Introduction
A solo LegalTech laminitis has 10,000+ soul lawsuit files. The merchandise needs an AI adjunct that returns grounded answers pinch root references. The laminitis does not want to run a vector database, an embedding service, aliases a reranker connected time one.
DigitalOcean Knowledge Bases is simply a managed RAG pipeline. You constituent astatine files successful Spaces, and the level handles chunking, embedding, and retention successful Managed OpenSearch. Retrieval is exposed arsenic an MCP instrumentality astatine https://kbaas.do-ai.run/v1/mcp, truthful supplier frameworks telephone 1 usability alternatively of wiring 5 services.
This tutorial differs from older RAG walkthroughs that combine LangChain + Chroma yourself. Here you usage DigitalOcean autochthonal infrastructure only: Spaces, Knowledge Bases, MCP, Serverless Inference, and a mini FastAPI work you deploy to App Platform.
Key takeaways
- Knowledge Bases indexes PDF, Markdown, HTML, and 15+ matter formats from Spaces buckets without you moving vector infrastructure.
- The Knowledge Bases MCP endpoint exposes retrieve_knowledge_base for hybrid hunt pinch 1 to 25 results per call.
- MCP retrieval billing matches the Knowledge Base retrieve API: you salary embedding tokens for query vectorization positive optional reranking tokens.
- Answer procreation is separate. Your FastAPI work bills Serverless Inference per token (for example, Claude Sonnet 4.6 astatine $3.00 per 1M input tokens and $15.00 per 1M output tokens for prompts up to 200K tokens).
- Agent creation connected the Agent Platform is free. You salary for exemplary usage, indexing, storage, and retrieval.
- For accumulation LegalTech workloads, commencement successful TOR1. Most Agent Platform infrastructure runs location per Knowledge Base docs.
When to usage Knowledge Bases + MCP and erstwhile not to
| Static aliases semi-static archive corpora (case files, manuals, policies) | Live transactional information (CRM rows, summons state) |
| You want hybrid semantic + keyword retrieval pinch optional reranking | You only request a azygous API telephone pinch nary archive grounding |
| You want MCP-standard instrumentality entree for Cursor, LangChain, aliases civilization agents | You request sub-10ms retrieval astatine monolithic QPS connected civilization hardware |
| You want managed OpenSearch and Spaces storage | You must tally a self-hosted vector DB for argumentation reasons |
| Prototype to accumulation connected 1 cloud | You already run a mature RAG stack you for illustration to keep |
For the RAG vs MCP determination character astatine the shape level, spot Guide to RAG and MCP. This tutorial uses RAG for archive grounding and MCP arsenic the instrumentality transport.
Prerequisites
Before you start, corroborate you have:
- A DigitalOcean account.
- Inference and Agent Platform entree successful the Control Panel.
- A personal entree token pinch GenAI:read for retrieval and MCP, positive genai CRUD scopes to create the Knowledge Base via API.
- A Model Access Key from INFERENCE → Serverless Inference → Model Access Keys, aliases a individual entree token pinch Serverless Inference entree (some accounts tin usage the aforesaid PAT arsenic MODEL_ACCESS_KEY erstwhile dedicated exemplary keys are unavailable).
- Knowledge Base Enhancements preview enabled for precocious chunking and the retrieve endpoint (recommended).
- Python 3.10+ and doctl for section testing and App Platform deploy.
Lab tip: Use a sandbox project. Do not upload existent customer PII for this walkthrough. The sample files successful this repo are fictional.
Note: You tin besides usage the DigitalOcean Launch Pad successful the Control Panel to deploy this RAG Agent nether the RAG Assistant Starter Kit. It follows the aforesaid steps that we travel successful this tutorial. But for easiness of knowing and learning, we will beryllium deploying everything manually.

A speedy representation of terms
| RAG | Retrieve applicable archive chunks, past inquire the LLM to reply utilizing those chunks |
| Knowledge Base | Managed scale complete your files aliases URLs |
| MCP | A modular measurement for an LLM supplier to telephone devices for illustration retrieve_knowledge_base |
| Spaces | S3-compatible entity retention for your earthy lawsuit files |
| Serverless Inference | Pay-per-token entree to catalog models (Claude, Llama, and others) |
| FastAPI service | Your serve.py app: GET /health, POST /run pinch {"prompt": "..."} |
| App Platform | Managed hosting for the FastAPI instrumentality aliases Python buildpack |
| Reranking | Reorders retrieved chunks truthful the champion passages emergence to the top |
| alpha | Retrieval knob: 0 keyword, 1 semantic, 0.5 hybrid (default) |
What is RAG?
Retrieval-Augmented Generation (RAG) intends the LLM does not reply from representation alone. Your app first finds applicable passages from your ain documents, past asks the exemplary to reply utilizing only that material. That keeps answers grounded successful lawsuit files, policies, aliases manuals alternatively of wide training data.
Think of it for illustration an open-book exam: the exemplary gets the mobility positive the correct pages from your library, past writes the reply pinch citations.
The pipeline has 4 phases. The sketch beneath shows really they link successful this tutorial:
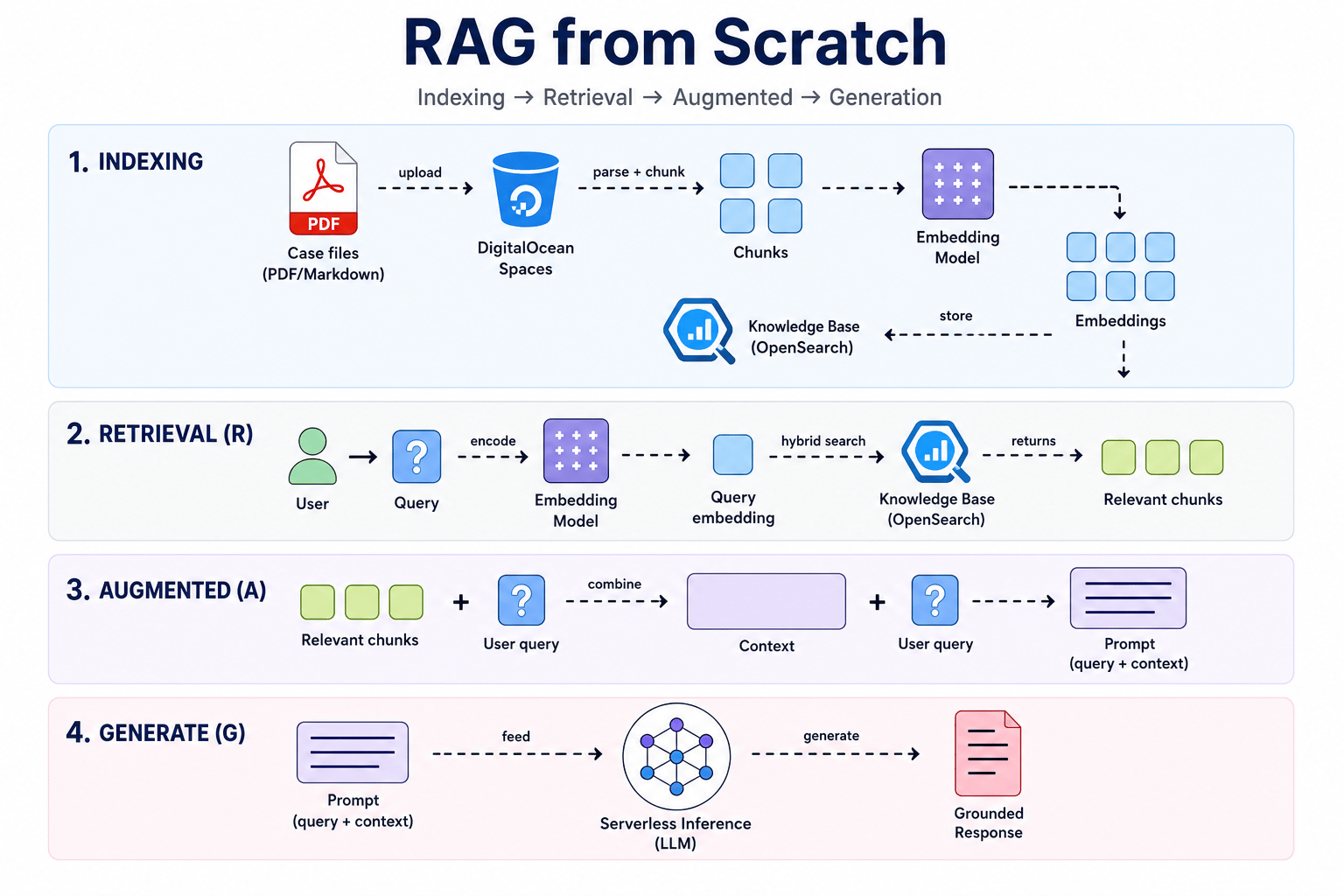
You tin publication much astir What is Retrieval Augmented Generation (RAG).
