Training trillion-parameter models is expensive, but conclusion is the ongoing operational cost. Each petition takes up GPU memory, representation bandwidth, compute cycles, batching slots, and serving capacity. Model weights must unrecorded persistently successful GPU memory. The key-value cache grows during generation. The serving motor must multiplex crossed galore concurrent users pinch reasonable latency.
Let’s do a speedy thought experiment.
The representation required to shop the exemplary weights equals the number of parameters multiplied by the per-parameter precision successful bytes. So, for example, a seven‑billion‑parameter exemplary successful FP16 would require 2 bytes per weight. This intends conscionable the weights themselves require astir 7 × 10^9 × 2 ≈ 14 GB. This doesn’t see activation buffers, runtime overhead, batching, aliases KV caches. As you tin imagine, ample models quickly transcend the VRAM of communal GPUs. KV caches tin easy transcend the representation required by the weights. Buying larger GPUs is an unsustainable measurement to grip this growth. LLM compression is truthful becoming captious for conclusion efficiency.
That is why LLM compression is important. Rather than perpetually purchasing larger GPUs, teams tin build smaller, much businesslike models. There are respective methods of compression: quantization, distillation, low-rank approximation, and pruning. In this article, we’ll attraction connected pruning, and much specifically, SparseGPT pruning and Wanda pruning. Both methods are post-training methods that tin compress ample connection models without costly retraining.
Key Takeaways
- Pruning helps trim LLM conclusion cost by lowering the number of non-zero weights and reducing representation pressure.
- SparseGPT is stronger for value retention, particularly erstwhile pruning aggressively aliases targeting higher sparsity levels.
- Wanda is faster and easier to implement because it avoids Hessian estimation, reconstruction solving, and weight updates.
- Sparse models are not automatically faster; existent speedups require sparse-aware runtimes, sparse kernels, and hardware support.
- Pruning useful champion arsenic portion of a larger conclusion optimization strategy, mixed pinch quantization, KV-cache optimization, batching, caching, speculative decoding, and routing.
Why LLM Compression Matters
LLM conclusion is constrained by 4 awesome accumulation bottlenecks:
- GPU VRAM capacity. Model weights, KV cache, runtime tensors, and aggregate in-flight requests must each fresh successful memory. Offline testing whitethorn show the exemplary is “functional,” but nether existent postulation conditions, it whitethorn neglect owed to representation unit from accrued progressive series lengths and batch sizes.
- Memory bandwidth. During autoregressive decoding, the exemplary emits 1 token astatine a time. To emit each token, the GPU must many times load exemplary weights and cached attraction states. This often makes decoding memory-bound alternatively of compute-bound. In that case, a GPU pinch much earthy FLOPs does not ever present proportional speedups.
- Latency. Real user-facing apps require debased time-to-first-token, accordant inter-token latency, and predictable end-to-end latency. You could person a exemplary that generates high-quality answers, but if the responses are slow, the personification acquisition suffers.
- Cost. GPU unreality infrastructure is costly erstwhile GPUs are underutilized, overprovisioned, aliases blocked by representation limits. At scale, moreover mini ratio improvements tin trim costs per cardinal tokens.
Pruning reduces the full number of non‑zero weights successful the model. Sparse models shop galore zeros. In theory, this reduces representation and compute needs. If the conclusion stack tin return advantage of this sparsity—using compressed retention formats and sparse matrix multiplication kernels—models tin execute little VRAM footprint, higher throughput, and reduced latency. Real-world speedups dangle connected the hardware and package utilized to tally the model. Zeroing weights without changing the kernel will not velocity up inference.
Beyond GPU servers, compression enables caller modes of deployment. Pruned models tin beryllium deployed to smaller GPUs, separator devices, aliases moreover multi‑model servers. Memory savings fto teams colocate respective models connected a azygous GPU, usage cheaper instances, aliases fresh larger batch sizes for the aforesaid hardware budget. Compression is straight tied to the economics of inference: reducing representation per token reduces the costs per token.
Understanding sparsity: unstructured vs. structured
Neural networks are typically dense, meaning that astir of their weights are non-zero. A sparse network, connected the different hand, consists mostly of zero-valued weights. Network pruning increases sparsity by permanently mounting weights to zero. For connection models, location are 2 peculiarly important types of sparsity: unstructured and structured.
Unstructured sparsity
Unstructured pruning removes individual weights astatine random passim the model.This allows the pruning algorithm maximum elasticity successful choosing which weights to region while minimizing effect connected exemplary behavior. Because weights tin beryllium removed from the matrix astatine immoderate position, unstructured sparsity tin often support accuracy reasonably good for a fixed level of sparsity.
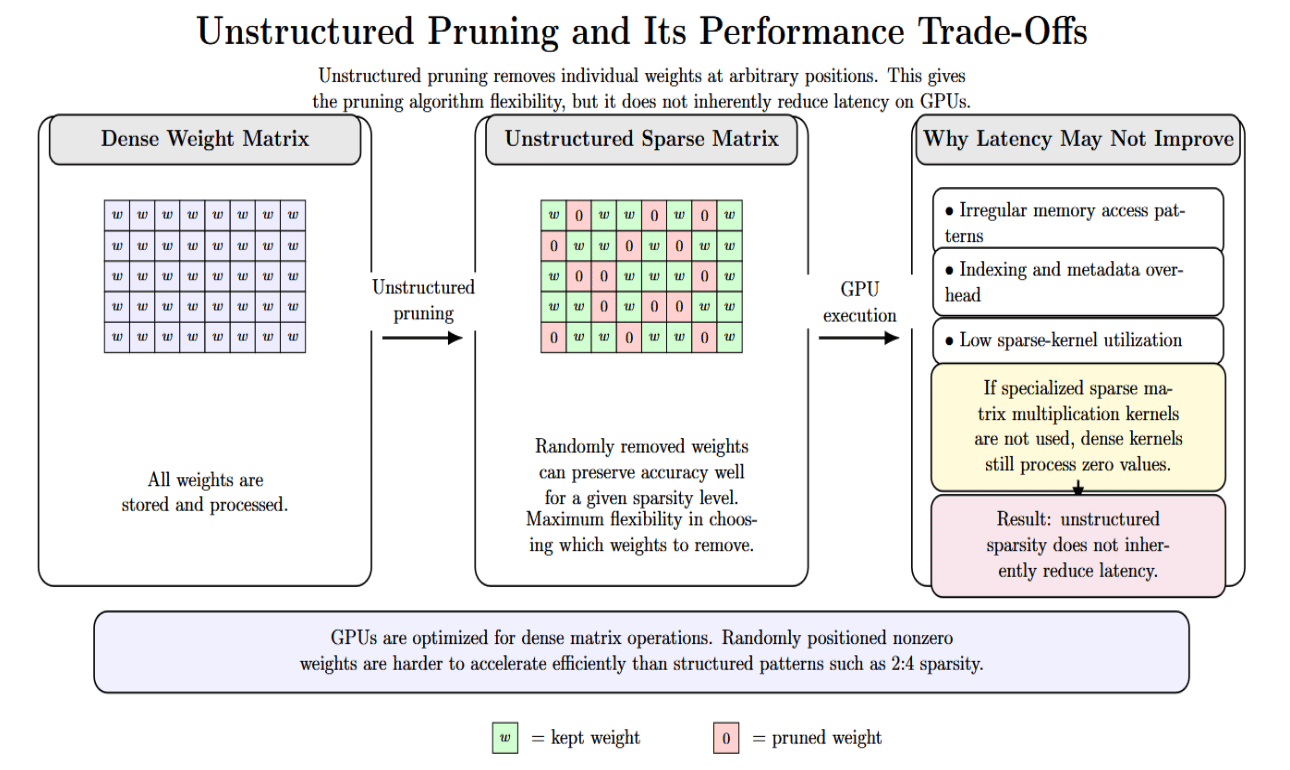
However, GPUs are designed to efficiently grip dense matrix operations. Sparse matrices pinch weights astatine random positions will consequence successful irregular representation entree patterns, indexing overhead, and debased kernel utilization. If specialized sparse-matrix multiplication kernels are not used, dense matrix multiplication still processes zero values. As a result, unstructured sparsity does not inherently trim latency.
