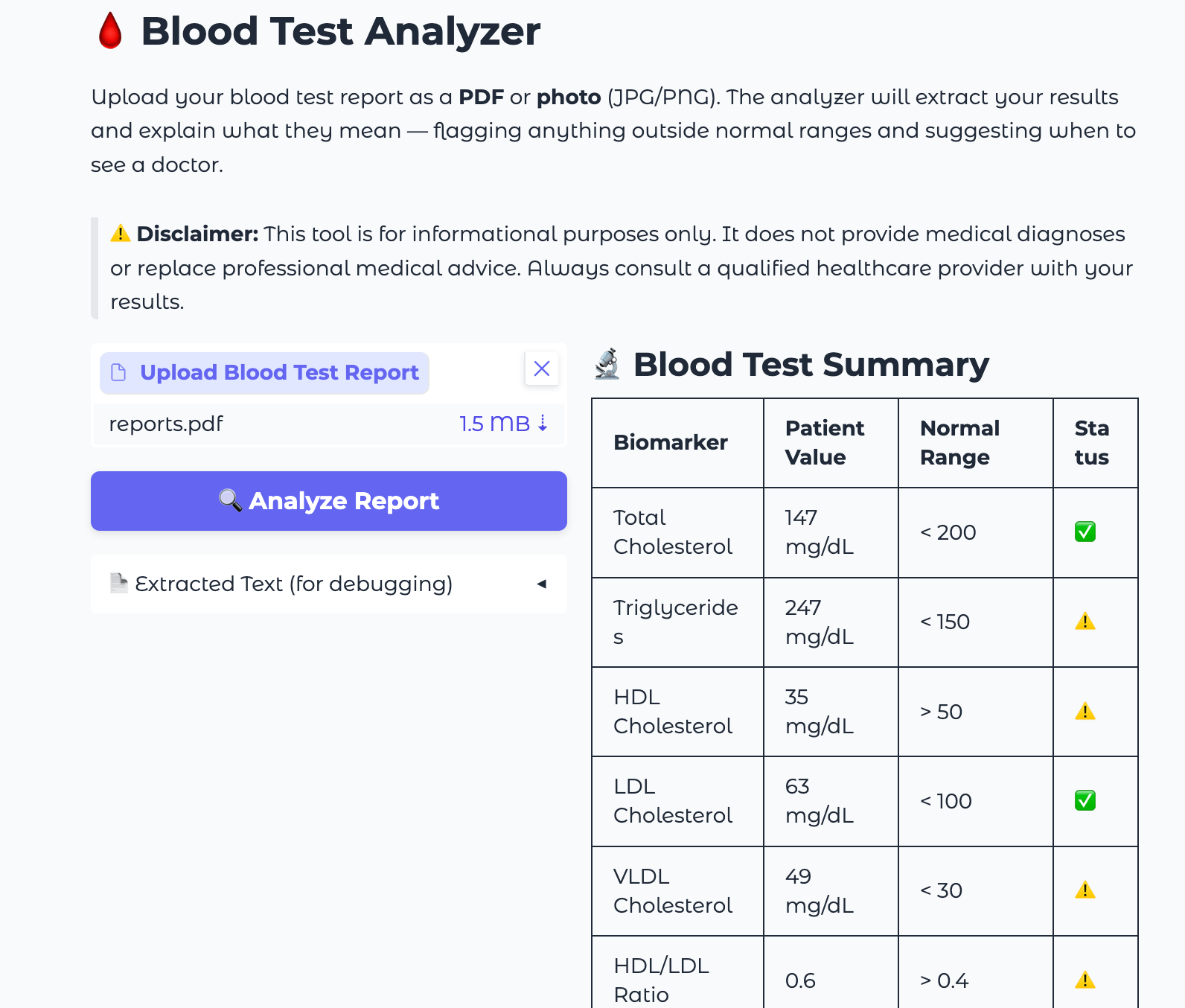
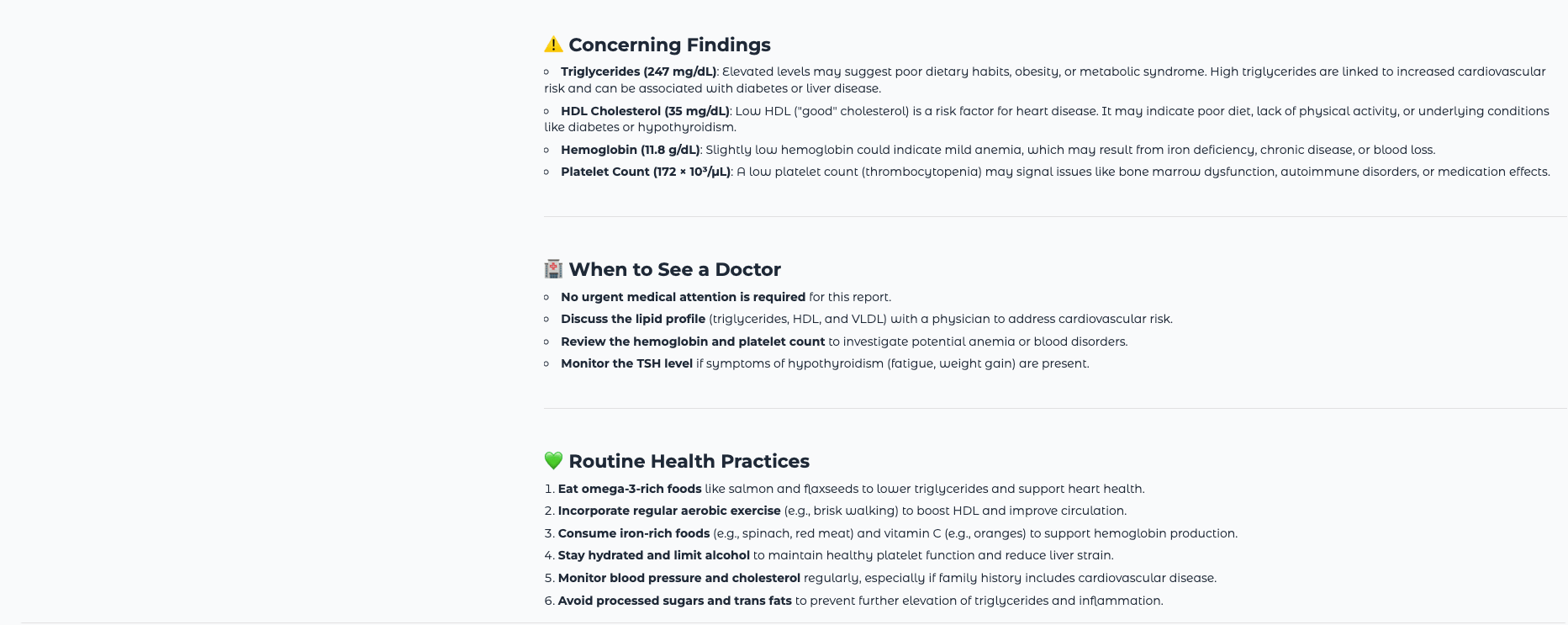
To trial the afloat pipeline, you tin create a elemental matter record pinch sample humor trial values and prevention it arsenic a PDF, aliases photograph a printed report. Use these sample values to verify the model’s output matches what you expect:
Hemoglobin: 9.1 g/dL WBC: 14500 /uL Platelets: 420000 /uLA correctly functioning researcher should emblem Hemoglobin arsenic importantly debased (🔴), WBC arsenic elevated (⚠️ to 🔴 depending connected the reference scope used), and Platelets arsenic mildly precocious (⚠️), explicate what each of these means, urge expert follow-up, and propose applicable practices for illustration iron-rich foods and hydration.
If the extracted matter accordion shows garbled output for an image upload, cheque that Tesseract is installed correctly (tesseract --version successful your terminal) and that the image is well-lit and not blurry. OCR useful champion connected images that are astatine slightest 300 DPI balanced solution and captured straight-on alternatively than astatine an angle.
Step 7 — Deploy to DigitalOcean
Once your exertion is ready, you tin deploy it connected DigitalOcean to create a production-ready situation for analyzing humor trial reports. Using Dedicated Inference ensures that delicate health-related information is processed connected dedicated compute resources alternatively than a shared conclusion pool. Combined pinch backstage networking and predictable performance, this makes it a beardown prime for applications that grip individual aesculapian information.
To deploy the application:
- Push your codification to a GitHub repository.
- Create a caller App Platform exertion and link your repository.
- Configure the required situation variables, including your Dedicated Inference endpoint and API credentials.
- Deploy the exertion and verify that record uploads and study study are functioning correctly.
- (Optional) Connect a civilization domain and alteration HTTPS for a production-ready personification experience.
To understand the step-by-step procedure, consciousness free to cheque retired the elaborate article connected Build and Deploy Apps connected DigitalOcean App Platform pinch Custom Domain.
With the exertion deployed, users tin securely upload humor trial reports, extract cardinal wellness metrics, and person AI-powered insights wrong minutes.