What you will build
sample lawsuit files (Markdown/PDF) | v DigitalOcean Spaces bucket | v Knowledge Base (chunk + embed + OpenSearch) | +-----+-----+ | | v v MCP retrieve REST retrieve (production default) https://kbaas.do-ai.run/v1/mcp | v FastAPI RAG work + Serverless Inference (Claude Sonnet aliases Llama) | v App Platform HTTPS URL for accumulation queriesBy the extremity you will have:
- A Spaces bucket pinch fictional LegalTech lawsuit files.
- A Knowledge Base pinch indexed chunks fresh for retrieval.
- A moving MCP retrieval telephone against retrieve_knowledge_base.
- A FastAPI work (serve.py + rag_core.py) that retrieves from the Knowledge Base and answers done Serverless Inference.
- A section POST /run endpoint tested pinch curl.
- The aforesaid work deployed connected App Platform pinch a nationalist HTTPS URL.
How to usage this tutorial
- Start pinch SETUP.md successful this files for a numbered book pipeline you tally transcript by copy.
- Copy config.env.example to config.env earlier immoderate script. Never perpetrate config.env.
- Wait for indexing to decorativeness earlier MCP tests. Provisioning often takes 5 minutes aliases longer per Knowledge Base docs.
- Run test_mcp_retrieval.sh earlier you commencement the FastAPI service. Retrieval must activity first.
- If you already person a Knowledge Base, commencement astatine Step 3.
Repo layout
Zero-Infrastructure RAG Agent/ ├── SETUP.md # Numbered runbook (start here) ├── config.env.example # Copy to config.env ├── sample-case-files/ # Fictional LegalTech Markdown files ├── scripts/ │ ├── 01_discover_prerequisites.py # List task UUID, models, VPCs │ ├── 02_upload_to_spaces.py # Upload sample files to Spaces │ ├── 03_create_knowledge_base.py # Create KB via API │ ├── 04_wait_for_indexing.py # Poll until indexing completes │ ├── 05_test_retrieve_api.sh # REST retrieval fume test │ └── run_all.sh # Run steps 01-06 successful order ├── .do/app.yaml # App Platform spec (Python buildpack) └── legaltech-rag-agent/ ├── rag_core.py # Retrieval + Serverless Inference logic ├── serve.py # FastAPI app (local + App Platform) ├── requirements-serve.txt # FastAPI dependencies └── test_mcp_retrieval.sh # MCP retrieval fume testAlso I person created a Github repo for this tutorial: Zero-Infrastructure RAG Agent which you tin clone and travel the steps successful the README.md file.
The six steps astatine a glance
| 0 | Configure secrets | cp config.env.example config.env |
| 1 | Stage lawsuit files successful Spaces | python3 scripts/02_upload_to_spaces.py |
| 2 | Create and scale a Knowledge Base | python3 scripts/03_create_knowledge_base.py |
| 3 | Test MCP retrieval | ./legaltech-rag-agent/test_mcp_retrieval.sh |
| 4 | Build the FastAPI RAG service | legaltech-rag-agent/serve.py + rag_core.py |
| 5 | Point the work astatine Serverless Inference | .env + exemplary entree key |
| 6 | Run locally and deploy | uvicorn serve:app → ./scripts/deploy_app_platform.sh |
Step 0: Configure your situation file
Every book successful this tutorial sounds from 1 record truthful you do not pursuit variables crossed terminals.
1. Copy the template:
cd "Zero-Infrastructure RAG Agent" cp config.env.example config.env2. Open config.env and group these values:
| DIGITALOCEAN_API_TOKEN | API Tokens pinch genai + GenAI:read |
| DO_PROJECT_ID | Output of 01_discover_prerequisites.sh (default task UUID) |
| SPACES_ACCESS_KEY_ID | Control Panel → Spaces → Access Keys, aliases MCP spaces-key-create |
| SPACES_SECRET_ACCESS_KEY | Shown erstwhile once you create the Spaces key |
| MODEL_ACCESS_KEY | INFERENCE → Serverless Inference → Model Access Keys |
Example for really to capable successful your config.env file:
# DigitalOcean API Token (required for managing resources) DIGITALOCEAN_API_TOKEN=your_do_api_token_here # Project UUID (from the prerequisites book output) DO_PROJECT_ID=your_project_uuid_here # Spaces Object Storage Access Keys SPACES_ACCESS_KEY_ID=your_spaces_access_key_id_here SPACES_SECRET_ACCESS_KEY=your_spaces_secret_access_key_here # Serverless Inference Model Access Key MODEL_ACCESS_KEY=your_model_access_key_here- Copy and capable successful each values.
- Never perpetrate this record to git aliases stock its contents.
3. Load the record earlier each step:
source config.envThe template already includes verified defaults for this lab:
- EMBEDDING_MODEL_UUID=22652c2a-79ed-11ef-bf8f-4e013e2ddde4 (All MiniLM L6 v2)
- VPC_UUID=db9169a0-e935-4329-9add-3ee52359105a (default-tor1)
- KB_REGION=tor1
4. Discover your task UUID:
chmod +x scripts/*.sh legaltech-rag-agent/test_mcp_retrieval.sh ./scripts/01_discover_prerequisites.shCopy the default task UUID into DO_PROJECT_ID successful config.env.
Step 1: Upload lawsuit files to a Spaces bucket
Your earthy files unrecorded successful DigitalOcean Spaces. The Knowledge Base pulls from the bucket and indexes supported formats (.md, .pdf, .html, .docx, and others listed successful the Knowledge Base docs).
Prepare sample files for the lab
This tutorial includes 4 fictional Markdown files nether sample-case-files/:
- case-2024-0142-nda-breach.md
- case-2023-0891-employment.md
- case-2024-0310-ip-licensing.md
- firm-retrieval-policy.md
For a 10,000-file accumulation corpus, the aforesaid shape applies. Organize 1 bucket per customer aliases per matter class. The docs urge 5 aliases less buckets per knowledge guidelines for indexing performance.
Create a Spaces bucket
- Open the Control Panel → Spaces Object Storage → Create Bucket.
- Choose a region. Use TOR1 if you scheme to connect agents successful Agent Platform.
- Name the bucket legaltech-casefiles-tutorial (or your ain name).