Structured sparsity
Structured pruning eliminates weights successful regular structures, specified arsenic rows, columns, blocks, channels, aliases fixed groups of weights. An illustration of a hardware-friendly system shape is 2:4 sparsity, besides known arsenic semi-structured sparsity. With 2: 4 sparsity, 2 values wrong a artifact of 4 contiguous weights are zero. This results successful a 50% sparsity rate.
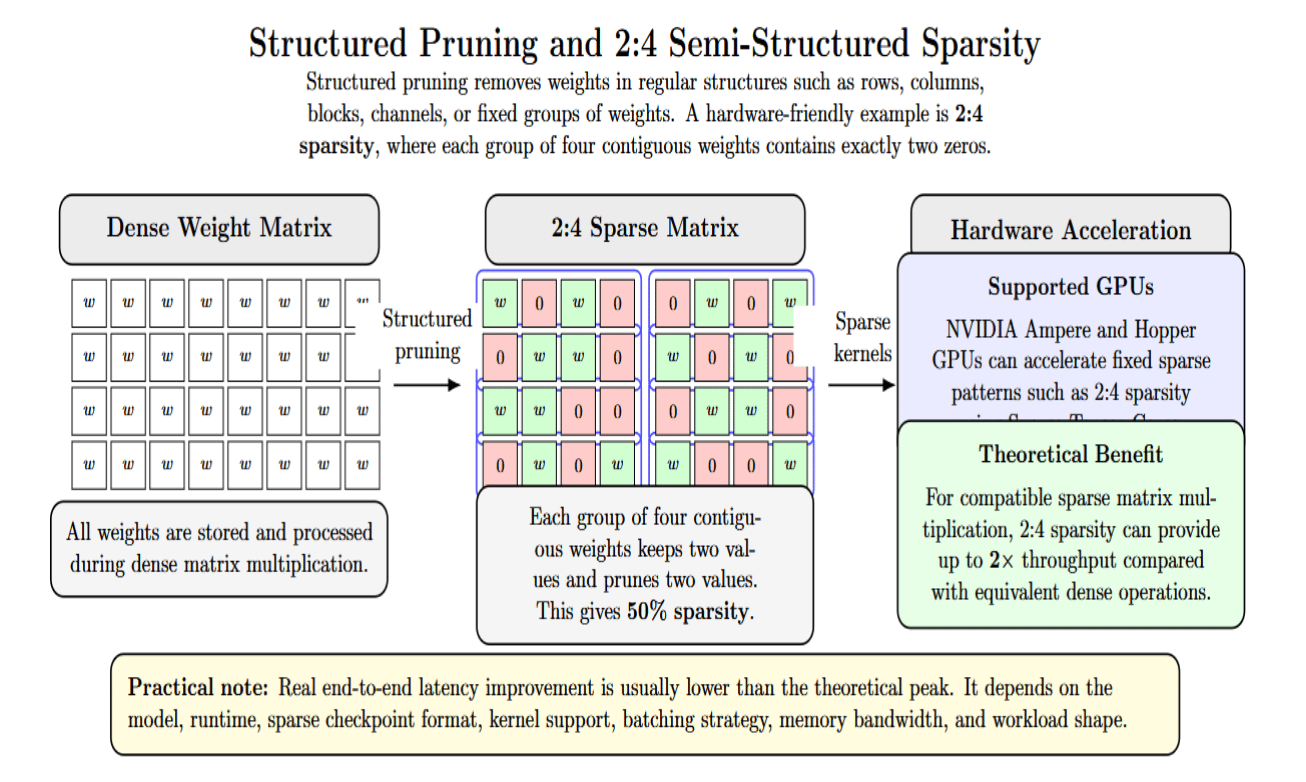
Supported GPUs tin accelerate these fixed sparse patterns. NVIDIA’s Ampere GPU architecture added support for Sparse Tensor Cores for fine-grained system sparsity, including the 2:4 pattern. In theory, they tin supply up to 2× matrix multiplication throughput compared pinch balanced dense operations. But successful practice, end-to-end latency betterment varies based connected model, runtime, kernels, and workload.
Traditional pruning vs. modern LLM pruning
Traditional neural-network pruning workflows consisted of a three-step loop: Train a dense model. Remove little important weights. Fine-tune aliases retrain the sparse exemplary to regain accuracy. Repeat until desired level of sparsity. Iterating this process tin lead to very sparse networks, but it requires important computation.
