Introduction
Everyone wants to talk astir training. The GPU clusters, the trillion-token datasets, the months-long runs that costs millions of dollars. But here’s the thing: erstwhile a exemplary is trained, it needs to run. Millions of times a day. For existent users. With existent latency expectations and existent infrastructure budgets.
That’s inference. And conclusion is softly wherever astir of the engineering activity really happens. When a personification types a connection into a chatbot and expects a consequence successful nether a second, the exemplary doesn’t get to return its time. It needs to make tokens fast, usage representation efficiently, and do it astatine a costs that doesn’t make your unreality measure spell entity high. A 70-billion-parameter exemplary sitting connected a server isn’t conscionable a mathematics problem, but it’s an operational one. This is wherever conclusion optimization comes in.
Over the past fewer years, we person been introduced to a batch of techniques to make large connection models faster, leaner, and cheaper to run, without importantly losing the accuracy. Some of these techniques activity astatine the exemplary level, changing really weights are stored aliases really the web is structured. Others activity astatine the serving level, changing really requests are batched and really representation is managed. The champion deployments make usage of respective of them together.
In this two-part article, we will screen 5 of the astir important techniques for LLM conclusion optimization:
Quantization reduces the numerical precision of exemplary weights by shrinking a exemplary that erstwhile needed 32 bits per number down to 8, 4, aliases moreover fewer, pinch amazingly small value loss.
Pruning removes parts of the exemplary that aren’t pulling their weight, repetitive attraction heads, dispensable layers, and near-zero-parameter layers, truthful the exemplary stays tin while becoming structurally smaller.
Knowledge Distillation takes the intelligence locked wrong a monolithic exemplary and transfers it into a overmuch smaller one, training the mini exemplary to deliberation for illustration the large 1 alternatively than learning from scratch.
KV Caching solves 1 of the astir costly hidden costs successful autoregressive generation: the truth that each caller token needs accusation from each erstwhile token, by storing and reusing the intermediate computations truthful you don’t recalculate them complete and over.
Speculative Decoding attacks the basal bottleneck of token-by-token procreation by utilizing a small, accelerated draught exemplary to conjecture ahead, past having the ample exemplary verify aggregate tokens astatine erstwhile successful parallel, legally cheating the sequential quality of connection generation.
Each of these techniques solves a different problem. Quantization and pruning shrink the model. Distillation replaces it pinch thing smaller. KV caching makes representation guidance smarter. Speculative decoding makes procreation itself faster. Together, they shape a stack, and knowing really they interact is conscionable arsenic important arsenic knowing each 1 individually.
In this two-part series, we will research each of these conclusion optimization techniques successful detail. In the first part, we will return a heavy dive into quantization and pruning, knowing really these techniques thief make ample models smaller, faster, and much businesslike for real-world deployment.
One point to support successful mind arsenic you read: these aren’t theoretical investigation ideas sitting successful papers. They’re moving successful accumulation correct now. By the extremity of this article, you’ll understand not conscionable what each method does, but why it works, wherever it breaks down, and really to deliberation astir combining them for your ain deployment scenarios. Whether you’re moving a azygous GPU connected a fund aliases orchestrating a multi-node H100 cluster, the aforesaid principles apply; only the knobs change.
Key Takeaways
- Quantization reduces the precision of exemplary weights, making LLMs smaller, faster, and cheaper to tally without heavy affecting quality.
- Pruning removes little important weights aliases connections from a exemplary to amended ratio and trim representation usage.
- Techniques for illustration GPTQ, AWQ, and LLM.int8() let quantization of pretrained models without afloat retraining.
- Combining pruning and quantization tin importantly optimize performance, particularly for separator devices and budget-friendly deployments.
- Moderate optimization usually keeps exemplary value adjacent to the original, but fierce compression tin trim accuracy and reasoning ability.
- Calibration datasets thief quantization methods understand really the exemplary behaves successful existent workloads and usually require only a mini magnitude of sample data.
- Optimization is becoming basal arsenic organizations look for ways to deploy ample models efficiently without relying connected costly GPU infrastructure.
Quantization — Shrinking the Numbers Without Losing the Meaning
Quantization is simply a method utilized to make AI models smaller, faster, and cheaper to tally by reducing the precision of the exemplary weights and activations. Everyone wants to talk astir training. But here’s the thing: does a neural web really request 32 bits to shop a number? The answer, almost always, is no. And that lays the instauration of quantization. Let america commencement by knowing a small spot astir weight and floating-point numbers.
What Is a Weight, Really?
A neural web learns information aliases immoderate patterns by adjusting millions aliases moreover billions of mini numerical values, which are called weights. These are fundamentally the model’s “memory” aliases “knowledge.” During training, the exemplary continuously updates these weights truthful that its predictions go much accurate.