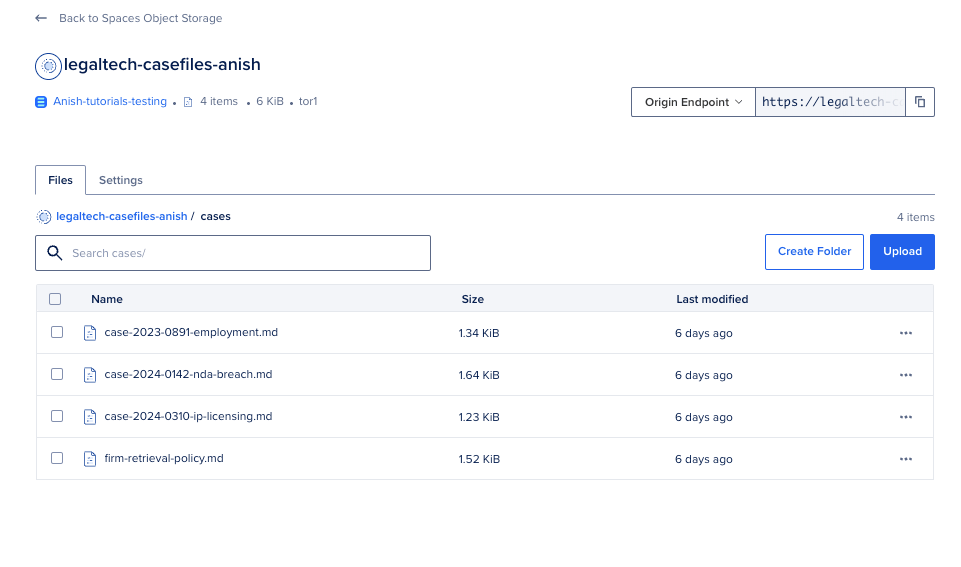
- Upload the sample files from sample-case-files/.
Upload pinch the included Python script
1. Install the upload dependency:
pip install -r scripts/requirements.txt2. Run the upload script:
source config.env python3 scripts/02_upload_to_spaces.pyYou tin entree the 02_upload_to_spaces.py record successful the legaltech-rag-agent folder.
What this book does: It connects to Spaces pinch your S3-compatible keys, creates the bucket if missing, and uploads each 4 .md files nether cases/.
Expected output:
Bucket exists: legaltech-casefiles-tutorial Uploading 4 files to s3://legaltech-casefiles-tutorial/cases/ uploaded cases/case-2024-0142-nda-breach.md uploaded cases/case-2023-0891-employment.md uploaded cases/case-2024-0310-ip-licensing.md uploaded cases/firm-retrieval-policy.md Upload complete.Each record upload is simply a plain copy. No embedding happens until Step 2.
Verify pinch DigitalOcean MCP
If you usage the DigitalOcean MCP server successful Cursor, database Spaces entree keys pinch spaces-key-list. Create a dedicated cardinal pinch spaces-key-create if you request programmatic upload access.
Step 2: Create a Knowledge Base via API
Now you move the bucket into a searchable index. This tutorial uses the DigitalOcean AI Platform API truthful each measurement is reproducible from your terminal.
What gets created
The API telephone provisions:
- A Knowledge Base named legaltech-cases-kb
- A caller OpenSearch database (auto-sized) successful TOR1
- An indexing occupation complete your Spaces bucket
- Optional reranking pinch bge-reranker-v2-m3
Choose an embeddings model
You cannot alteration the embeddings exemplary aft creation.
| All MiniLM L6 v2 (lab default) | 22652c2a-79ed-11ef-bf8f-4e013e2ddde4 | $0.009 per 1M tokens |
| GTE Large EN v1.5 | 22653204-79ed-11ef-bf8f-4e013e2ddde4 | $0.09 per 1M tokens |
| Bge M3 | 78836a83-26d0-11f1-b074-4e013e2ddde4 | $0.02 per 1M tokens |
List models yourself:
source config.env curl -sS "https://api.digitalocean.com/v2/gen-ai/models?usecases=MODEL_USECASE_KNOWLEDGEBASE" \ -H "Authorization: Bearer $DIGITALOCEAN_API_TOKEN" | python3 -m json.tool { "models": [ { "uuid": "22652c2a-79ed-11ef-bf8f-4e013e2ddde4", "name": "All MiniLM L6 v2" } ] } ### Create the Knowledge Base **1. Run the create script:** ```bash source config.env python3 scripts/03_create_knowledge_base.pyWhat this book does: It sends POST https://api.digitalocean.com/v2/gen-ai/knowledge_bases pinch your Spaces bucket arsenic a information source, section-based chunking, and reranking enabled. On success, it writes KNOWLEDGE_BASE_ID into config.env.
2. Inspect the JSON payload (for learning):
The book sends a assemblage balanced to:
{ "name": "legaltech-cases-kb", "embedding_model_uuid": "22652c2a-79ed-11ef-bf8f-4e013e2ddde4", "project_id": "YOUR_DO_PROJECT_ID", "region": "tor1", "vpc_uuid": "db9169a0-e935-4329-9add-3ee52359105a", "tags": ["legaltech-tutorial"], "datasources": [ { "spaces_data_source": { "bucket_name": "legaltech-casefiles-tutorial", "region": "tor1" }, "chunking_algorithm": "CHUNKING_ALGORITHM_SECTION_BASED", "chunking_options": { "max_chunk_size": 256 } } ], "reranking_config": { "enabled": true, "model": "bge-reranker-v2-m3" } }3. Expected output:
Knowledge guidelines created. ID: 123e4567-e89b-12d3-a456-426614174000 Name: legaltech-cases-kb Status: provisioning Saved KNOWLEDGE_BASE_ID to config.envReplace the illustration UUID pinch the worth from your account.
Alternative (curl only): If you for illustration ammunition complete Python for the create call:
source config.env ./scripts/03_create_knowledge_base_curl.shYou tin entree the 03_create_knowledge_base_curl.sh record successful the legaltech-rag-agent folder.
The curl book sounds payloads/create_knowledge_base.json, injects your DO_PROJECT_ID, and saves the returned UUID to config.env.
Wait for indexing
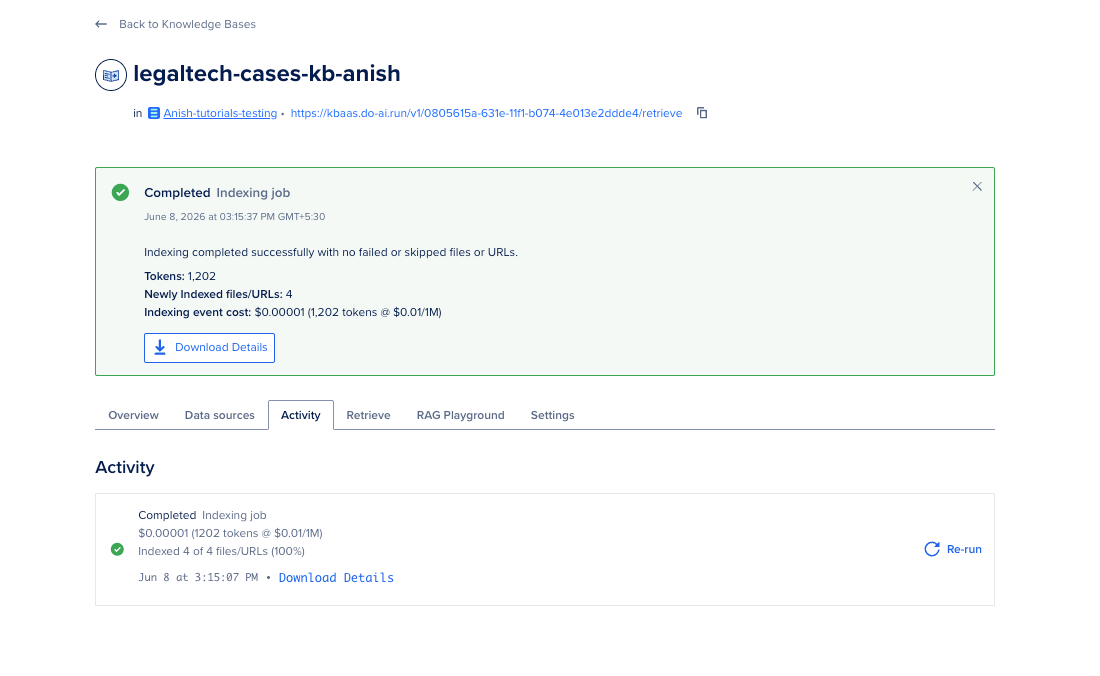
1. Poll until the knowledge guidelines is ready:
source config.env python3 scripts/04_wait_for_indexing.pyThe book checks position each 30 seconds for up to 45 minutes.
