Large connection model conclusion isn’t conscionable astir moving a model. It’s besides astir scheduling activity connected that model. When users nonstop prompts to an LLM app, the conclusion server must take which requests tally connected the GPU, which ones should support generating tokens, really overmuch KV cache memory to allocate, and really to equilibrium earthy throughput pinch user-facing latency.
This is wherever batching becomes important. Batching is the process of allowing the conclusion server to grip aggregate requests concurrently alternatively than moving them independently. Batched conclusion is elemental successful accepted instrumentality learning: cod respective inputs, tally them done the model, and return the outputs. Batching for LLM conclusion is much analyzable because each petition has 2 phases: The prefill shape processes the input punctual and creates the first KV cache. The decode shape generates output tokens measurement by step.
LLM requests tin person wide varying punctual lengths, output lengths, and presence times. This intends the measurement requests are batched has a ample effect connected performance. The 2 important approaches are static batching and continuous batching.
In this article, we analyse why batching matters, comparison fixed and continuous batching, explicate prefill/decode and iteration‑level scheduling, item really vLLM and TGI instrumentality continuous batching, and talk applicable implications and scenarios for some techniques.
Key Takeaways
- LLM conclusion capacity is simply a scheduling problem, not only a exemplary execution problem. The server must determine really to allocate GPU work, KV cache memory, prefill tasks, and decode steps nether existent traffic.
- Static batching is elemental but inefficient for variable-length LLM workloads. It waits for the slowest petition successful the batch, causing idle GPU slots, head-of-line blocking, higher TTFT, and wasted compute.
- Continuous batching improves throughput by updating the progressive batch astatine each procreation step. When 1 petition finishes, different waiting petition tin participate the batch, keeping the GPU amended utilized.