Now the adjacent mobility becomes:
How are these weights stored wrong the computer? Most AI models shop weights arsenic floating-point numbers. A floating-point number is simply a measurement to correspond numbers pinch decimals, specified as:
0.245 -1.732 3.14159Computers shop these numbers utilizing bits. The astir communal format successful heavy learning is:
| FP32 (Float32) | 32 bits |
| FP16 (Float16) | 16 bits |
| BF16 (BFloat16) | 16 bits |
| INT8 | 8 bits |
The Problem With FP32 is FP32 is accurate, but expensive.
Using 32 bits for each weight means:
- more representation usage
- slower information transfer
- higher powerfulness consumption
- expensive inference
And this leads to an important realization: Many neural networks do not really request highly precise numbers.
For example:
0.123456789can often beryllium approximated as:
0.12without noticeably affecting the model’s output.
That thought leads straight to quantization.
Quantization is 1 of the astir important optimization techniques successful modern AI systems. The basal thought is simple: alternatively of storing and processing exemplary weights utilizing large, high-precision numbers for illustration FP32, we person them into smaller and much businesslike formats specified arsenic FP16, BF16, INT8, aliases moreover INT4. The extremity is to trim representation usage and summation conclusion velocity without importantly affecting the value of the model’s output.
Large connection models incorporate billions of parameters, and each parameter is represented arsenic a number. In FP32 format, each parameter takes 32 bits of memory. A exemplary pinch 7 cardinal parameters, therefore, requires monolithic amounts of VRAM conscionable to load the weights. Quantization reduces the size of these numbers, allowing the aforesaid exemplary to tally connected smaller GPUs, user hardware, separator devices, and large-scale conclusion servers much efficiently.
For example, a 7 cardinal exemplary stored successful FP32 whitethorn require around:
7 x 109 x 4 bytes = 28 GB 7 x 109 x 1 byte = 7 GB
When quantized to INT8, the aforesaid exemplary whitethorn usage astir one-fourth of that memory. This simplification dramatically lowers infrastructure costs and improves scalability.
At the halfway of quantization is the thought that neural networks do not ever request highly precise decimal values to usability well. During training, a exemplary whitethorn study weights specified as:
0.18273642But during inference, the exemplary tin often activity pinch approximate representations of these values without noticeable value loss. Quantization converts these floating-point numbers into lower-precision formats while preserving the wide meaning and behaviour of the model.
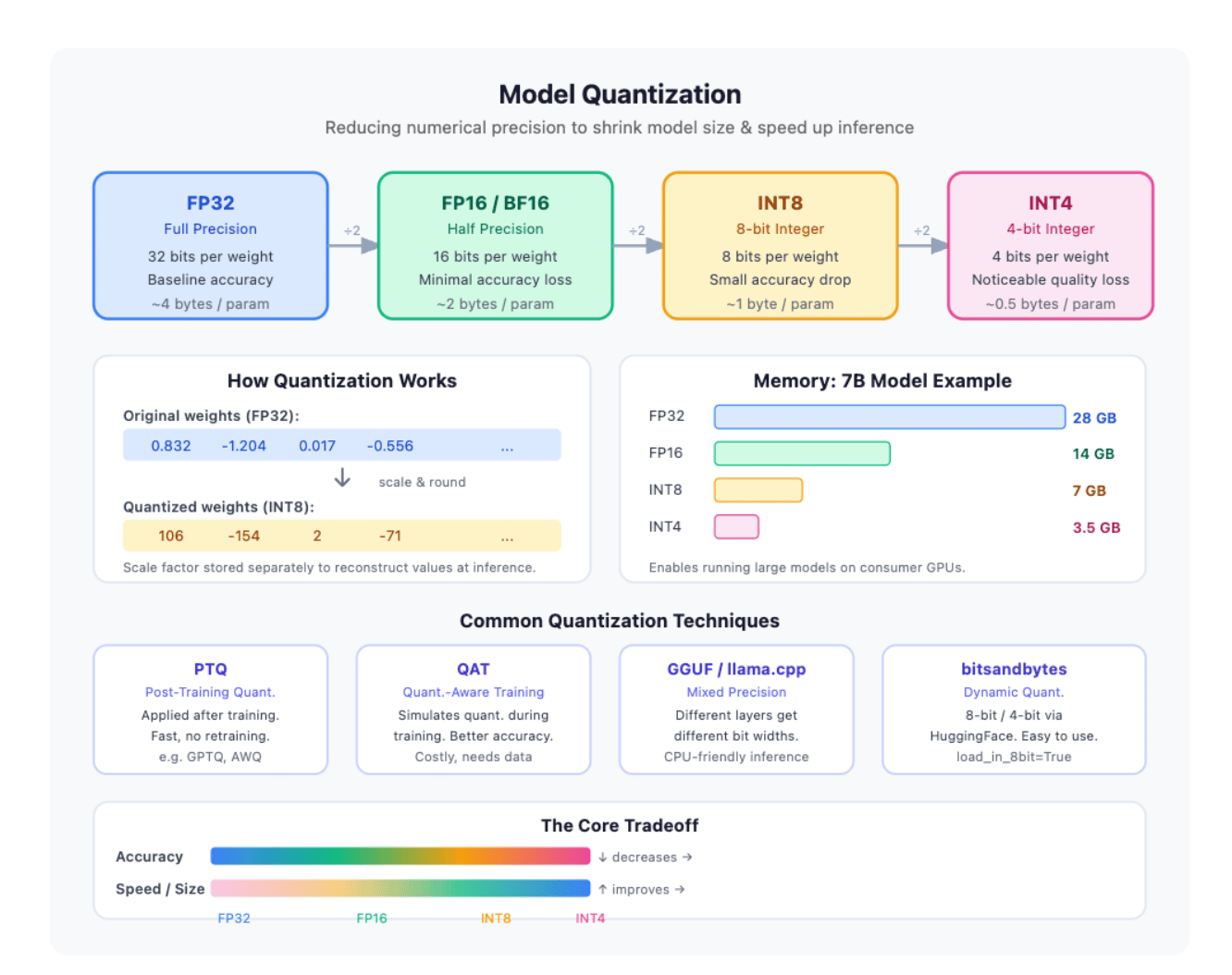
One of the astir communal approaches is Post-Training Quantization (PTQ). In PTQ, the exemplary is first trained usually utilizing FP32 aliases BF16 precision. After training is complete, the weights are compressed into formats for illustration INT8 aliases INT4. No retraining is required, which makes PTQ fast, inexpensive, and applicable for real-world deployment. This is heavy utilized successful conclusion systems wherever the superior extremity is to trim latency and representation consumption.