2. Confirm successful the Control Panel (optional):
Data Services → Knowledge bases → legaltech-cases-kb → Activity
Status values see Completed, Partially Completed, and Failed.
Test REST retrieval earlier MCP
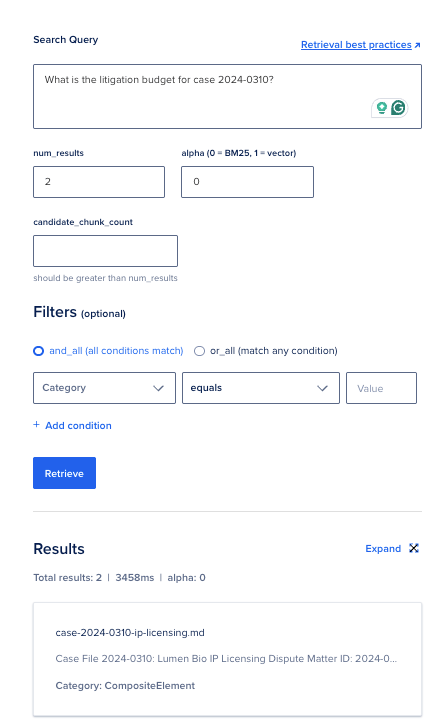
source config.env ./scripts/05_test_retrieve_api.shPass a civilization query:
./scripts/05_test_retrieve_api.sh "What is the litigation fund for lawsuit 2024-0310?"What a bully consequence looks like: JSON pinch total_results greater than zero and chunks that mention $320,000 aliases Lumen Bio.
Control Panel replacement (optional)
You tin besides create the knowledge guidelines manually utilizing the Control Panel. If you for illustration the UI, skip 03_create_knowledge_base.py and create the knowledge guidelines manually:
- Data Services → Knowledge bases → Create Knowledge Base
- Select an embeddings exemplary and optional reranking model
- Pull from a Spaces bucket aliases folder → prime legaltech-casefiles-tutorial
- Create new OpenSearch database successful TOR1
- Click Create knowledge base
Then transcript the UUID from:
https://cloud.digitalocean.com/agent-platform/knowledge-bases/{UUID}Add it to config.env:
export KNOWLEDGE_BASE_ID="your_uuid_here"List knowledge bases pinch the API:
curl -sS -X GET "https://api.digitalocean.com/v2/gen-ai/knowledge_bases" \ -H "Authorization: Bearer $DIGITALOCEAN_API_TOKEN" | python3 -m json.toolYou tin besides tally the query from the Control Panel:

You will get the pursuing output:
You tin grow the results:

Step 3: Enable MCP integration and trial retrieval
Knowledge Bases exposes retrieval done a dedicated MCP server. This endpoint is abstracted from the wide DigitalOcean MCP servers (Droplets, Apps, and truthful on). The URL is:
https://kbaas.do-ai.run/v1/mcpAuth requires a individual entree token pinch GenAI:read scope. Retrieval done MCP is billed the aforesaid arsenic nonstop retrieve API calls per pricing docs.
Supported MCP tool
| retrieve_knowledge_base | Hybrid hunt complete 1 knowledge base, 1 to 25 results |
Arguments:
- knowledge_base_id (required): your UUID
- query (required): lawyer mobility text
- num_results (required): 1 to 25
- alpha (optional): 0.5 default hybrid
- filters (optional): metadata filters connected item_name, page_number, and different fields
Full reference: Knowledge Bases MCP Tools.
Configure MCP successful Cursor (optional)
Add this artifact to your MCP customer config per Configure Remote MCP:
{ "mcpServers": { "knowledge-bases": { "url": "https://kbaas.do-ai.run/v1/mcp", "headers": { "Authorization": "Bearer <your_api_token_with_genai_read>" } } } }Smoke trial pinch the included ammunition script
From legaltech-rag-agent/:
export DIGITALOCEAN_API_TOKEN="your_token" export KNOWLEDGE_BASE_ID="your_kb_uuid" ./test_mcp_retrieval.shHere is the expected output:
Initializing MCP session... event: message data: {"jsonrpc":"2.0","id":1,"result":{"capabilities":{"logging":{},"tools":{"listChanged":true}},"instructions":"DigitalOcean Knowledge Bases MCP server. Use the retrieve_knowledge_base instrumentality to hunt knowledge bases by UUID.","protocolVersion":"2025-03-26","serverInfo":{"name":"digitalocean-knowledge-bases","version":"1.0.0"}}} Calling retrieve_knowledge_base... event: message data: {"jsonrpc":"2.0","id":2,"result":{"content":[{"type":"text","text":"Found 3 result(s):\n\n--- Result 1 ---\nCase File 2024-0142: Meridian Analytics NDA Breach\n\nMatter ID: 2024-0142 Client: Northwind Logistics LLC Opposing Party: Meridian Analytics Inc. Jurisdiction: Delaware Chancery Court Filed: 2024-03-18 Status: Discovery\n\nSummary\n\nNorthwind Logistics alleges Meridian Analytics disclosed confidential pricing models and customer pipeline information to a competitor aft signing a communal NDA connected 2023-11-02.\nMetadata: map[chunk_category:CompositeElement ingested_timestamp:2026-06-08T09:45:23.292831+00:00 item_name:case-2024-0142-nda-breach.md page_number:\u003cnil\u003e]\n\n--- Result 2 ---\nSolo Founders Legal AI Retrieval Policy\n\nEffective: 2024-06-01 Owner: Founding partner Applies to: Internal lawsuit investigation assistant\n\nPurpose\n\nThis argumentation defines really the firm's AI adjunct retrieves answers from soul lawsuit files stored successful DigitalOcean Knowledge Bases.\n\nAllowed Uses\n\nSummarize matter position for attorneys assigned to the matter.\n\nSurface procedural deadlines from indexed lawsuit files.\n\nDraft soul investigation memos pinch root citations.\n\nProhibited Uses\n\nDo not usage the adjunct for client-facing proposal without lawyer review.\n\nDo not query crossed matters without definitive matter ID successful the prompt.\n\nDo not upload customer PII to non-production workspaces.\nMetadata: map[chunk_category:CompositeElement ingested_timestamp:2026-06-08T09:45:24.015805+00:00 item_name:firm-retrieval-policy.md page_number:\u003cnil\u003e]\n\n--- Result 3 ---\nClaims\n\nCalifornia Labor Code retaliation (whistleblower).\n\nFEHA retaliation.\n\nBreach of implied covenant of bully faith.\n\nDamages Sought\n\nLost wages and benefits: $410,000 done proceedings date.\n\nEmotional distress: $150,000.\n\nPunitive damages requested if malice shown.\n\nDiscovery Status\n\nReceived unit record 2024-01-05.\n\nPending IT logs for morals portal submission timestamp.\n\nDeposition of HR head Denise Park group for 2024-08-14.\n\nSettlement Range (Internal)\n\nMediator little suggests opening request $650,000, expected bracket $275,000 to $425,000. Privileged.\nMetadata: map[chunk_category:CompositeElement ingested_timestamp:2026-06-08T09:45:19.820378+00:00 item_name:case-2023-0891-employment.md page_number:\u003cnil\u003e]\n\n"}],"structuredContent":{"results":[{"metadata":{"chunk_category":"CompositeElement","ingested_timestamp":"2026-06-08T09:45:23.292831+00:00","item_name":"case-2024-0142-nda-breach.md","page_number":null},"text_content":"Case File 2024-0142: Meridian Analytics NDA Breach\n\nMatter ID: 2024-0142 Client: Northwind Logistics LLC Opposing Party: Meridian Analytics Inc. Jurisdiction: Delaware Chancery Court Filed: 2024-03-18 Status: Discovery\n\nSummary\n\nNorthwind Logistics alleges Meridian Analytics disclosed confidential pricing models and customer pipeline information to a competitor aft signing a communal NDA connected 2023-11-02."},{"metadata":{"chunk_category":"CompositeElement","ingested_timestamp":"2026-06-08T09:45:24.015805+00:00","item_name":"firm-retrieval-policy.md","page_number":null},"text_content":"Solo Founders Legal AI Retrieval Policy\n\nEffective: 2024-06-01 Owner: Founding partner Applies to: Internal lawsuit investigation assistant\n\nPurpose\n\nThis argumentation defines really the firm's AI adjunct retrieves answers from soul lawsuit files stored successful DigitalOcean Knowledge Bases.\n\nAllowed Uses\n\nSummarize matter position for attorneys assigned to the matter.\n\nSurface procedural deadlines from indexed lawsuit files.\n\nDraft soul investigation memos pinch root citations.\n\nProhibited Uses\n\nDo not usage the adjunct for client-facing proposal without lawyer review.\n\nDo not query crossed matters without definitive matter ID successful the prompt.\n\nDo not upload customer PII to non-production workspaces."},{"metadata":{"chunk_category":"CompositeElement","ingested_timestamp":"2026-06-08T09:45:19.820378+00:00","item_name":"case-2023-0891-employment.md","page_number":null},"text_content":"Claims\n\nCalifornia Labor Code retaliation (whistleblower).\n\nFEHA retaliation.\n\nBreach of implied covenant of bully faith.\n\nDamages Sought\n\nLost wages and benefits: $410,000 done proceedings date.\n\nEmotional distress: $150,000.\n\nPunitive damages requested if malice shown.\n\nDiscovery Status\n\nReceived unit record 2024-01-05.\n\nPending IT logs for morals portal submission timestamp.\n\nDeposition of HR head Denise Park group for 2024-08-14.\n\nSettlement Range (Internal)\n\nMediator little suggests opening request $650,000, expected bracket $275,000 to $425,000. Privileged."}],"total_results":3}}}The book does 2 calls:
- initialize the MCP session.