FAQs
1. What is DigitalOcean Dedicated Inference?
DigitalOcean Dedicated Inference is simply a managed work that allows you to deploy and service AI models connected dedicated GPU infrastructure. Unlike shared conclusion services, the GPU resources are reserved for your workload, providing predictable performance, greater control, and improved privacy.
2. Why usage Dedicated Inference alternatively of Serverless Inference?
Dedicated Inference is simply a amended prime erstwhile you person accordant conclusion traffic, request predictable latency, require dedicated GPU resources, aliases must meet privateness and compliance requirements. Serverless Inference is often much suitable for adaptable aliases low-volume workloads.
3. Why was Qwen3-8B chosen for this project?
Qwen3-8B offers a beardown equilibrium betwixt exemplary value and deployment cost. It tin understand and analyse aesculapian study matter efficaciously while remaining businesslike capable for accumulation deployments connected dedicated GPU infrastructure.
4. Can the exertion analyse some PDFs and images?
Yes. The exertion supports PDF files and image uploads. PDF matter is extracted utilizing pdfplumber, while image-based reports are processed utilizing Tesseract OCR earlier being sent to the connection exemplary for analysis.
5. Is diligent information sent complete the nationalist internet?
If the exertion and Dedicated Inference endpoint are deployed wrong the aforesaid VPC and usage backstage networking, the information tin stay wrong the backstage network, reducing vulnerability to the nationalist internet.
6. Can I usage a different connection model?
Yes. Dedicated Inference supports importing your ain models from Hugging Face repositories aliases DigitalOcean Spaces. You tin switch Qwen3-8B pinch different compatible exemplary based connected your requirements.
7. Is this exertion intended to switch aesculapian professionals?
No. The exertion is designed to thief users amended understand their reports by generating simplified explanations. It should not beryllium considered a substitute for master aesculapian advice, diagnosis, aliases treatment.
8. How tin this task beryllium extended?
You tin adhd support for further aesculapian documents, merge diligent history, build inclination study crossed aggregate reports, instrumentality authentication, shop reports successful a database, aliases create a conversational wellness adjunct for follow-up questions.
Conclusion
Pat yourself connected the back! You person successfully built a complete aesculapian study analyzer. The exertion accepts humor trial PDFs and images, extracts matter utilizing pdfplumber and Tesseract OCR, and sends the extracted contented to a Qwen3-8B exemplary moving connected DigitalOcean Dedicated Inference to make an easy-to-understand study of the results.
This is conscionable the beginning. You tin further heighten the exertion by adding support for further aesculapian documents, integrating diligent history for much personalized insights, implementing personification authentication, storing reports successful a database, generating inclination study crossed aggregate reports, and moreover building a conversational adjunct that allows users to inquire follow-up questions astir their wellness data. With Dedicated Inference providing accordant capacity and greater power complete delicate data, you person a coagulated instauration for building much precocious healthcare AI applications.
The exemplary returns a system four-section study that explains flagged values successful plain language, assesses urgency, and suggests actionable wellness practices.
Local matter extraction intends the record itself ne'er leaves the user’s session, but only the extracted matter goes to the conclusion endpoint. A system strategy punctual pinch definitive information guardrails ensures the model’s output is consistently formatted and ne'er oversteps into test territory. Low-temperature procreation keeps that output predictable crossed requests. And Dedicated Inference intends the full study pipeline runs connected infrastructure you own, pinch information isolation guaranteed by architecture alternatively than policy.
From here, location are a fewer further steps that tin beryllium taken to return this app to the adjacent level. One of them is swapping successful a imagination model, Qwen3-VL, for example, would fto the app skip OCR wholly and process image reports natively, which improves accuracy connected low-quality scans. Adding a history sheet truthful users tin comparison reports crossed aggregate dates would move a one-off study instrumentality into thing genuinely useful for search wellness trends complete time. Adding authentication earlier deploying to existent users is the correct measurement earlier this touches anyone’s existent wellness data.
Learn More
- Dedicated Inference: Technical Deep Dive
- Gradio documentation
- vLLM documentation
- pdfplumber connected GitHub
- Tesseract OCR
 This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.



")









![Convince Your Boss To Send You To Mozcon 2026 [plus Bonus Letter Template]](https://moz.com/images/blog/Blog-OG-images/Convince-Your-Boss-to-Send-You-to-MozCon-OG-Image-3.png?w=1200&h=630&q=82&auto=format&fit=clip&dm=1751528541&s=53746c4b2d83c4c442cb78b9ca076247 "Convince Your Boss To Send You To Mozcon 2026 [plus Bonus Letter Template]")
") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·