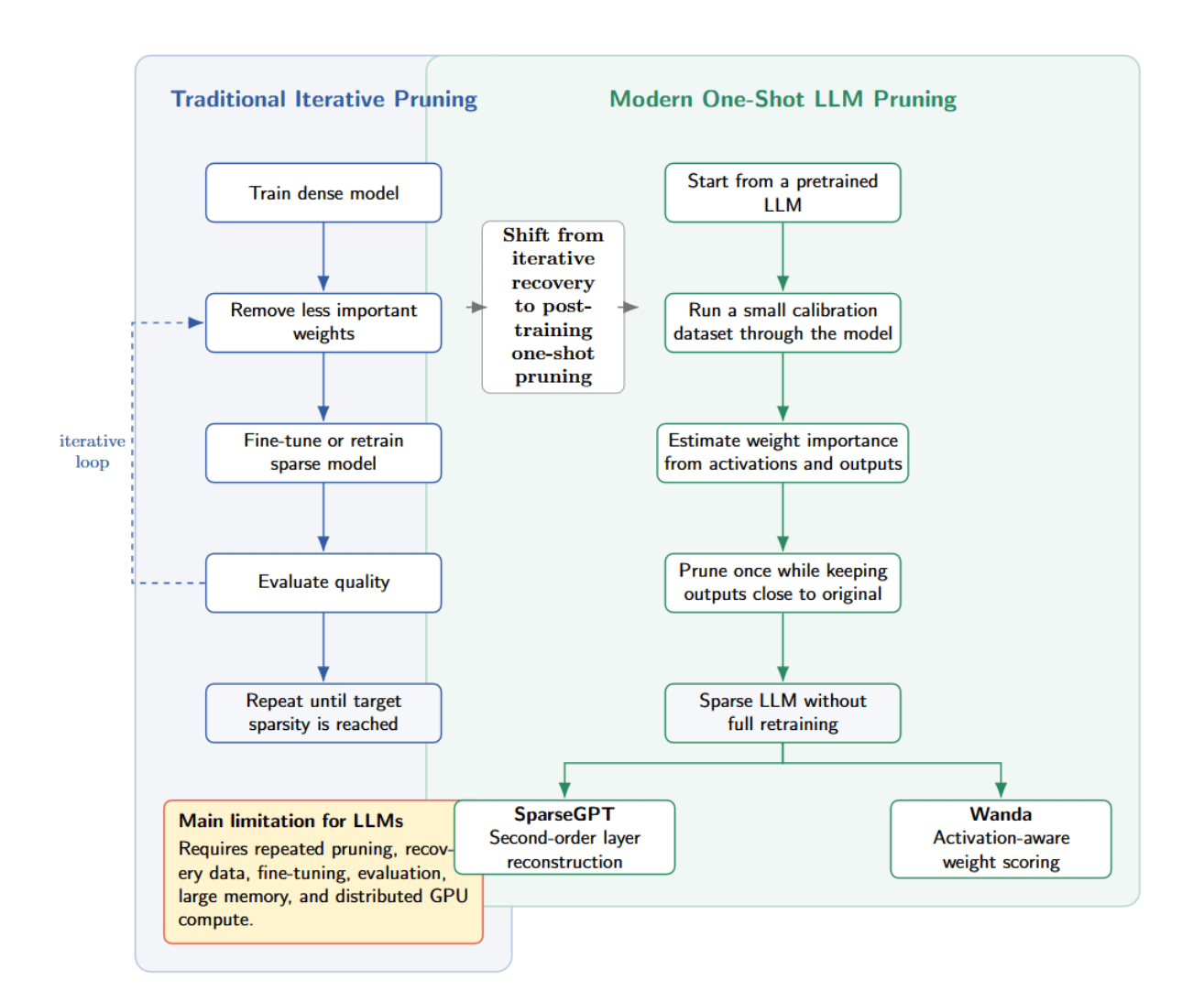
For billion-parameter LLMs, this pruning workflow is not easy done successful practice. You’d person to load tremendous models into representation and distributed GPU clusters, past hole due betterment data. After each pruning step, you would besides request to tally fine-tuning and measure exemplary value earlier moving to the adjacent compression stage.
Another limitation of immoderate older pruning methods is that they require costly second-order approximations aliases iterative weight updates. These methods whitethorn still support accuracy, but are much challenging to standard to larger models arsenic we displacement from millions to billions of parameters.
Modern LLM pruning methods attraction connected post-training, one-shot pruning. Instead of iterative fine-tuning, they return a pretrained exemplary and tally a mini calibration dataset done it to estimate which weights are little important. The exemplary is past pruned truthful that its outputs are kept “close” to the original outputs connected a typical group of inputs, without afloat retraining.
SparseGPT and Wanda are 2 notable methods of this category. SparseGPT estimates value utilizing second-order furniture reconstruction; Wanda uses a simpler attack of activation-aware weight-importance scoring.