- tools/call for retrieve_knowledge_base pinch the query What is the position of lawsuit 2024-0142?.
What a bully consequence looks like: JSON pinch total_results greater than zero and chunks mentioning matter 2024-0142 aliases the Meridian Analytics NDA breach summary. Each consequence should see text_content and metadata specified arsenic root aliases page.
If you spot zero results: Indexing is still running, the bucket way is wrong, aliases the query needs a little alpha for nonstop matter ID keyword matching. Check the Activity tab first. Try alpha: 0 for ID-heavy lookups.
Manual curl illustration (single call)
curl -sS -X POST "https://kbaas.do-ai.run/v1/mcp" \ -H "Content-Type: application/json" \ -H "Accept: application/json, text/event-stream" \ -H "Authorization: Bearer $DIGITALOCEAN_API_TOKEN" \ -d '{ "jsonrpc": "2.0", "id": 3, "method": "tools/call", "params": { "name": "retrieve_knowledge_base", "arguments": { "knowledge_base_id": "YOUR_KB_UUID", "query": "What damages are claimed successful lawsuit 2024-0142?", "num_results": 5, "alpha": 0.5 } } }' | sed -n 's/^data: //p' | jq '.result.structuredContent'One statement per root file:
curl -sS ... | sed -n 's/^data: //p' | jq '.result.structuredContent.results[] | {item_name: .metadata.item_name, text_content}' { "results": [ { "metadata": { "chunk_category": "CompositeElement", "ingested_timestamp": "2026-06-08T09:45:23.292831+00:00", "item_name": "case-2024-0142-nda-breach.md", "page_number": null }, "text_content": "Case File 2024-0142: Meridian Analytics NDA Breach\n\nMatter ID: 2024-0142 Client: Northwind Logistics LLC Opposing Party: Meridian Analytics Inc. Jurisdiction: Delaware Chancery Court Filed: 2024-03-18 Status: Discovery\n\nSummary\n\nNorthwind Logistics alleges Meridian Analytics disclosed confidential pricing models and customer pipeline information to a competitor aft signing a communal NDA connected 2023-11-02." }, { "metadata": { "chunk_category": "CompositeElement", "ingested_timestamp": "2026-06-08T09:45:23.292831+00:00", "item_name": "case-2024-0142-nda-breach.md", "page_number": null }, "text_content": "Key Facts\n\nNDA executed connected 2023-11-02 pinch a 24-month confidentiality term.\n\nJoint information play ran from 2023-11-15 done 2024-01-30.\n\nOn 2024-02-14, Northwind learned Meridian shared a descent platform containing Northwind portion economics pinch Apex Data Systems.\n\nThe descent platform filename was Northwind_Pricing_v3_confidential.pptx.\n\nMeridian worker Sarah Chen sent the record via individual Gmail connected 2024-02-09.\n\nDamages Claimed\n\nLost endeavor statement pinch Harbor Freight Group: $1.2M yearly value.\n\nRemediation and audit costs: $84,000.\n\nInjunctive alleviation requested to extremity further disclosure." }, { "metadata": { "chunk_category": "CompositeElement", "ingested_timestamp": "2026-06-08T09:45:24.015805+00:00", "item_name": "firm-retrieval-policy.md", "page_number": null }, "text_content": "Solo Founders Legal AI Retrieval Policy\n\nEffective: 2024-06-01 Owner: Founding partner Applies to: Internal lawsuit investigation assistant\n\nPurpose\n\nThis argumentation defines really the firm's AI adjunct retrieves answers from soul lawsuit files stored successful DigitalOcean Knowledge Bases.\n\nAllowed Uses\n\nSummarize matter position for attorneys assigned to the matter.\n\nSurface procedural deadlines from indexed lawsuit files.\n\nDraft soul investigation memos pinch root citations.\n\nProhibited Uses\n\nDo not usage the adjunct for client-facing proposal without lawyer review.\n\nDo not query crossed matters without definitive matter ID successful the prompt.\n\nDo not upload customer PII to non-production workspaces." }, { "metadata": { "chunk_category": "CompositeElement", "ingested_timestamp": "2026-06-08T09:45:23.656377+00:00", "item_name": "case-2024-0310-ip-licensing.md", "page_number": null }, "text_content": "Case File 2024-0310: Lumen Bio IP Licensing Dispute\n\nMatter ID: 2024-0310 Client: Lumen Bio Therapeutics Counterparty: Helix Research Partners Jurisdiction: SDNY Filed: 2024-05-03 Status: Motion to disregard pending\n\nSummary\n\nLumen Bio seeks declaratory judgement that its CRISPR transportation method does not infringe Helix Patent US-10,998,221 aft Helix sent a cease-and-desist missive connected 2024-04-11.\n\nPatent astatine Issue\n\nPatent: US-10,998,221\n\nTitle: Lipid nanoparticle formulations for guideline RNA delivery\n\nPriority date: 2017-06-14\n\nLumen Position\n\nLumen uses a chopped PEGylation ratio (8:1 vs Helix claimed 4:1).\n\nPrior creation reference WO2018/044112 anticipates claims 1-4.\n\nNo licensing statement exists betwixt parties." }, { "metadata": { "chunk_category": "CompositeElement", "ingested_timestamp": "2026-06-08T09:45:19.820378+00:00", "item_name": "case-2023-0891-employment.md", "page_number": null }, "text_content": "Claims\n\nCalifornia Labor Code retaliation (whistleblower).\n\nFEHA retaliation.\n\nBreach of implied covenant of bully faith.\n\nDamages Sought\n\nLost wages and benefits: $410,000 done proceedings date.\n\nEmotional distress: $150,000.\n\nPunitive damages requested if malice shown.\n\nDiscovery Status\n\nReceived unit record 2024-01-05.\n\nPending IT logs for morals portal submission timestamp.\n\nDeposition of HR head Denise Park group for 2024-08-14.\n\nSettlement Range (Internal)\n\nMediator little suggests opening request $650,000, expected bracket $275,000 to $425,000. Privileged." } ], "total_results": 5 }Filter retrieval to 1 lawsuit file
When an lawyer useful 1 matter, select by filename metadata:
{ "filters": { "equals": { "key": "item_name", "value": "case-2024-0142-nda-breach.md" } } }This shape mirrors the Retrieve tab filters successful the Control Panel described successful test knowledge guidelines retrieval docs.