- vLLM improves continuous batching pinch PagedAttention and KV cache-aware scheduling. PagedAttention reduces KV cache fragmentation, while iteration-level scheduling helps vLLM admit caller requests arsenic resources go available.
- TGI remains useful, but vLLM is often the stronger prime for caller high-throughput deployments. TGI supports continuous batching and accumulation serving features, but Hugging Face now recommends alternatives specified arsenic vLLM aliases SGLang for early deployments.
Why Batching Matters successful LLM Inference
GPUs are designed for highly parallelized matrix operations. So dispatching requests together enables amended utilization. Without batching, each petition would propulsion the model’s weights, execute each its matrix multiplies and attraction operations, and merchandise the GPU promptly. This will origin important under‑utilization. By batching requests together, the server tin reuse the aforesaid loaded weights for aggregate requests, amortizing representation bandwidth and compute overhead.
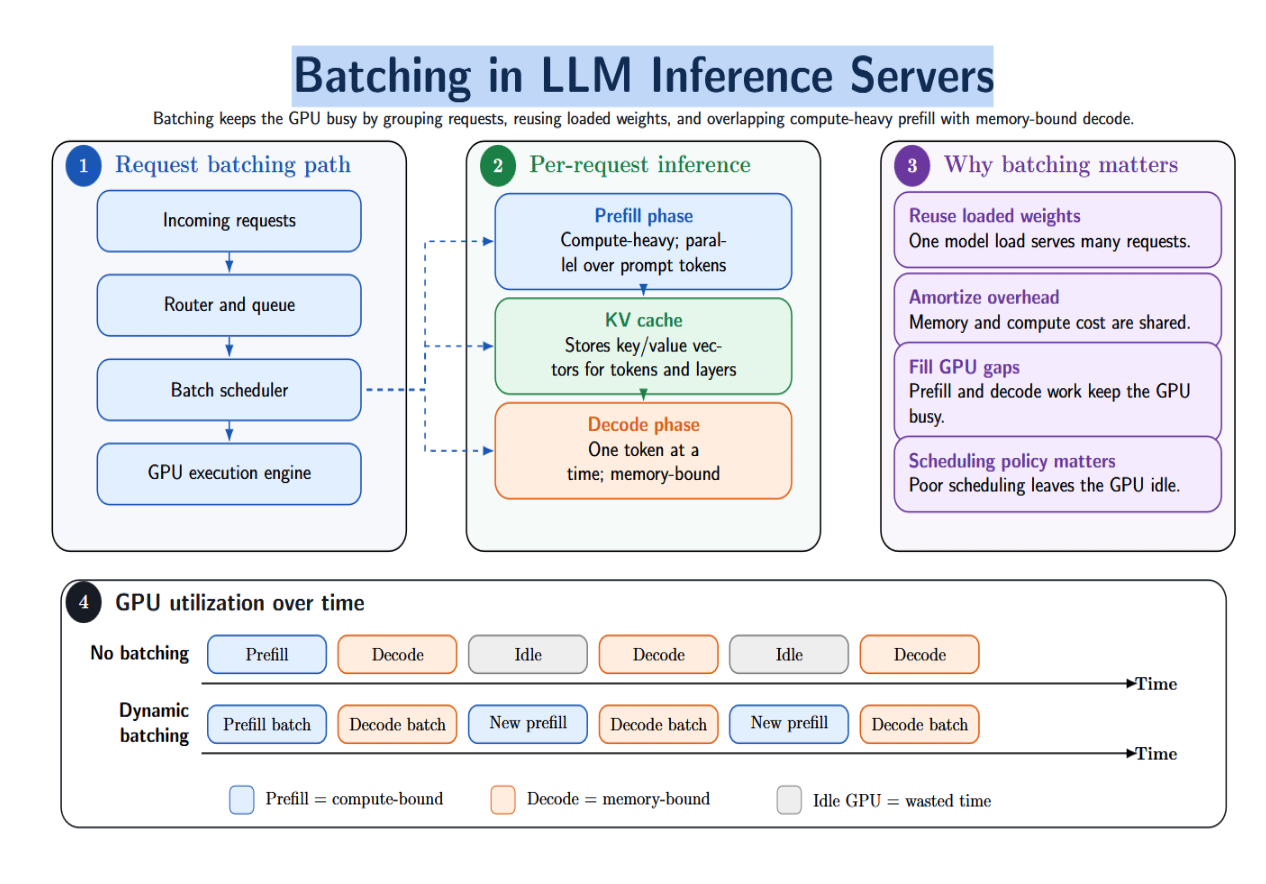
LLM inference isn’t batch matrix multiplication for illustration image classification. Each incoming petition consists of a prefill shape (which is compute‑heavy and highly parallelizable) and a decode shape (which is sequential and memory‑bound). During prefill, the exemplary looks astatine each token successful the punctual simultaneously and prepares the KV cache. The KV cache stores cardinal and worth vectors for each position successful each layer.
During decoding, the exemplary generates 1 token astatine a clip conditioned connected antecedently generated tokens and the KV cache. Prefill is compute‑bound, truthful parallelizing galore tokens simultaneously allows precocious GPU utilization. Decode, however, is memory‑bound and shows little GPU utilization. Batching helps overlap the gaps betwixt prefill and decode: prefill ops tin beryllium batched together, and aggregate decodes tin execute successful parallel. But the batch scheduling argumentation will find if the GPU sits astir idle while agelong sequences decorativeness decoding.
What Is Static Batching?
Static batching is the process wherever aggregate requests are batched together, prefilled, and decoded. They are past queued together and must hold for each petition successful the batch to complete earlier the adjacent batch tin start.