PTQ illustration successful PyTorch
import torch import torch.nn as nn import torch.quantization # Simple neural network class SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() self.fc1 = nn.Linear(10, 32) self.relu = nn.ReLU() self.fc2 = nn.Linear(32, 2) def forward(self, x): x = self.fc1(x) x = self.relu(x) x = self.fc2(x) return x # Create model model = SimpleModel() # Set exemplary to information mode model.eval() # Specify quantization configuration model.qconfig = torch.quantization.get_default_qconfig("fbgemm") # Prepare the exemplary for fixed quantization torch.quantization.prepare(model, inplace=True) # Calibration step # Run immoderate sample information done the model sample_input = torch.randn(100, 10) with torch.no_grad(): model(sample_input) # Convert exemplary to INT8 quantized version torch.quantization.convert(model, inplace=True) # Test inference test_input = torch.randn(1, 10) with torch.no_grad(): output = model(test_input) print(output)Another wide utilized method is Dynamic Quantization, wherever weights are quantized up of time, but activations are quantized dynamically during runtime. This attack is elemental to instrumentality and useful peculiarly good connected CPUs. Frameworks for illustration PyTorch support move quantization pinch conscionable a fewer lines of code, making it a communal prime for accumulation APIs and lightweight deployments.
quantized_model = torch.quantization.quantize_dynamic( model, {nn.Linear}, dtype=torch.qint8 )Static Quantization goes a measurement further by quantizing some weights and activations earlier conclusion begins. This requires a calibration dataset that helps find the scope of activation values the exemplary will brushwood during existent usage. Because the quantization parameters are computed beforehand, fixed quantization often provides amended capacity and little latency than move quantization. It is often utilized successful mobile AI systems, embedded devices, and optimized conclusion engines.
For scenarios wherever maintaining exemplary accuracy is critical, organizations usage Quantization-Aware Training (QAT). In QAT, the exemplary simulates quantization effects during training itself. The web learns to accommodate to little precision representations while still optimizing its weights. This attack mostly preserves accuracy overmuch amended than post-training quantization, particularly erstwhile targeting fierce formats for illustration INT4. Although QAT is much computationally expensive, it is wide utilized successful high-performance accumulation environments wherever accuracy degradation is unacceptable.
Modern LLM serving systems progressively trust connected precocious quantization techniques specified arsenic GPTQ, AWQ, and GGUF formats. GPTQ, aliases Generalized Post-Training Quantization, focuses connected reducing quantization correction furniture by layer, enabling ample models to tally efficiently successful 4-bit precision pinch minimal value loss. AWQ, aliases Activation-Aware Weight Quantization, improves upon this by identifying which weights are astir important for preserving activations and protecting them during quantization. These techniques are now commonly utilized for deploying models for illustration Llama, Mistral, and Qwen connected user GPUs.