Step 4: Build the FastAPI RAG service
With retrieval confirmed successful Step 3, ligament Knowledge Base retrieval and Serverless Inference into a mini FastAPI app. This is the work you tally locally and deploy to App Platform.
Understand the work flow
POST /run {"prompt": "..."} -> Knowledge Base retrieve (REST API by default) -> format chunks arsenic context -> Serverless Inference chat completion -> {"response": "...", "retrieval_preview": "..."}Step 3 proved MCP retrieval works. The hosted work uses the Knowledge Base retrieve REST API (RETRIEVAL_MODE=rest) because it is unchangeable successful production. Set RETRIEVAL_MODE=mcp only erstwhile you want to workout the MCP carrier from exertion code.
Core modules
| rag_core.py | Retrieval (retrieve_context_rest aliases retrieve_context_mcp), procreation (generate_answer), and run_rag() |
| serve.py | FastAPI app: GET /health, POST /run |
| requirements-serve.txt | FastAPI, uvicorn, httpx, LangChain clients |
1. Serverless Inference client (rag_core.py)
# This is an illustration of really the Serverless Inference customer is initialized successful your code. # You will find (or request to add) this codification wrong `rag_core.py`, which is located successful the `legaltech-rag-agent/` directory. # Look for a usability that sets up the connection exemplary customer (it whitethorn beryllium called wrong `generate_answer()` aliases similar). # Example usage successful rag_core.py: from langchain_openai import ChatOpenAI import os llm = ChatOpenAI( model=os.environ.get("INFERENCE_MODEL", "anthropic-claude-sonnet-4"), api_key=os.environ.get("MODEL_ACCESS_KEY"), base_url="https://inference.do-ai.run/v1", temperature=0.1, max_tokens=800, )Note: You do not tally this straight successful your terminal aliases a notebook. This Python codification is portion of the FastAPI backend—included (or to beryllium included) successful rag_core.py.
MODEL_ACCESS_KEY is the Serverless Inference credential. Prefer a dedicated cardinal from INFERENCE → Serverless Inference → Create a Model Access Key. If the model-key API is retired connected your account, a individual entree token pinch conclusion entree tin activity arsenic MODEL_ACCESS_KEY successful laboratory setups.
2. REST retrieval (production default)
await client.post( f"https://kbaas.do-ai.run/v1/{kb_id}/retrieve", headers={"Authorization": f"Bearer {token}", ...}, json={"query": query, "num_results": num_results, "alpha": alpha}, )3. FastAPI endpoints (serve.py)
@app.get("/health") async def health() -> dict[str, str]: return {"status": "ok"} @app.post("/run") async def run(body: RunRequest) -> dict[str, Any]: return await run_rag(body.prompt.strip())Your app calls POST /run pinch {"prompt": "your question"}. The consequence includes the grounded reply positive a truncated retrieval_preview for debugging.
Environment file
Copy .env.example to .env wrong legaltech-rag-agent/:
cd legaltech-rag-agent cp .env.example .envSet these values (copy KNOWLEDGE_BASE_ID and tokens from config.env):
MODEL_ACCESS_KEY=your_model_access_key DIGITALOCEAN_API_TOKEN=your_personal_access_token KNOWLEDGE_BASE_ID=your_knowledge_base_uuid INFERENCE_MODEL=anthropic-claude-sonnet-4 RETRIEVAL_MODE=rest NUM_RESULTS=5 RETRIEVAL_ALPHA=0.5.env is gitignored. Never perpetrate tokens.
Install limitations and tally locally
cd legaltech-rag-agent pip install -r requirements-serve.txt set -a && source .env && set +a uvicorn serve:app --host 0.0.0.0 --port 8080Sample startup:
INFO: Uvicorn moving connected http://0.0.0.0:8080 (Press CTRL+C to quit) INFO: Started server process INFO: Waiting for exertion startup. INFO: Application startup complete.Confirm health:
curl http://localhost:8080/health {"status":"ok"}Test pinch curl:
curl -X POST http://localhost:8080/run \ -H "Content-Type: application/json" \ -d '{"prompt": "Summarize lawsuit 2023-0891 and database the adjacent deposition date."}'Output for the curl bid above:
{ "response": "Based connected the retrieved lawsuit record discourse for Matter ID 2023-0891:\n\n## Case Summary - Matter ID 2023-0891\n\n• **Client**: Jordan Ellis vs. Vega Software Corp.\n• **Case Type**: Wrongful termination/retaliation claim\n• **Filed**: 2023-09-12 successful California Superior Court, San Francisco County\n• **Current Status**: Mediation scheduled\n\n## Key Facts\n• Ellis was a elder merchandise head hired 2021-04-19\n• Terminated 2023-08-30 (cited arsenic \"performance restructuring\")\n• Ellis revenge soul morals study connected 2023-07-22 regarding unlicensed encryption module shipments to UAE reseller program\n• Termination occurred 39 days aft whistleblower report\n• Severance offer: 8 weeks salary pinch wide release\n\n## Claims\n• California Labor Code retaliation (whistleblower)\n• FEHA retaliation\n• Breach of implied covenant of bully faith\n\n## Next Deposition Date\n• **HR Director Denise Park deposition scheduled for 2024-08-14**\n\n## Damages Sought\n• Lost wages/benefits: $410,000\n• Emotional distress: $150,000\n• Punitive damages if malice proven\n\n*Source: Matter ID 2023-0891, case-2023-0891-employment.md*", "retrieval_preview": "{\n \"results\": [\n {\n \"metadata\": {\n \"chunk_category\": \"CompositeElement\",\n \"ingested_timestamp\": \"2026-06-08T09:45:19.820378+00:00\",\n \"item_name\": \"case-2023-0891-employment.md\",\n \"page_number\": null\n },\n \"text_content\": \"Case File 2023-0891: Vega Software Wrongful Termination\\n\\nMatter ID: 2023-0891 Client: Jordan Ellis Employer: Vega Software Corp. ...\"\n }\n ]\n}", "knowledge_base_id": "0805615a-631e-11f1-b074-4e013e2ddde4", "model": "anthropic-claude-sonnet-4", "retrieval_mode": "rest" }Expected behavior: The consequence mentions Vega Software, Jordan Ellis, and the HR head deposition connected 2024-08-14 if those chunks classed highly.
Step 5: Point the supplier astatine a Serverless Inference model
Retrieval value and reply value are abstracted choices. You prime the conclusion exemplary for procreation here.
Note: you do not deploy a Serverless Inference instance
If you expected a caller GPU aliases conclusion app successful the Control Panel, that is normal confusion. Serverless Inference is not provisioned for illustration Dedicated Inference aliases App Platform.
| Spaces bucket, Knowledge Base, FastAPI connected App Platform | Serverless Inference astatine https://inference.do-ai.run/v1 |
On each POST /run, your FastAPI work runs 2 abstracted steps:
- Retrieve — Knowledge Base API (DIGITALOCEAN_API_TOKEN) finds applicable case-file chunks.
- Generate — Serverless Inference API (MODEL_ACCESS_KEY) turns those chunks positive the personification mobility into a natural-language answer.
DigitalOcean runs the shared exemplary fleet for each customers. You do not reserve a GPU hour. You create a Model Access Key, group INFERENCE_MODEL successful .env, and your codification calls the API erstwhile a personification asks a question. Billing is per token per Serverless Inference pricing.
In the Control Panel nether INFERENCE → Serverless Inference, you spot the model catalog and Model Access Keys, not a “Create instance” button. Token usage appears successful conclusion usage and billing aft your app calls inference.do-ai.run. Knowledge Base retrieval is billed separately (embedding and optional reranking tokens).