SparseGPT: reconstruction‑based one‑shot pruning
SparseGPT is simply a one-shot pruning method applicable to monolithic GPT-style models. It frames pruning arsenic a layer-wise sparse regression problem. Given a linear furniture pinch weights W and calibration activations X, we want to find a pruned matrix that minimizes reconstruction error:
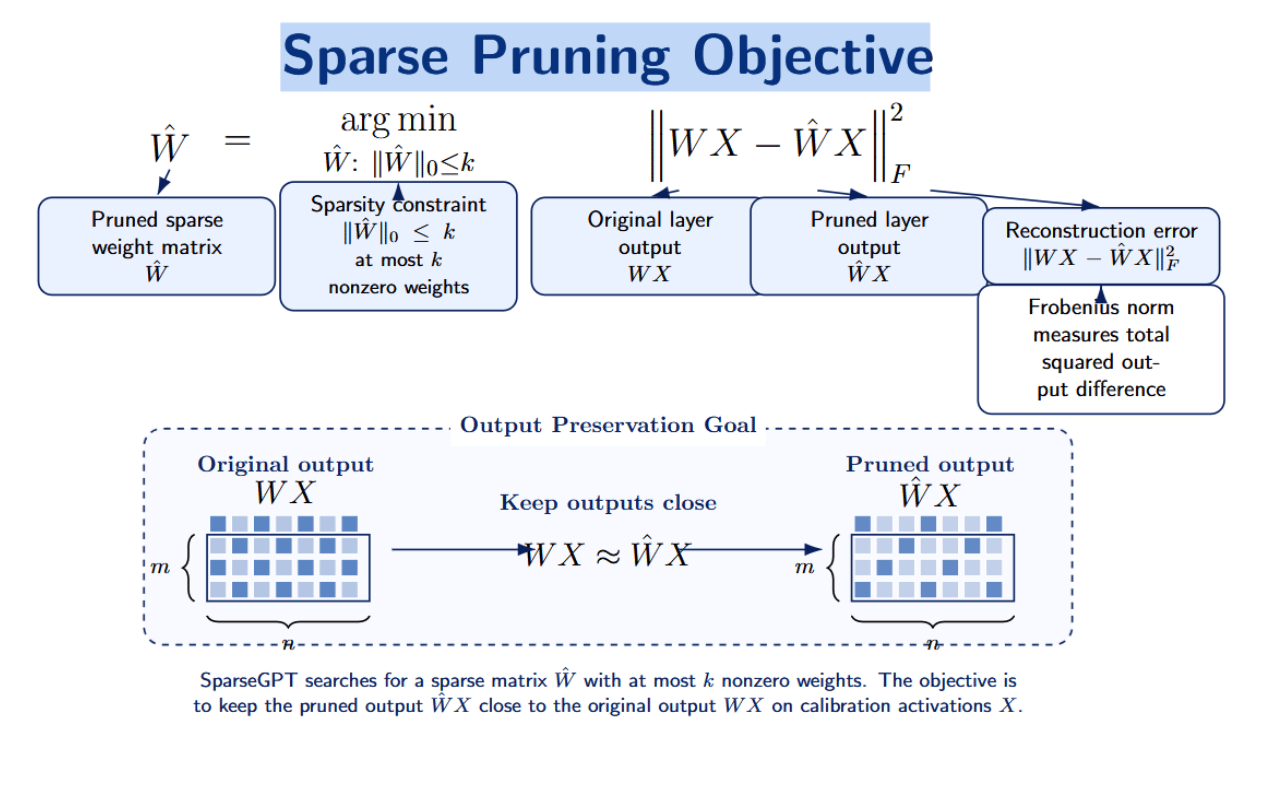
The outputs of the pruned furniture should intimately lucifer those of the original furniture for a fixed group of calibration data. SparseGPT tries to lucifer this layer’s output alternatively than naively dropping the smallest weights. It uses second-order information calculated from calibration activations to approximate the effect of pruning connected a layer’s output. After identifying which weights to prune, SparseGPT updates the remaining weights to compensate for the removed ones and minimize reconstruction error.
Why SparseGPT useful well
SparseGPT balances accuracy and ratio by combining respective ideas:
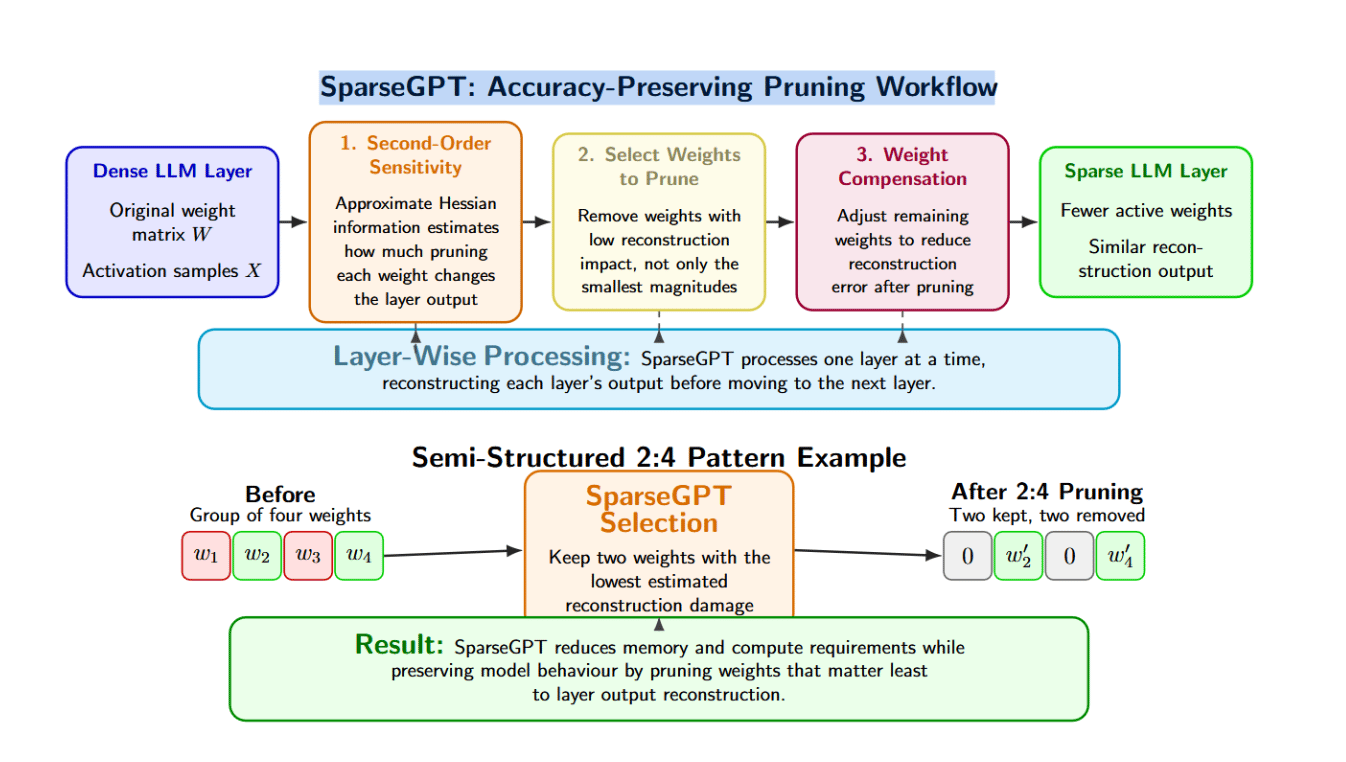
- Second‑order sensitivity. Instead of simply pruning weights based connected their magnitude, approximate Hessian accusation is utilized to rank weights by the effect their removal has connected output reconstruction. This allows important weights that aren’t needfully the largest to beryllium kept.
- Layer‑wise processing. Remaining weights tin beryllium tweaked aft pruning to trim reconstruction error. This measurement allows exemplary behaviour to beryllium maintained astatine higher levels of sparsity.
- Weight compensation. After pruning, the remaining weights tin beryllium adjusted to trim reconstruction error. This measurement helps support exemplary behaviour astatine higher sparsity levels.
- Compatibility pinch patterns. SparseGPT supports unstructured pruning arsenic good arsenic semi‑structured pruning patterns for illustration 2:4. In the lawsuit of 2:4, the algorithm considers each group of 4 weights and selects 2 to keep. This allows the pruning method to beryllium applied to hardware that has specialized support for system sparsity.