Quantization is besides profoundly connected pinch modern conclusion frameworks, specified as:
- TensorRT
- ONNX Runtime
- vLLM
- llama.cpp
These systems harvester quantization pinch different optimizations for illustration kernel fusion, speculative decoding, and KV caching to maximize throughput and trim latency for real-time AI applications.
In real-world deployments, quantization enables AI systems to standard economically. Cloud providers usage quantized models to service thousands of concurrent users while reducing GPU costs. Edge AI systems usage quantization to tally computer vision models connected phones, drones, and IoT devices. Chatbots and RAG pipelines trust connected quantized LLMs to trim conclusion latency and amended consequence speed. Without quantization, galore modern AI products would simply beryllium excessively costly to run astatine scale.
However, quantization ever involves tradeoffs. Lower precision formats trim representation usage and amended speed, but they besides present approximation errors. If quantization is excessively aggressive, the exemplary whitethorn hallucinate much often, suffer reasoning quality, aliases make unstable outputs. This is why choosing the correct precision level is important. Many accumulation systems now usage mixed precision strategies, wherever delicate layers stay successful higher precision while little important layers are aggressively quantized.
The occurrence of quantization comes from a elemental but powerful realization: neural networks are remarkably tolerant to mini numerical approximations. By cautiously shrinking the numbers without destroying their meaning, quantization makes modern AI practical, scalable, and affordable.
Pruning — Teaching a Model to Do More pinch Less
Quantization shrinks the numbers wrong a model. Pruning takes a much fierce approach: it removes parts of the exemplary entirely. Pruning is besides a celebrated believe done successful determination trees wherever definite branches aliases determination splits are removed to trim exemplary overfitting.
The intuition is amazingly simple. After training, not each parameter successful a neural web contributes equally. Some attraction heads are hardly doing anything. Some layers are astir redundant. Some individual weights are truthful adjacent to zero that they lend almost thing to the output. Pruning finds these underperforming parts and removes them, frankincense giving you a exemplary that’s smaller, faster, and often only marginally little capable.
The Lottery Ticket Hypothesis
In 2018, Frankle and Carlin published a finding that changed really researchers deliberation astir neural web structure. They showed that wrong each large, dense neural network, location exists a overmuch smaller subnetwork besides known arsenic a “winning lottery ticket” that, if trained successful isolation from the start, reaches the aforesaid accuracy arsenic the afloat model.
Neural web pruning techniques tin trim the parameter counts of trained networks by complete 90%, decreasing retention requirements and improving computational capacity of conclusion without compromising accuracy. However, modern acquisition is that the sparse architectures produced by pruning are difficult to train from the start, which would likewise amended training performance. -The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks Research Paper 2018