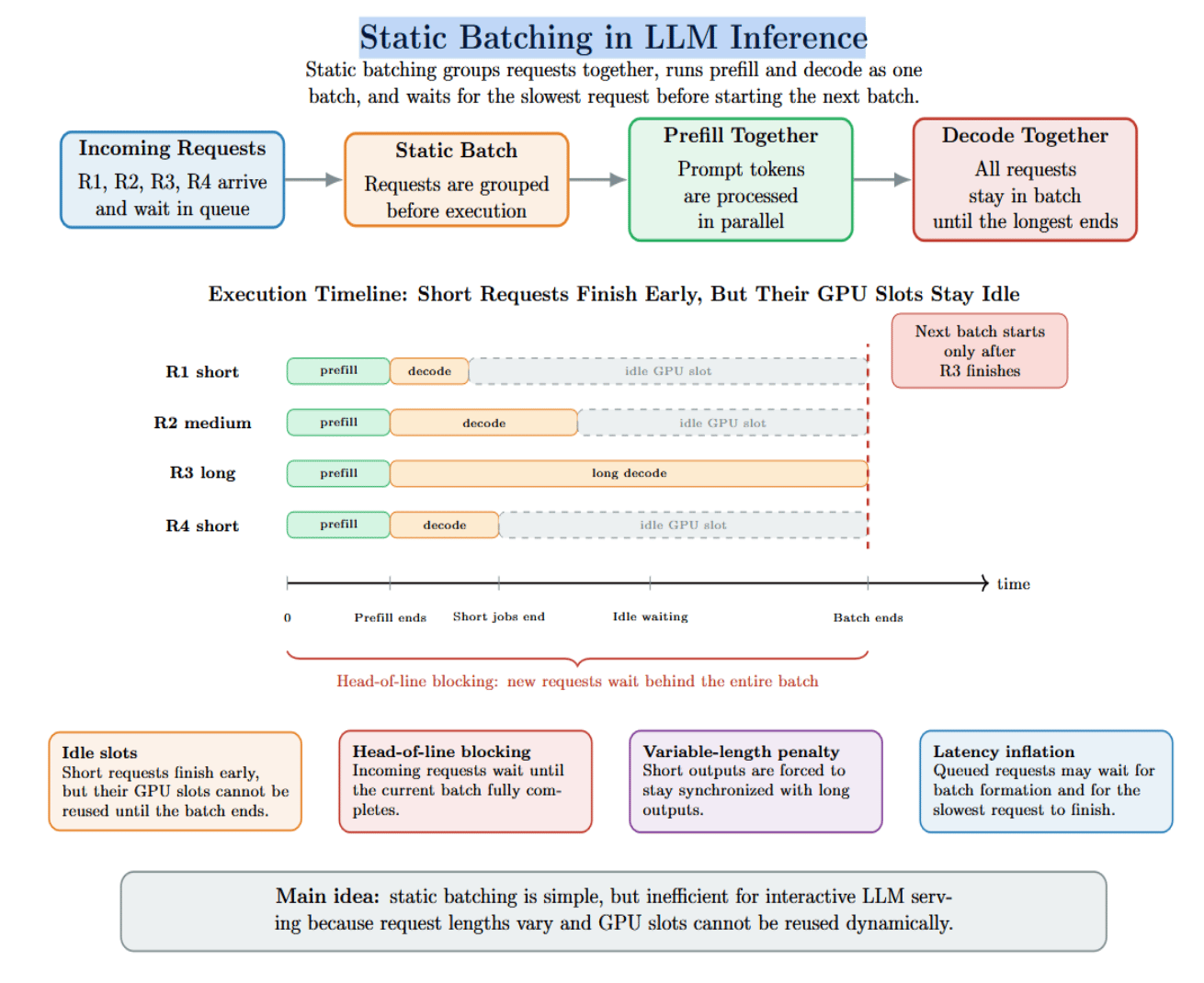
Think of fixed batching for illustration a autobus that won’t time off until everyone connected it has reached their destination. This sounds elemental enough, but it has immoderate inefficiencies:
- Idle slots: When immoderate requests complete early, their GPU slots stay idle until the slowest petition finishes.
- Head‑of‑line blocking: Incoming requests must hold until the full batch completes. This adds to the queueing delay.
- Variable‑length output penalty: Because LLM outputs are adaptable successful length, fixed batching causes shorter requests to beryllium stuck waiting for longer ones. This results successful wasted compute cycles.
- Latency inflation: Static batching tin summation TTFT for requests successful the queue because the batching process forces each batch to hold until it is afloat earlier starting, and past to hold until the petition taking the longest to complete finishes.
What Is Continuous Batching?