Thanks to these properties, SparseGPT maintains value acold amended than naive methods erstwhile pruning aggressively. Its complexity is higher, but the authors show it scales to models pinch tens to hundreds of billions of parameters.
Wanda: a elemental activation‑aware pruning method
Wanda (Pruning by Weights and Activations) is an attack to lightweight pruning that was introduced arsenic an replacement to reconstruction-based methods specified arsenic SparseGPT. Unlike these methods, it doesn’t impact solving a layer-wise reconstruction problem aliases estimating Hessians. Instead, it uses a simpler activation-aware value score:
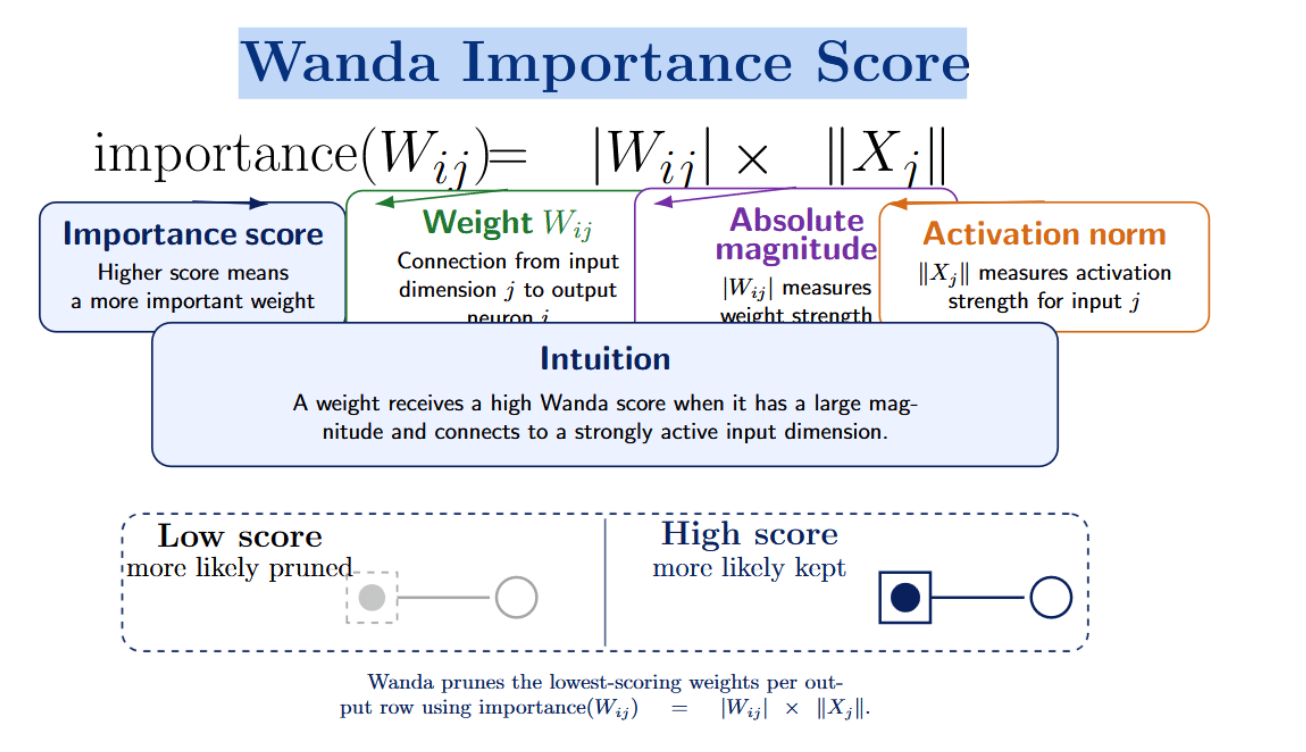
The intuition down this people is that a weight will beryllium important if it has a ample magnitude and connects to an input magnitude pinch beardown activation. A weight pinch mini magnitude aliases that connects to an input magnitude pinch anemic activation will beryllium much apt to person a debased value score, and tin truthful beryllium pruned. Wanda ranks weights by removing those pinch the smallest activation-scaled magnitudes per-output basis. The authors item that Wanda requires zero retraining aliases weight updates - the pruned exemplary tin beryllium utilized directly. Wanda heavy outperforms magnitude-based pruning and is competitory pinch much analyzable pruning methods successful experiments tally connected LLaMA and LLaMA-2.
Why Wanda is attractive
Wanda’s simplicity yields respective benefits:
- Ease of implementation. The algorithm requires only the postulation of activation norms and the sorting of weights. There are nary Hessian approximations aliases ample regression problems to solve.
- Fast pruning pass. There is nary weight update during pruning, truthful pruning monolithic models is orders of magnitude faster than SparseGPT. The Wanda authors declare Wanda is 5–10× faster than SparseGPT for 70B models trained connected a azygous GPU(specifically H100).
- Competitive accuracy. Despite Wanda’s simplicity, it retains value rather good for mean levels of sparsity. On Llama‑2 models, unstructured pruning pinch Wanda achieves perplexity adjacent to SparseGPT and is overmuch amended than axenic magnitude pruning.
- Baseline for experimentation. Engineering teams should beryllium capable to tally Wanda quickly to trial really sparse models behave successful their deployment stack earlier investing successful much blase techniques.
The trade‑off is that Wanda whitethorn suffer accuracy faster than SparseGPT astatine very precocious sparsity ratios. It does not support weight compensation and is designed chiefly for unstructured pruning, though the implementation includes options for 2:4 and 4:8 patterns.
Comparing SparseGPT and Wanda
Let’s see the pursuing table:
| Method type | One-shot post-training pruning | One-shot post-training pruning |
| Main signal | Second-order reconstruction correction minimization | Weight magnitude × activation norm |
| Hessian approximation | Yes | No |
| Weight update aft pruning | Yes (optional) | No |
| Complexity | Higher | Lower |
| Runtime cost | Slower | Faster |
| Accuracy retention | Excellent | Very good |
| Implementation difficulty | Moderate | Easy |
| Best usage case | High sparsity pinch beardown value retention | Fast baseline p |
SparseGPT shines erstwhile you request to clasp accuracy and person engineering resources available. Wanda is amended for accelerated experiments, lighter‑weight deployments, aliases erstwhile approximate answers are bully enough. Many teams benchmark some approaches to find the saccharine spot for their model, sparsity target, and hardware.