For dependable accumulation postulation connected a backstage GPU, spot Dedicated Inference. This tutorial uses Serverless because legal-research queries are bursty and pay-per-token is simpler for a first ship.
Choose a model
| Claude Sonnet 4.6 | $3.00 / $15.00 per 1M tokens (≤200K prompt) | Default for nuanced ineligible summaries |
| Llama 3.3 Instruct 70B | $0.65 / $0.65 per 1M tokens | Lower costs drafts and soul tools |
List models pinch the DigitalOcean MCP inference-model-catalog-search instrumentality aliases the Control Panel Model Catalog. During tutorial prep, a hunt for claude sonnet returned UUIDs for Anthropic Claude Sonnet 4 and related catalog entries.
Set the exemplary slug successful .env:
INFERENCE_MODEL=anthropic-claude-sonnet-4.6Create aliases transcript a Model Access Key
INFERENCE → Serverless Inference → Model Access Keys → Create Access Key
Export it for section runs:
export MODEL_ACCESS_KEY="your_key"Direct Serverless Inference fume trial (optional)
curl -X POST "https://inference.do-ai.run/v1/chat/completions" \ -H "Authorization: Bearer $MODEL_ACCESS_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "anthropic-claude-sonnet-4", "messages": [{"role": "user", "content": "Reply pinch READY"}], "max_tokens": 10 }'Sample output (dedicated Model Access Key from Control Panel):
{ "choices": [ { "finish_reason": "stop", "index": 0, "message": { "content": "READY", "role": "assistant" } } ], "model": "anthropic-claude-sonnet-4", "object": "chat.completion", "usage": { "completion_tokens": 5, "prompt_tokens": 11, "total_tokens": 16 } }If this fails pinch 401, hole the exemplary entree cardinal earlier debugging MCP.
Step 6: Deploy the FastAPI work to App Platform
Local uvicorn proves the RAG pipeline works. App Platform gives you a nationalist HTTPS URL your merchandise tin call.
Confirm section wellness first
With uvicorn still moving (or restart it from Step 4):
curl http://localhost:8080/health # {"status":"ok"}Deploy pinch the included script
The repo ships .do/app.yaml (Python buildpack, source_dir: legaltech-rag-agent) and scripts/deploy_app_platform.sh, which injects secrets from config.env and creates aliases updates the app.
1. Push the repo to GitHub (App Platform clones from git):
# One-time: create a nationalist repo and push (secrets enactment successful config.env, not Git) gh repo create legaltech-rag-agent --public --source=. --remote=origin --push2. Deploy:
source config.env ./scripts/deploy_app_platform.shThe book writes .do/app.deploy.yaml (gitignored), runs doctl apps create aliases doctl apps update, and prints the app URL.
Manual alternative:
source config.env # Edit .do/app.yaml: group KNOWLEDGE_BASE_ID and concealed placeholders, then: doctl apps create --spec .do/app.deploy.yaml --project-id "$DO_PROJECT_ID"Required runtime env vars connected App Platform:
| MODEL_ACCESS_KEY | Serverless Inference (secret) |
| DIGITALOCEAN_API_TOKEN | Knowledge Base retrieve API (secret) |
| KNOWLEDGE_BASE_ID | Your KB UUID |
| INFERENCE_MODEL | e.g. anthropic-claude-sonnet-4 |
| RETRIEVAL_MODE | rest for hosted deploy |
| NUM_RESULTS / RETRIEVAL_ALPHA | Retrieval tuning |
Test the unrecorded endpoint
Replace the big pinch your App Platform default ingress:
curl https://legaltech-rag-agent-jjd7r.ondigitalocean.app/health curl -X POST https://legaltech-rag-agent-jjd7r.ondigitalocean.app/run \ -H "Content-Type: application/json" \ -d '{"prompt": "What employment cases impact wrongful termination?"}' | jq .Sample wellness response:
{"status":"ok"}Output for the curl bid above:
{ "response": "Based connected the retrieved lawsuit files, I recovered 1 employment lawsuit involving wrongful termination:\n\n• **Matter ID 2023-0891** - Vega Software Wrongful Termination\n - Client: Jordan Ellis\n - Employer: Vega Software Corp.\n - Filed: 2023-09-12\n - Claims: California Labor Code retaliation (whistleblower), FEHA retaliation, and breach of implied covenant of bully faith\n - Allegation: Wrongful termination successful retaliation for reporting export power violations\n - Timeline: Ellis reported morals violations connected 2023-07-22, terminated connected 2023-08-30 (39 days later)\n - Status: Mediation scheduled\n\nThis is the only employment wrongful termination lawsuit coming successful the indexed worldly provided.", "retrieval_preview": "{\n \"results\": [\n {\n \"metadata\": {\n \"chunk_category\": \"CompositeElement\",\n \"ingested_timestamp\": \"2026-06-08T09:45:19.820378+00:00\",\n \"item_name\": \"case-2023-0891-employment.md\",\n \"page_number\": null\n },\n \"text_content\": \"Case File 2023-0891: Vega Software Wrongful Termination\\n\\nMatter ID: 2023-0891 Client: Jordan Ellis Employer: Vega Software Corp. Jurisdiction: California Superior Court, San Francisco County Filed: 2023-09-12 Status: Mediation scheduled\\n\\nSummary\\n\\nJordan Ellis, a elder merchandise manager, alleges wrongful termination successful retaliation for reporting export power violations related to Vega's UAE reseller program.\\n\\nKey Facts\\n\\nHire date: 2021-04-19.\\n\\nTermination date: 2023-08-30, cited arsenic \\\"performance restructuring.\\\"\\n\\nEllis submitted an soul morals study connected 2023-07-22 regarding unlicensed encryption module shipments.\\n\\nVega eliminated Ellis's domiciled 39 days aft the report.\\n\\nSeverance offer: 8 weeks salary pinch wide release.\"\n },\n {\n \"metadata\": {\n \"chunk_category\": \"CompositeElement\",\n \"ingested_timestamp\": \"2026-06-08T09:45:19.820378+00:00\",\n \"item_name\": \"case-2023-0891-e", "knowledge_base_id": "0805615a-631e-11f1-b074-4e013e2ddde4", "model": "anthropic-claude-sonnet-4", "retrieval_mode": "rest" }A successful deploy returns a grounded reply pinch matter IDs from your indexed lawsuit files.
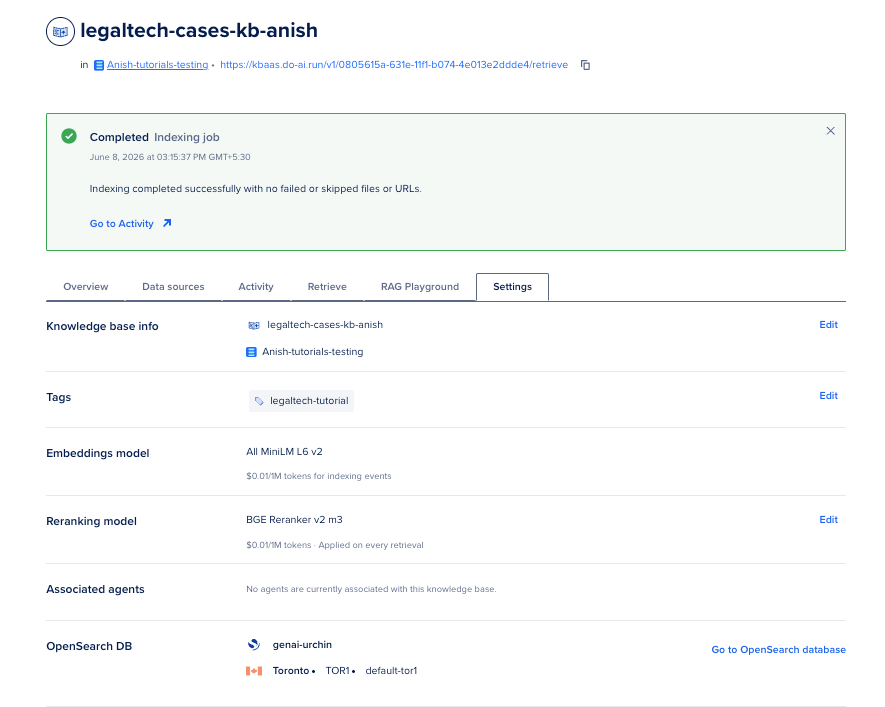
Tune reranking erstwhile precision is low
If answers mention the incorrect matter:
- Open the knowledge guidelines Settings tab successful the Control Panel.