The accusation is profound: ample models whitethorn beryllium over-parameterized by design, not by necessity. The other parameters aren’t each contributing to intelligence, but galore of them beryllium to make optimization easier during training. Once training is done, you tin find and support only the subnetwork that matters.
This gave pruning a theoretical foundation. The mobility shifted from “can we region parameters?” to “how do we find the correct ones to remove?”
Unstructured vs. Structured Pruning
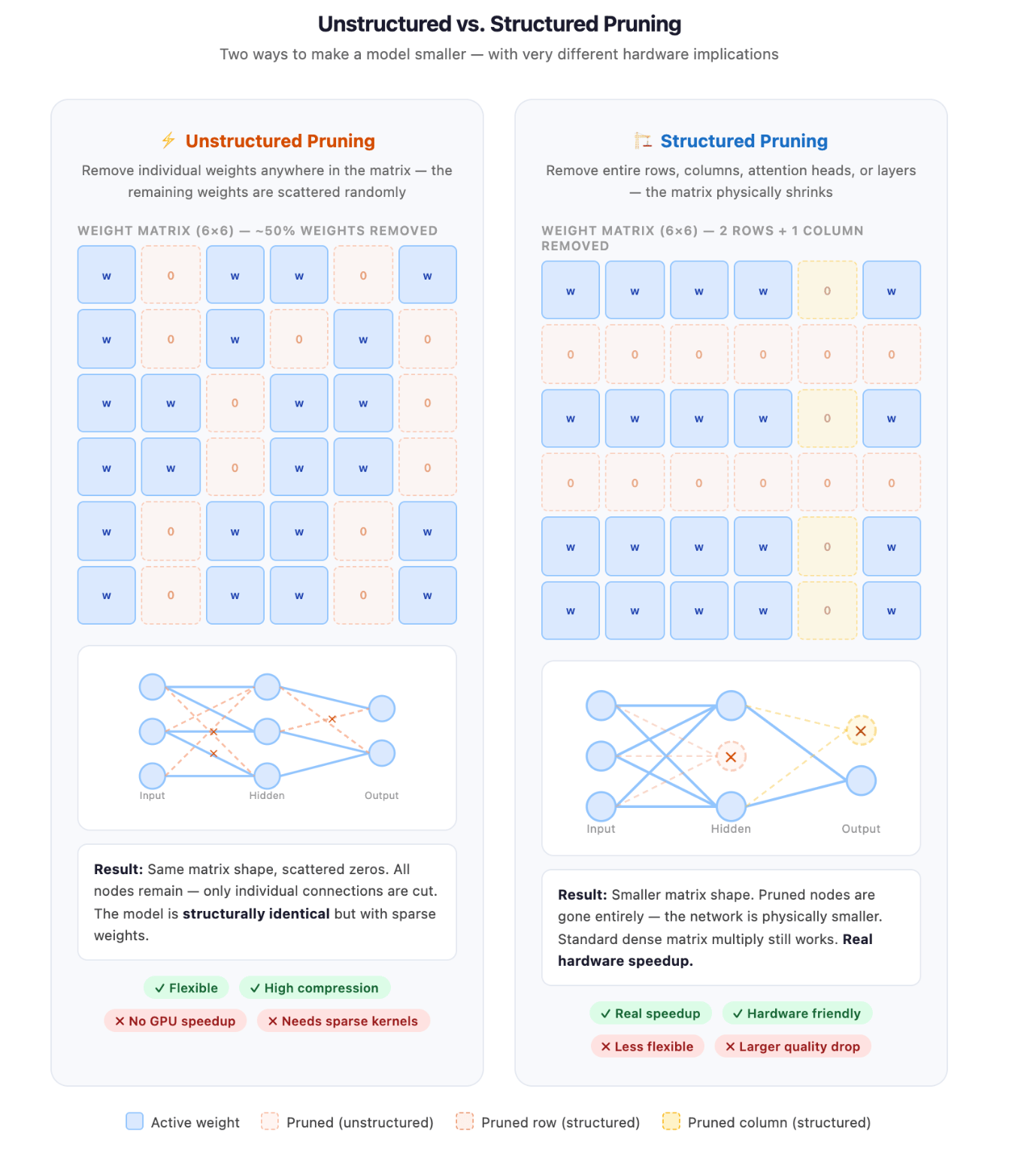
There are 2 fundamentally different ways to prune a model, and the favoritism matters enormously successful practice.
Unstructured pruning zeroes retired individual weights anyplace successful the network, sloppy of their position. You mightiness region 50% of each weights, but the survivors are scattered randomly crossed the weight matrices. The matrices still person the aforesaid shape; they’re conscionable sparse. This achieves fantabulous compression ratios and preserves value well, but the resulting sparsity is irregular.
Modern GPUs are optimized for dense matrix multiplication, and they don’t get faster conscionable because half the values are zero. Without specialized sparse kernels, unstructured pruning gives you smaller exemplary files but not faster inference.
Structured pruning removes full structural units specified arsenic afloat attraction heads, complete neurons, and full layers. The resulting exemplary is smaller successful shape, not conscionable successful values. Dense matrix multiplication still works, modular hardware still applies, and you get existent throughput gains. The tradeoff is that system pruning is little flexible: you’re forced to region things successful chunks, which tin wounded value much than removing the aforesaid number of individual weights successful the astir optimal positions.
The applicable rule: if you request faster inference, usage system pruning. If you request a smaller exemplary record and tin tolerate sparse compute, unstructured pruning gives amended quality-compression tradeoffs.
Magnitude Pruning
The simplest pruning method, and often a amazingly competitory one: region weights pinch the smallest absolute values. The logic is intuitive — a weight of 0.0003 multiplied against immoderate reasonable input is going to nutrient an output adjacent to zero. It’s not contributing much. Remove it.
Magnitude pruning useful champion erstwhile done iteratively: prune a mini fraction of weights, fine-tune concisely to fto the exemplary recover, prune again, fine-tune again. Repeating this rhythm gradually pushes the exemplary toward sparsity without ample value drops astatine immoderate azygous step. One-shot pruning, removing 50% of weights each astatine once, tends to wounded value importantly because the exemplary has nary chance to redistribute the activity done by removed weights.
The main weakness of magnitude pruning is that weight magnitude is simply a proxy for importance, not a nonstop measurement of it. A mini weight connected to a highly progressive neuron mightiness matter much than a ample weight successful a dormant pathway. More blase methods relationship for this.
Attention Head Pruning
Transformers usage multi-head attention to fto the exemplary be to different aspects of the input simultaneously. In theory, each caput captures a different relationship. In practice, investigation consistently finds that galore heads successful a trained transformer are redundant, immoderate heads be to astir identical patterns, and immoderate hardly activate connected immoderate input.