Continuous batching is achieved done iteration-level scheduling. Rather than locking a fixed batch until it completes generation, the server updates the existent progressive batch connected each procreation step. As soon arsenic a petition has vanished computing its last token, it is ejected from the progressive batch and replaced by 1 of the requests waiting successful the queue.
The cardinal benefits of continuous batching are:
- Higher GPU utilization: Empty slots near by completed sequences are instantly replaced, keeping the GPU busy.
- Lower queueing delay: New requests don’t person to hold for the full batch to complete earlier entering the pipeline. Instead, they tin queue up whenever slots go available.
- Better throughput: Thanks to reduced idle time, continuous batching tin present 2–4× higher throughput than fixed batching successful high‑concurrency workloads.
- Improved latency distribution: Long sequences nary longer artifact short ones, tightening the p95/p99 latency tail.
Recent releases of Hugging Face Transformers see documents for ContinuousBatchingManager and generate__batch for continuous batching. Leading conclusion frameworks for illustration vLLM, SGLang, TensorRT‑LLM, and LMDeploy supply continuous aliases in‑flight batching built in.
Static vs. Continuous Batching: Core Difference
The favoritism betwixt fixed and continuous batching tin beryllium summarized on respective dimensions. The array beneath provides a concise comparison.
| Scheduling unit | Fixed batch | Token iteration |
| Request admission | After the batch ends | When the slot opens |
| Batch behavior | Fixed until completion | Updated continuously |
| Blocking risk | High | Low |
| GPU utilization | Often underused | Better saturated |
| TTFT | Higher nether queues | Usually lower |
| Throughput | Limited by the slowest request | Higher pinch mixed lengths |
| Latency profile | Wider tail latency | Smoother tail latency |
| Best fit | Offline, azygous jobs | Online, adaptable traffic |