- Confirm reranking is enabled pinch your chosen reranking model.
- Re-run the aforesaid query against POST /run and inspect retrieval_preview.
- Tighten prompts pinch definitive matter IDs.
- Add item_name filters successful rag_core.py for single-matter sessions.
You tin cheque retired the Reranking documentation for much details.
Observability
You tin observe the following:
- App Platform: Runtime logs nether Apps → your app → Runtime Logs.
- Retrieval debug: Each POST /run consequence includes retrieval_preview (first 1200 characters of retrieved JSON).
- Control Panel: Knowledge bases → Retrieve tab for one-off retrieval tests without hitting your app.
Cost sketch for a solo founder
These figures travel from DigitalOcean Inference pricing. Your invoice depends connected record size, query volume, and exemplary choice.
| Initial indexing | 10 MB corpus ≈ 3M tokens × $0.009/1M ≈ $0.03 pinch all-mini-lm-l6-v2 | Scales linearly pinch tokens |
| OpenSearch storage | Depends connected cluster size | See OpenSearch pricing |
| Retrieval query | 1 query vectorized per MCP call | Same value done MCP aliases REST |
| Reranking | Per reranking tokens erstwhile enabled | BGE Reranker v2 m3 astatine $0.01/1M tokens |
| Answer generation | 2K input + 500 output tokens connected Sonnet 4.6 ≈ $0.0135 per answer | (($3×2) + ($15×0.5)) / 1000 |
For 10,000 files, tally the indexing costs estimator successful the Control Panel during knowledge guidelines creation. The UI shows per-model token rates earlier you commit.
When things spell wrong
Here are immoderate communal issues and their solutions which I personally encountered while moving connected this application.
| MCP 401 | Token missing GenAI:read | Create a caller token pinch correct scope |
| retrieve_knowledge_base returns 0 chunks | Indexing incomplete aliases incorrect bucket | Check Activity tab, re-run indexing |
| Answers mention the incorrect matter | Hybrid hunt excessively broad | Lower temperature, adhd item_name filter, alteration reranking |
| App Platform build fails | Missing requirements-serve.txt aliases incorrect source_dir | Confirm .do/app.yaml points astatine legaltech-rag-agent |
| POST /run returns 500 connected App Platform | Missing env var | Set KNOWLEDGE_BASE_ID, MODEL_ACCESS_KEY, DIGITALOCEAN_API_TOKEN successful app spec |
| App wellness cheque fails | Service not listening connected larboard 8080 | http_port: 8080 and uvicorn ... --port 8080 must match |
| KB create 400 connected max_chunk_size | Value exceeds embedding exemplary limit | Use 256 for All MiniLM L6 v2 (not 500) |
| Model errors connected 401 | Confused API token vs exemplary entree key | Use MODEL_ACCESS_KEY for conclusion only |
| Slow first query | Cold scale aliases ample num_results | Start pinch num_results: 5, standard aft profiling |
| Upload stalls | Batch excessively large | Upload less than 100 files per batch nether 2 GB |
Cleanup (so laboratory walk stops)
- Delete the App Platform app: Apps → your app → Destroy.
- Delete the knowledge base: Knowledge bases → … → Destroy (destroys associated information sources and indexing).
- Delete the OpenSearch database if you created a dedicated 1 and nary longer request it.
- Delete the Spaces bucket erstwhile you nary longer request earthy files.
- Revoke tutorial API tokens and exemplary entree keys.
OpenSearch clusters and stored embeddings accrue costs while resources still exist. You tin delete them from the Control Panel.
FAQs
1. What is the quality betwixt Knowledge Bases MCP and the DigitalOcean MCP server?
The DigitalOcean MCP server manages DO infrastructure for illustration Droplets, Apps, and Spaces keys. The Knowledge Bases MCP endpoint astatine https://kbaas.do-ai.run/v1/mcp only exposes retrieval devices for indexed knowledge bases. You configure them separately.
2. Do I still request LangChain aliases Chroma if I usage Knowledge Bases?
No Chroma aliases self-hosted vector DB is required for this path. You still usage LangChain successful supplier codification if you want LangChain agents, but retrieval runs connected DigitalOcean managed OpenSearch done Knowledge Bases.
3. How does MCP billing activity for retrieval?
Retrieval done MCP is billed the aforesaid arsenic the retrieve API, including query vectorization tokens and optional reranking tokens per Knowledge Base pricing.
4. When should I alteration reranking?
Enable reranking erstwhile callback looks bully but classed bid is wrong, which is communal erstwhile matter titles and statement names overlap. You salary other reranking tokens connected each retrieval call.
5. Can I usage Dedicated Inference alternatively of Serverless?
Yes for reply procreation if you request a backstage GPU endpoint. Knowledge Base retrieval stays connected the managed Knowledge Bases service. Many solo founders commencement connected Serverless ($3.00 per 1M input tokens for Claude Sonnet 4.6) and move procreation to Dedicated erstwhile postulation steadies. See Serverless vs Dedicated.
6. How do I crushed answers crossed 10,000+ files without blowing token budgets?
Keep num_results betwixt 5 and 8, select by item_name erstwhile the matter is known, and usage reranking alternatively of sending 25 ample chunks each call. Test prompts against section POST /run earlier you vessel accumulation defaults.
Conclusion
Congratulations connected building your ain RAG Agent pinch DigitalOcean Knowledge Bases and Serverless Inference! If you’ve followed along, you now cognize really to deploy your supplier to App Platform, trial its endpoints, and troubleshoot communal issues.
When I first stitched together my ain RAG pipeline, having the correct building blocks and clear steps made each the quality and hopefully, this tutorial helped you region immoderate of the mystery.
With your caller RAG Agent, you’re fresh to reply questions from your knowledge guidelines and commencement building smarter, much responsive apps. As you research and fine-tune your deployment, don’t hesitate to research and accommodate these steps to your circumstantial needs. If you tally into roadblocks, remember: each awesome solution started pinch a tricky bug aliases an unanswered question. Happy building!
Here is the LegalTech RAG Agent repository which you tin usage to deploy your RAG Agent to App Platform successful nary time.
What to publication next
You tin besides cheque retired the pursuing tutorials to study much astir RAG, DigitalOcean Inference Engine, and MCP:
- Deploy Fine-Tuned LLM to Prod pinch BYOM + Dedicated Inference - This tutorial shows you really to deploy a fine-tuned LLM to accumulation pinch BYOM (Bring Your Own Model) and Dedicated Inference.
- Guide to RAG and MCP — erstwhile to usage retrieval vs instrumentality calling, and really the pieces fresh together.
- How to Build an MCP Server successful Python — build and link a civilization MCP server pinch FastMCP (complements the managed Knowledge Bases MCP endpoint).
- Serverless Inference pinch the DigitalOcean AI Platform — exemplary catalog, entree keys, and your first conclusion call.
- Using DigitalOcean’s Serverless Inference pinch the OpenAI SDK — aforesaid ChatOpenAI + inference.do-ai.run shape utilized successful rag_core.py.
- How to Use MCP pinch OpenAI Agents — ligament MCP devices into supplier frameworks beyond earthy curl.
 This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.

.png "Efficient Llm Compression With Sparsegpt And Wanda On Gpu Cloud")






.png "How To Use The Javascript Fetch Api")
.png "How To Configure Php-fpm With Nginx")



") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·