Studies connected BERT and GPT-family models person shown that 30–40% of attraction heads tin often beryllium removed pinch little than 1–2% degradation connected downstream tasks. In immoderate layers, you tin region astir each heads and suffer almost nothing.
The situation is figuring retired which heads to prune. Two communal approaches:
Gradient-based importance scoring runs the exemplary connected a calibration dataset and computes really overmuch each head’s output affects the last nonaccomplishment via its gradient. Heads pinch near-zero gradients aren’t influencing predictions and are safe to remove.
Taylor description scoring estimates the alteration successful nonaccomplishment caused by zeroing retired each head’s contribution, utilizing a first-order Taylor approximation. It’s much opinionated than axenic magnitude but computationally akin successful practice.
After identifying low-importance heads, they’re masked retired (set to zero) and the exemplary is fine-tuned concisely truthful remaining heads tin sorb the mislaid capacity. In practice, pruning 25–30% of attraction heads successful LLaMA-family models causes minimal value nonaccomplishment while meaningfully reducing the compute costs of attention, which scales quadratically pinch series length.
Layer Dropping and Depth Pruning
The astir fierce shape of system pruning removes full transformer layers. A 32-layer exemplary becomes a 24-layer model. Every furniture you driblet eliminates its attraction block, its MLP block, and each associated parameters, a clean, hardware-friendly reduction.
The cardinal mobility is which layers to drop. A useful awesome is the cosine similarity between a layer’s input and output: if a layer’s output is astir identical to its input, the furniture isn’t transforming the practice much, and it’s adjacent to an personality usability and tin beryllium removed pinch debased impact.
ShortGPT, a 2024 paper, formalized this into a metric called Block Influence (BI) and showed that applying it to models for illustration LLaMA-2 70B, you could region 25% of layers pinch little than 2% degradation connected astir benchmarks. The layers astir apt to beryllium redundant are typically successful the mediate of the web — early layers build foundational representations, precocious layers refine outputs, but mediate layers often incorporate important redundancy.
Layer dropping is besides utilized dynamically astatine conclusion time, a method called early exit, wherever the exemplary stops processing astatine an intermediate furniture erstwhile its assurance is already high. Easy inputs skip the later layers entirely; only difficult inputs usage the afloat network. This tin dramatically amended average-case latency without changing the model’s maximum capability.
SparseGPT and Wanda
Both GPTQ (from quantization) and magnitude pruning require either retraining aliases layer-wise optimization. For ample models, moreover a little fine-tuning tally is expensive. SparseGPT and Wanda are one-shot pruning methods designed specifically for LLMs — nary retraining required.
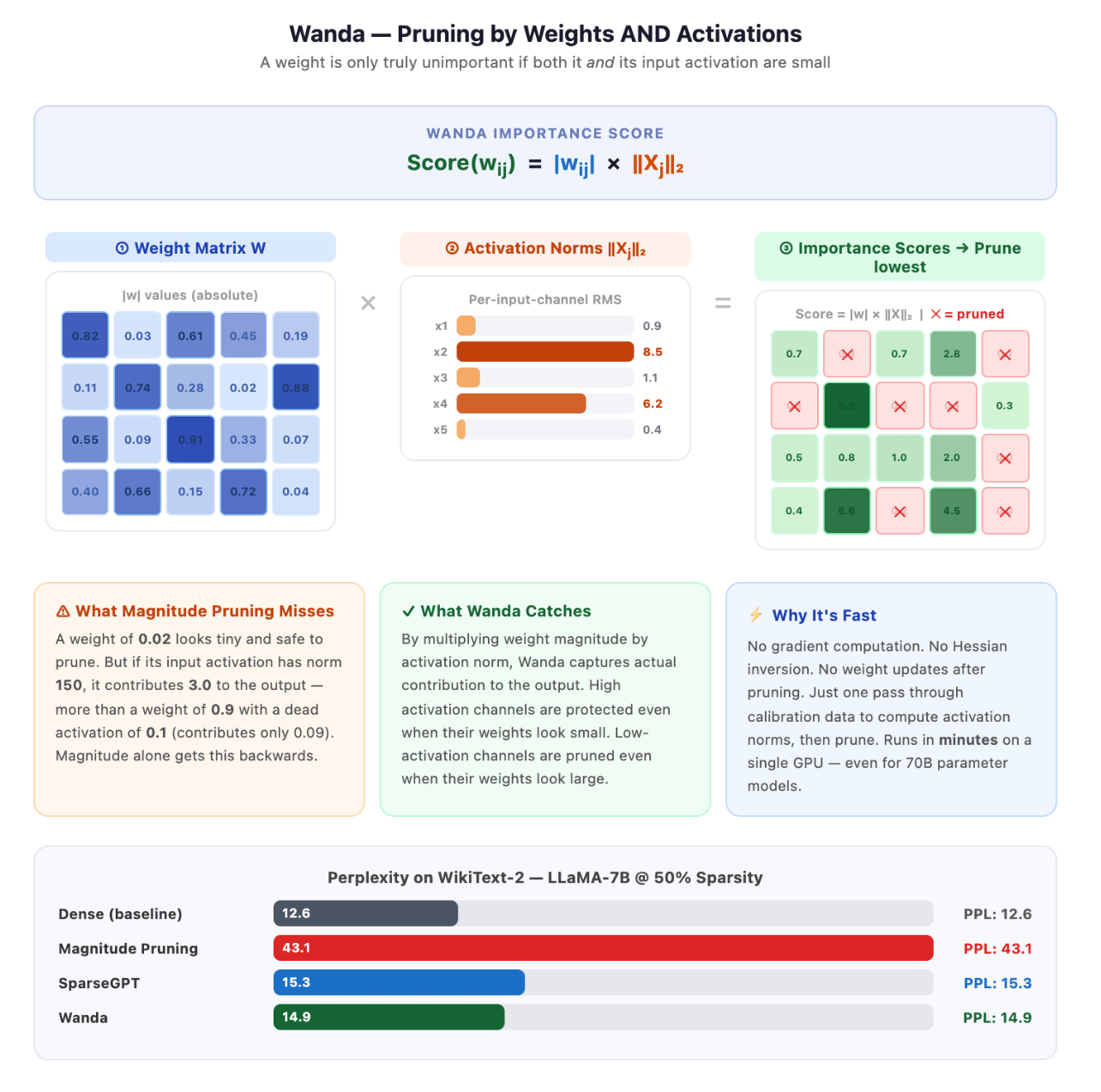