Practical pruning workflow connected GPU cloud
Deploying pruned LLMs involves some model‑level and infrastructure‑level considerations. A emblematic workflow looks for illustration this:
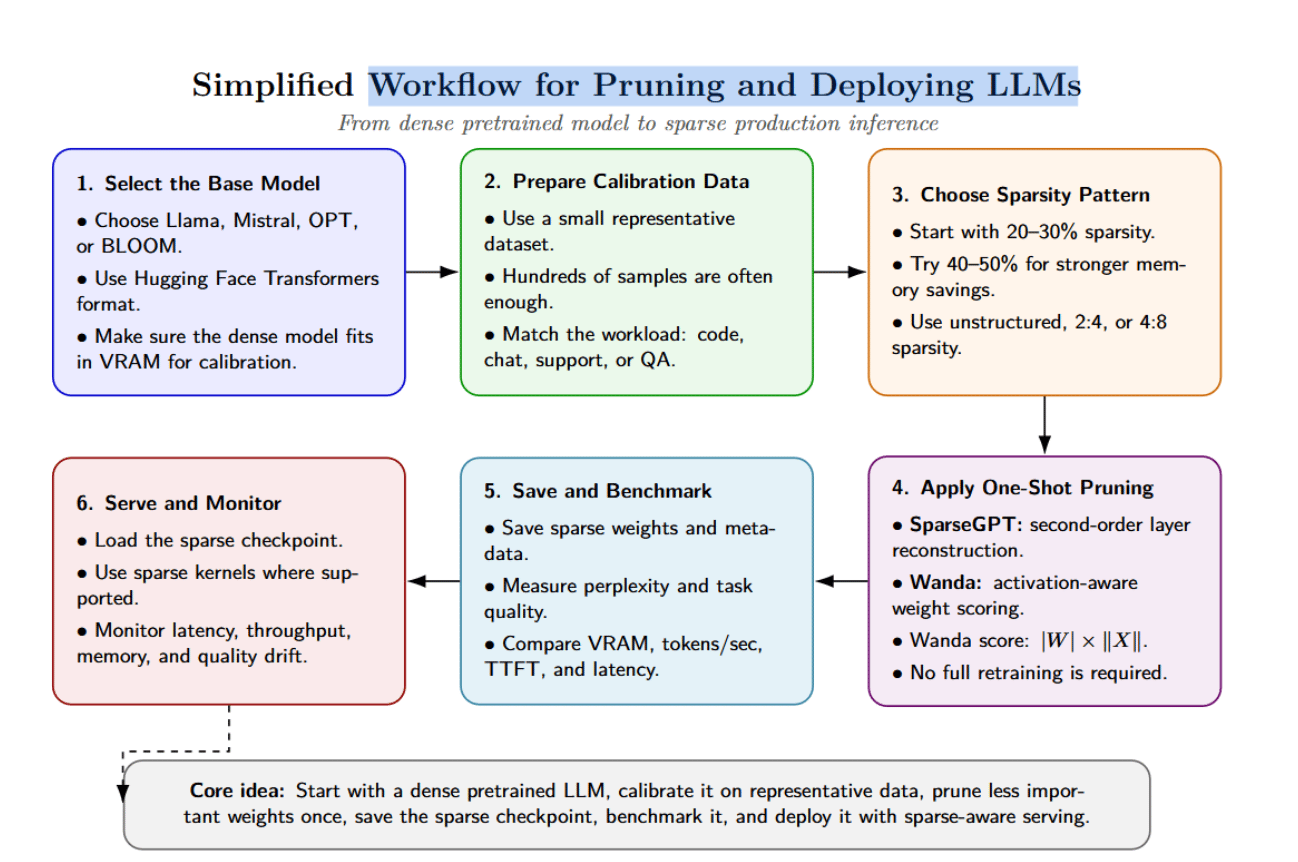
- Select the guidelines model. Choose an open‑source exemplary (e.g., Llama, Mistral, OPT, BLOOM) that suits your target exertion and has a compatible format you tin activity pinch (e.g., Hugging Face Transformers). Make judge the dense exemplary fits successful VRAM astatine slightest for calibration purposes.
- Prepare the calibration dataset. SparseGPT and Wanda require only a mini dataset that reflects the target workload. If you’re building a codification assistant, usage codification prompts. If you’re building a support chatbot, usage existent support conversations. Hundreds of samples are enough.
- Choose sparsity level and pattern. You tin commencement mini astatine 20–30% to observe the effects. Moderate sparsity successful the scope of 40-50% provides important representation savings pinch constricted value drops. For hardware acceleration, see 2:4 aliases 4:8 patterns.
- Apply the pruning method. SparseGPT method simply requires you to tally the provided scripts against each exemplary layer. The algorithm triggers the postulation of activations, runs the sparse regression solver, and tin optionally update weights. Wanda requires you to instrumentality the value metric against each linear projection. Each method only requires a azygous GPU. The runtime will standard pinch exemplary size.
- Save the sparse checkpoint. Simply shop weights utilizing the due format. For unstructured sparsity, you tin prevention weights and a mask. For 2: 4 sparsity, you’ll want to usage compressed formats compatible pinch PyTorch aliases TensorRT. Record metadata specified arsenic exemplary version, sparsity ratio, calibration data, pruning method, and information type.
- Benchmark the pruned model. Measure perplexity and downstream task value connected applicable datasets aliases workloads. Evaluate VRAM usage, tokens per second, time‑to‑first token, inter‑token latency, and conclusion costs per cardinal tokens. Measure some dense and sparse models nether the aforesaid conditions.
- Integrate into serving stack. When utilizing system sparsity, make judge the conclusion motor tin load sparse weight formats and dispatch sparse kernels. Framework extensions for illustration PyTorch’s to_ sparse_ semi_ system tin person 2:4 masks and accelerate nn.Linear layers.
- Monitor successful production. Track latency, throughput, representation usage, and value metrics. Adjust sparsity ratios aliases harvester pruning pinch quantization and KV‑cache optimisations arsenic needed.