| Typical usage case | Batch evaluation | Chatbots, APIs, agents |
Prefill and Decode: The Two Phases Behind LLM Scheduling
To admit continuous batching, let’s reappraisal 2 phases of LLM inference. Large connection exemplary conclusion consists of 2 phases: prefill and decode. Prefilling ingests the full punctual successful a azygous guardant pass. During prefill, the exemplary computes attraction weights and feed-forward operations for each tokens successful parallel. Prefill is compute‑bound and has precocious GPU utilization. The results of prefill are stored successful the KV cache that stores cardinal and worth tensors for each furniture and token.
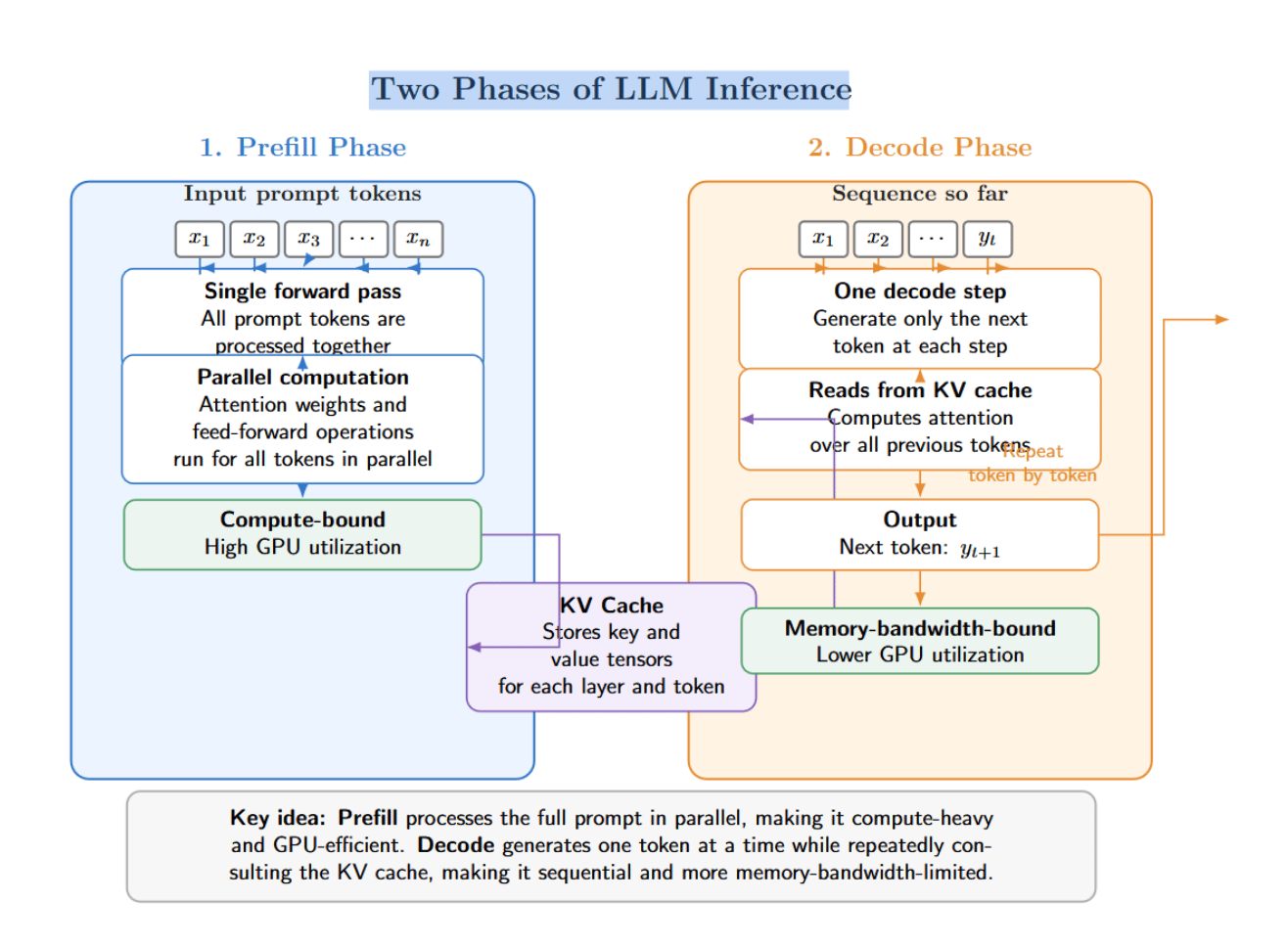
The decode shape generates 1 token astatine a time. Each measurement of decode sounds from the KV cache to compute attraction complete each antecedently generated tokens, past outputs the adjacent token. Because decode is inherently sequential and memory‑bandwidth‑bound, it has importantly little GPU utilization.
Prefill is expensive, but it occurs erstwhile per request. As a result, respective optimization strategies attraction connected reducing the costs of prefill, aliases amortizing it crossed requests. Prefix caching and chunked prefill are 2 examples. Prefix caching eliminates redundant activity by reusing prefill results betwixt shared strategy prompts and few‑shot examples. Chunked prefill breaks up ample prefill operations into smaller, independently executable chunks that tin beryllium interleaved pinch decode.
What Is Iteration‑Level Scheduling?
Iteration‑level scheduling is really continuous batching is achieved. Rather than constructing a fixed batch and moving until completion, the scheduler makes decisions astatine each guardant pass. Our scheduler maintains 3 queues: waiting (requests that person not started prefill), moving (requests that are presently decoding), and swapped (requests whose KV blocks person been evicted to big memory).