SparseGPT adapts the aforesaid second-order Hessian framework arsenic GPTQ, but for pruning alternatively of quantization. When a weight is pruned, SparseGPT computes a correction to the remaining weights successful the aforesaid furniture to compensate for the mislaid contribution, minimizing changes to the layer’s output. This lets it prune 50% of weights from a 175B parameter exemplary successful a fewer GPU-hours, pinch perplexity increases of little than 1 constituent connected WikiText-2. It besides supports mixed pruning + quantization successful a azygous pass.
Wanda (Pruning by Weights and Activations) takes an moreover simpler approach. Instead of second-order corrections, it scores each weight by multiplying its magnitude by the RMS of its corresponding input activation:
importance(w_ij) = |w_ij| × ||x_j||₂Weights pinch debased scores, mini magnitude, and debased activation are pruned. This captures thing magnitude pruning misses: a weight is only unimportant if both it and its input are small. A mini weight connected to a ample activation is still doing existent work. Wanda runs successful minutes, requires nary gradient computation, and often matches aliases thumps SparseGPT astatine 50% sparsity contempt being acold simpler.
To understand it successful a simpler way, Wanda, dissimilar accepted pruning methods that return attraction of the weight, Wanda besides considers really powerfully neurons are activated during inference. The main intuition is that if a neuron is getting activated, past that weight is still important.
Hence, Wanda combines weight magnitude and activation value to determine which weights to remove.
| Uses activations | Yes | Yes |
| Uses Hessian approximation | No | Yes |
| Speed | Very fast | Slower |
| Complexity | Simple | Advanced |
| Retraining needed | No | No |
| Accuracy retention | Very good | Better |
| Scalability | Excellent | Excellent |
Wanda became wide utilized because it tin prune immense models for illustration Meta LLaMA and Mistral to 50% sparsity successful minutes connected a azygous GPU, and that excessively pinch minimal value nonaccomplishment without retraining.
That is highly valuable for:
- GPU costs reduction
- Edge deployment
- Faster inference
- Lower VRAM usage
Our adjacent article will dive deeper into the specifics of these 2 methodologies.
The Hardware Reality
GPUs are designed for dense tensor operations. When half of a matrix is zeros, the GPU still processes the afloat matrix; it conscionable multiplies a batch of values by zero very quickly. The representation savings are existent (you tin shop sparse matrices much compactly), but the compute savings dangle wholly connected having sparse-aware kernels.
NVIDIA partially addressed this pinch 2:4 system sparsity connected Ampere and later architectures (A100, H100). The constraint is specific: for each group of 4 consecutive weights, precisely 2 must beryllium zero. This regular sparsity shape lets the hardware skip the zero multiplications efficiently. NVIDIA’s Sparse Tensor Core implementation achieves adjacent to 2x speedup connected sparse operations — but only if the sparsity shape satisfies the 2:4 constraint exactly. Unstructured sparsity gets nary of this benefit.