Python example: implementing Wanda for a linear layer
Below is simply a simplified PyTorch usability that applies Wanda pruning to a azygous linear layer. In practice, you would widen this to each projection layers of the exemplary and grip system patterns.
import torch import torch.nn as nn @torch.no_grad() def wanda_prune_linear( layer: nn.Linear, input_activations: torch.Tensor, sparsity: float = 0.5 ): """ Apply Wanda-style unstructured pruning to 1 Linear layer. Args: layer: PyTorch Linear layer. input_activations: Calibration activations pinch shape [batch, seq_len, hidden_dim] aliases [num_tokens, hidden_dim]. sparsity: Fraction of weights to prune per output row. Returns: The pruned layer, modified in-place. """ if not isinstance(layer, nn.Linear): raise TypeError("wanda_prune_linear expects an nn.Linear layer.") if not 0.0 <= sparsity <= 1.0: raise ValueError("sparsity must beryllium betwixt 0 and 1.") # Flatten activations to style [n_tokens, input_dim] if input_activations.dim() == 3: X = input_activations.reshape(-1, input_activations.shape[-1]) else: X = input_activations W = layer.weight if X.shape[-1] != W.shape[1]: raise ValueError( f"Activation magnitude {X.shape[-1]} does not lucifer " f"layer input magnitude {W.shape[1]}." ) # Compute L2 norm of each input dimension activation_norm = torch.norm(X, p=2, dim=0) # Compute Wanda value scores: |W_ij| * ||X_j|| scores = torch.abs(W) * activation_norm.unsqueeze(0) # Number of weights to prune per output row num_prune = int(W.shape[1] * sparsity) if num_prune == 0: return layer # Build pruning mask disguise = torch.ones_like(W, dtype=torch.bool) for statement in range(W.shape[0]): prune_indices = torch.topk( scores[row], k=num_prune, largest=False ).indices mask[row, prune_indices] = False # Apply disguise in-place W.mul_(mask) return layer # Example usage device = "cuda" if torch.cuda.is_available() else "cpu" hidden_dim = 4096 linear = nn.Linear(hidden_dim, hidden_dim, bias=False).half().to(device) calibration_activations = torch.randn( 4, 128, hidden_dim, device=device, dtype=torch.float16 ) pruned_layer = wanda_prune_linear( linear, calibration_activations, sparsity=0.5 ) zero_count = torch.sum(pruned_layer.weight == 0).item() total_count = pruned_layer.weight.numel() print(f"Sparsity: {zero_count / total_count:.2%}")This is an illustration of simplified Wanda-style pruning for a azygous nn.Linear furniture successful PyTorch. Calibration activations are utilized to compute the L2 norm of each input dimension. Activation norms are multiplied by the absolute worth of the weight to cipher Wanda value scores. The lowest-scoring weights are pruned for each statement of the output according to the desired sparsity ratio by multiplying by a binary disguise successful place. In this example, a half-precision linear furniture is created. Random calibration activations are generated. The furniture is pruned to 50% sparsity, and the last percent of zeros successful the weight is printed.
Benchmarking sparse models: metrics and expectations
Evaluating pruned models requires metrics that seizure some value and efficiency:
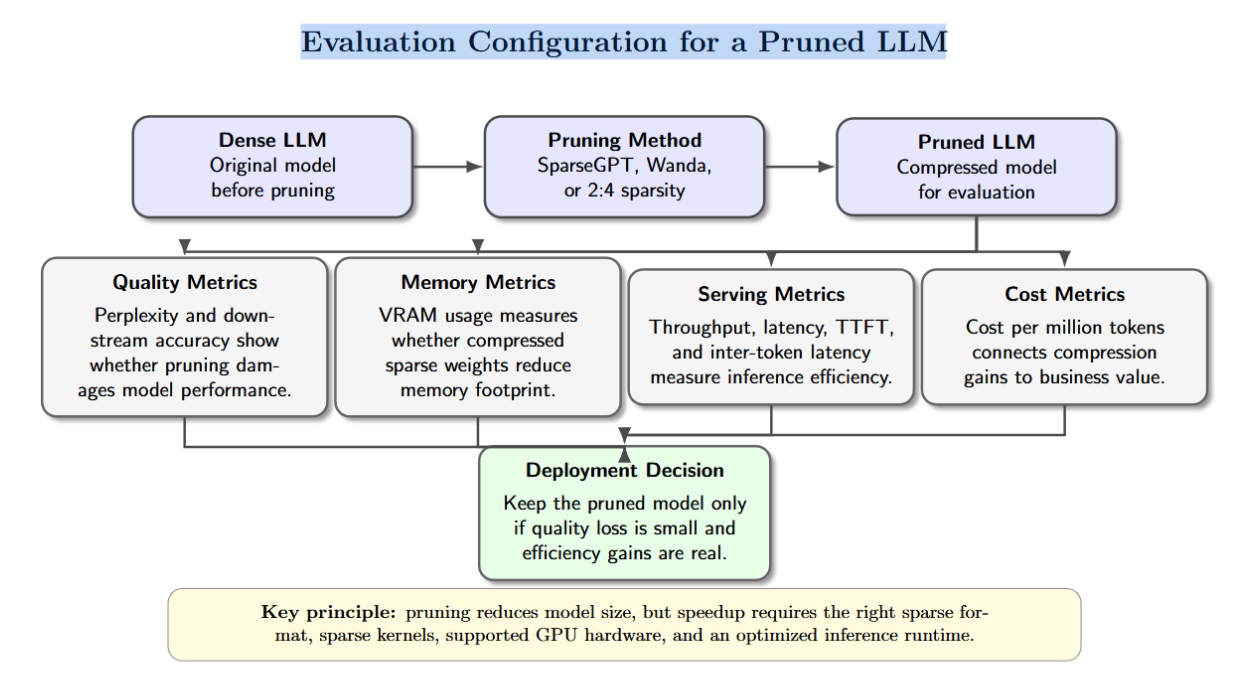
- Perplexity and downstream accuracy show really pruning affects connection modelling and task performance. SparseGPT authors study that GPT-family models tin beryllium pruned to >=50% sparsity successful 1 changeable without immoderate retraining pinch minimal accuracy loss. They show that OPT-175B and BLOOM-176B some tin scope 60% unstructured sparsity pinch a negligible summation successful perplexity.
- VRAM usage reflects representation savings. If the conclusion stack stores pruned weights successful compressed formats and uses sparse kernels, VRAM depletion drops astir successful proportionality to sparsity.
- Throughput (tokens/second) and latency measurement serving efficiency. Speedups require replacing dense kernels pinch sparse kernels; otherwise, zero weights still devour compute. For semi‑structured 2:4 sparsity, PyTorch’s tutorial demonstrates a 1.3× speedup for BERT connected A100 GPU.
- Time‑to‑first token and inter‑token latency gauge personification experience. A smaller representation footprint tin trim these latencies.