For CPU inference, things activity amended because libraries for illustration llama.cpp tin make amended usage of sparse models. CPUs are often constricted by really accelerated they tin load information from memory, truthful skipping zero weights intends little information needs to beryllium loaded, which tin amended performance.
FAQ’s
Do I request to retrain my exemplary aft quantization?
No, usually you do not request retraining. Techniques for illustration GPTQ, AWQ, and LLM.int8() tin quantize a pretrained exemplary straight utilizing a mini sample dataset. Retraining is chiefly needed erstwhile utilizing highly debased precision, for illustration INT3, aliases for tasks that require very precocious accuracy.
What’s the quality betwixt GPTQ and AWQ — which should I use?
Both are celebrated quantization methods utilized to make LLMs smaller and faster.
- GPTQ focuses connected reducing exemplary size while keeping accuracy arsenic adjacent arsenic imaginable to the original model. It useful furniture by furniture and is wide supported successful galore tools.
- AWQ (Activation-aware Weight Quantization) pays much attraction to important activations successful the model, which often helps sphere value better, particularly for chat and instruction-following models.
In elemental terms:
- Use GPTQ if you want wide compatibility and bully compression.
- Use AWQ if you attraction much astir maintaining consequence value and are moving conclusion connected modern GPUs.
Can I use some pruning and quantization to the aforesaid model?
Yes. In fact, galore optimized LLM pipelines usage some together.
- Pruning removes little important weights from the model.
- Quantization reduces the precision of the remaining weights.
Think of it like:
- Pruning = removing unnecessary parts
- Quantization = shrinking what is left
Combining them tin trim representation usage and amended conclusion velocity moreover more.
Will users announcement a quality pinch a quantized aliases pruned model?
Usually, not much, particularly pinch mean optimization.
For example:
- INT8 quantization often looks almost identical to the original model.
- 4-bit quantization whitethorn show mini value drops successful analyzable reasoning tasks.
- Heavy pruning tin sometimes make responses little meticulous aliases much repetitive.
Most users will not announcement changes for mundane tasks for illustration chatting, summarization, aliases coding assistance unless the optimization is very aggressive.
How do I cognize which layers are safe to prune?
You usually do not manually prime layers astatine random. Modern pruning methods analyze:
- Weight importance
- Activation patterns
- Sensitivity of each layer
In general:
- Attention and feed-forward layers often incorporate galore removable weights.
- Early and last layers are usually much delicate and should beryllium pruned carefully.
Tools for illustration SparseGPT and Wanda automatically determine which weights are little important.
Conclusion: The First Half
LLM conclusion is not conscionable 1 elemental method but includes a stack of techniques, and Part 1 of the article covered the first 2 techniques. Both quantization and pruning are important techniques for optimization. Some of that excess is numerical — weights stored astatine a precision they ne'er needed. Some of it is structural — heads, layers, and connections that lend marginally to outputs. Both forms of excess are recoverable without importantly sacrificing the model’s intelligence, and modern methods for illustration AWQ, GPTQ, Wanda, and SparseGPT make that betterment fast, practical, and progressively automatic.
A 70B parameter exemplary that would person required 8 A100s to tally successful FP16 tin now beryllium quantized to INT4, pruned of its astir redundant structure, and served from a two-GPU setup, pinch astir users incapable to show the difference.
But quantization and pruning only return you truthful far. They activity astatine the exemplary level — connected the weights themselves. The different half of the conclusion optimization communicative plays retired astatine the generation level: really tokens are produced, really representation is managed during a guardant pass, and really the inherently sequential quality of autoregressive decoding tin beryllium subverted.
That’s wherever Part 2 picks up.
In the adjacent article, we’ll screen Knowledge Distillation, training a mini exemplary to deliberation for illustration a ample one, the method that produced Phi, Mistral, and astir of the businesslike exemplary families you’re apt already using. Then, KV Caching, the representation guidance motor that makes serving long-context conversations astatine standard moreover possible, includes PagedAttention, grouped-query attention, and prefix reuse. And yet Speculative Decoding, the cleverest instrumentality successful the stack, wherever a mini draught exemplary guesses up truthful the ample exemplary tin verify aggregate tokens successful parallel, fundamentally changing the economics of latency-sensitive inference.
The exemplary you optimize successful Part 1 is the exemplary you service successful Part 2. Together, these techniques shape the complete image of really modern AI systems really run.
 This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.

.png "Efficient Llm Compression With Sparsegpt And Wanda On Gpu Cloud")






.png "How To Use The Javascript Fetch Api")
.png "How To Configure Php-fpm With Nginx")



") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·