- Cost per cardinal tokens connects engineering improvements to business value. Compression that halves representation and increases throughput tin importantly little costs per token.
It is important to group realistic expectations: 50% sparsity does not guarantee 2× speedup. The existent speedup depends connected hardware support, kernel implementation, batch size, and whether the workload is dominated by weight computation aliases KV‑cache operations. Structured sparsity is easier to accelerate because hardware and package support circumstantial patterns. Unstructured sparsity often requires civilization CUDA kernels aliases frameworks for illustration Triton.
The Infrastructure Side of Sparse Inference
Pruning is not conscionable a exemplary optimisation technique—it is an infrastructure problem. Several factors find whether sparsity translates into speed:
- Checkpoint format. Storing zero weights successful a dense tensor wastes retention and reduces imaginable representation savings. Semi-structured sparsity is stored successful compressed formats, wherever non-zero elements are stored on pinch metadata describing their position. Libraries for illustration cusparSELt supply kernels optimized for circumstantial supported sparse formats.
- Kernel support. Dense matrix multiplication kernels do not skip zero weights. To summation speed, the runtime must dispatch sparse kernels that tin utilization the sparse weight layout. PyTorch’s to_ sparse_semi_ structured method tin toggle shape weights that already person a supported semi-structured sparsity shape into a sparse tensor datatype that unlocks sparse-kernel execution.
- NVIDIA Ampere and Hopper GPUs support sparse Tensor Cores, but only for hardware-friendly patterns specified arsenic 2:4 sparsity. Unstructured sparsity (i.e., random pruning) is harder to accelerate and whitethorn require wide sparse GEMM libraries aliases penning civilization kernels. Additionally, it often does not supply beardown speedups unless the exemplary is some highly sparse and the runtime is optimized for sparsity.
- Batching and scheduling. Sparse matrix multiplication whitethorn beryllium faster, but wide latency besides depends connected KV- cache management, batching, petition scheduling, and representation bandwidth. In long-context aliases highly concurrent workloads, the KV cache tin predominate representation usage, and trim the applicable use of weight pruning.
- Observability. It is basal to person bully observability connected latency, throughput, GPU utilization, representation usage, and quality. While sparsifying a exemplary could trim latency successful a leaderboard benchmark, it mightiness origin value connected user-facing tasks to autumn beneath accumulation standards.
The image beneath shows really pruning tin velocity up LLM conclusion only erstwhile the model, sparse checkpoint format, GPU kernels, and serving infrastructure are decently aligned. It uses a elemental 2:4 sparsity illustration to show why pruning unsocial is not capable for existent accumulation gains.
When to Use SparseGPT and Wanda
Choose SparseGPT aliases Wanda erstwhile you want to trim conclusion costs without retraining from scratch. Use them to fresh larger models into smaller GPUs, to service much models connected a azygous GPU node, to trim representation footprint and KV cache pressure. They tin thief to quickly trial compressed variants of your LLMs, hole the models for separator deployment, and amended the economics of deploying open-source LLMs.
Don’t trust connected pruning unsocial if your conclusion motor can’t utilization sparse weights, your workload accesses the KV cache astir of the time, your exemplary value drops aft pruning, aliases the deployment hardware doesn’t support sparse acceleration.
Choose SparseGPT if maintaining value astatine a higher sparsity level is your superior goal. Choose Wanda if accelerated experimentation and debased implementation complexity matter more.
The correct accumulation mobility is not simply: “Is the exemplary sparse?” The amended mobility is: “Does this sparse exemplary trim costs per useful token while preserving quality?”
FAQs
-
What is LLM pruning? LLM pruning is simply a compression method that removes little important weights from a model. The extremity is to trim representation usage and conclusion costs while preserving exemplary quality.
-
What is the quality betwixt SparseGPT and Wanda? SparseGPT uses second-order reconstruction to sphere furniture outputs aft pruning. Wanda uses a simpler activation-aware people based connected weight magnitude and input activation norm, making it easier and faster to apply.
-
Does pruning automatically make an LLM faster? No. Pruning only improves velocity erstwhile the conclusion stack tin utilization sparse weights done sparse formats, sparse kernels, and compatible hardware. If dense kernels still process zero weights, latency whitethorn not improve.
-
When should I take SparseGPT? Choosing SparseGPT erstwhile maintaining value astatine higher sparsity levels is the main goal. It is much complex, but it is designed to sphere exemplary behaviour done reconstruction and weight compensation.
-
When should I take Wanda? Choose Wanda erstwhile accelerated experimentation, simplicity, and debased implementation complexity matter more. It is simply a beardown baseline for quickly testing really pruning affects a exemplary earlier investing successful much analyzable optimization.
Conclusion
SparseGPT and Wanda some exemplify that we tin prune ample connection models aft training without retraining. SparseGPT uses an progressive reconstruction‑based metric pinch second‑order approximations to execute this astatine standard while retaining accuracy. Wanda takes a overmuch simpler activation‑aware approach, multiplying the weight by the input norm activation, enabling accelerated pruning pinch minimal engineering cost. Both projects consequence successful sparse models that relieve representation unit and (with the correct kernels and hardware) amended conclusion throughput & little latency.
Pruning isn’t the only consideration, though. Speedups and costs savings will only beryllium realised pinch system‑level support for sparse formats, civilization sparse kernels, smart representation optimisation and different techniques specified arsenic quantization and KV‑cache management. Inference stacks deployed successful accumulation will apt usage a operation of strategies–pruning, quantization, caching, batching, speculative decoding, routing–to service responsive AI services astatine the lowest imaginable cost. In that future, pruning will beryllium a modular portion of the LLM optimisation pipeline: not simply a investigation novelty but a applicable instrumentality for reducing costs per token and scaling AI services efficiently.
References
- SparseGPT: Massive Language Models Can Be Accurately Pruned successful One-Shot
- A Simple and Effective Pruning Approach for Large Language Models
- Accelerating BERT pinch semi-structured (2:4) sparsity
- Estimating LLM Inference Memory Requirements
- Pruning LLMs by Weights and Activations
 This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.

")







.png "How To Use The Javascript Fetch Api")



![How To Do An Seo Competitor Analysis [+ Template]](https://static.semrush.com/blog/uploads/media/55/5c/555c50d3d1615501c9aa6723041f9c69/f2fae774a680cffb3b2df513dbb9e38a/seo-competitor-analysis.png "How To Do An Seo Competitor Analysis [+ Template]")
") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·