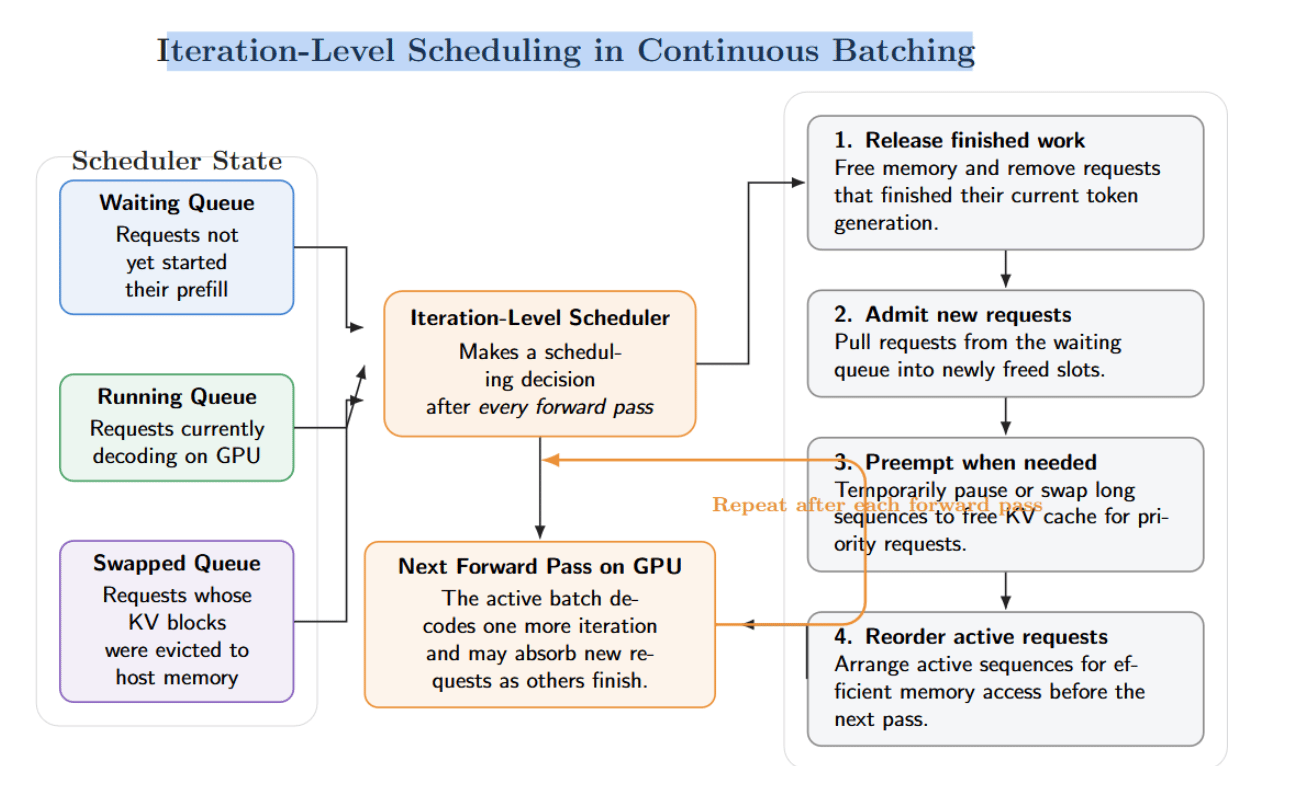
After each guardant pass, the scheduler will:
- Releases representation and removes requests that person vanished their existent token generation.
- Admits caller requests from the waiting queue into freed slots.
- Potentially preempt agelong sequences to free up KV cache for privilege requests.
- Reorders progressive requests for optimal representation entree earlier the adjacent guardant pass.
Iteration-level scheduling allows fine‑grained power complete what’s moving connected the GPU. This keeps GPU occupancy precocious and avoids longer sequences blocking the completion of shorter ones. In the vLLM/PagedAttention paper, vLLM improved serving throughput by 2–4× astatine akin latency compared pinch earlier serving systems specified arsenic FasterTransformer and Orca.
How vLLM Handles Continuous Batching
vLLM is an open‑source conclusion engine. It combines continuous batching and businesslike representation management, allowing for precocious throughput pinch debased latency. There are 2 nonaccomplishment modes successful naive LLM serving: KV cache fragmentation and fixed batching. Standard implementations reserve a contiguous representation artifact per petition adjacent to the maximum series length. This implies that 60–80% of the reserved KV cache representation could beryllium wasted successful that condition. Static batching besides leaves the GPU idle while short sequences hold for the longest batch to decorativeness processing.
vLLM addresses these issues pinch PagedAttention and continuous batching. PagedAttention implements the KV cache arsenic virtual memory: keys/values are stored successful non‑contiguous beingness pages (16 tokens each by default per block), which a page array maps a sequence’s logical KV cache onto.
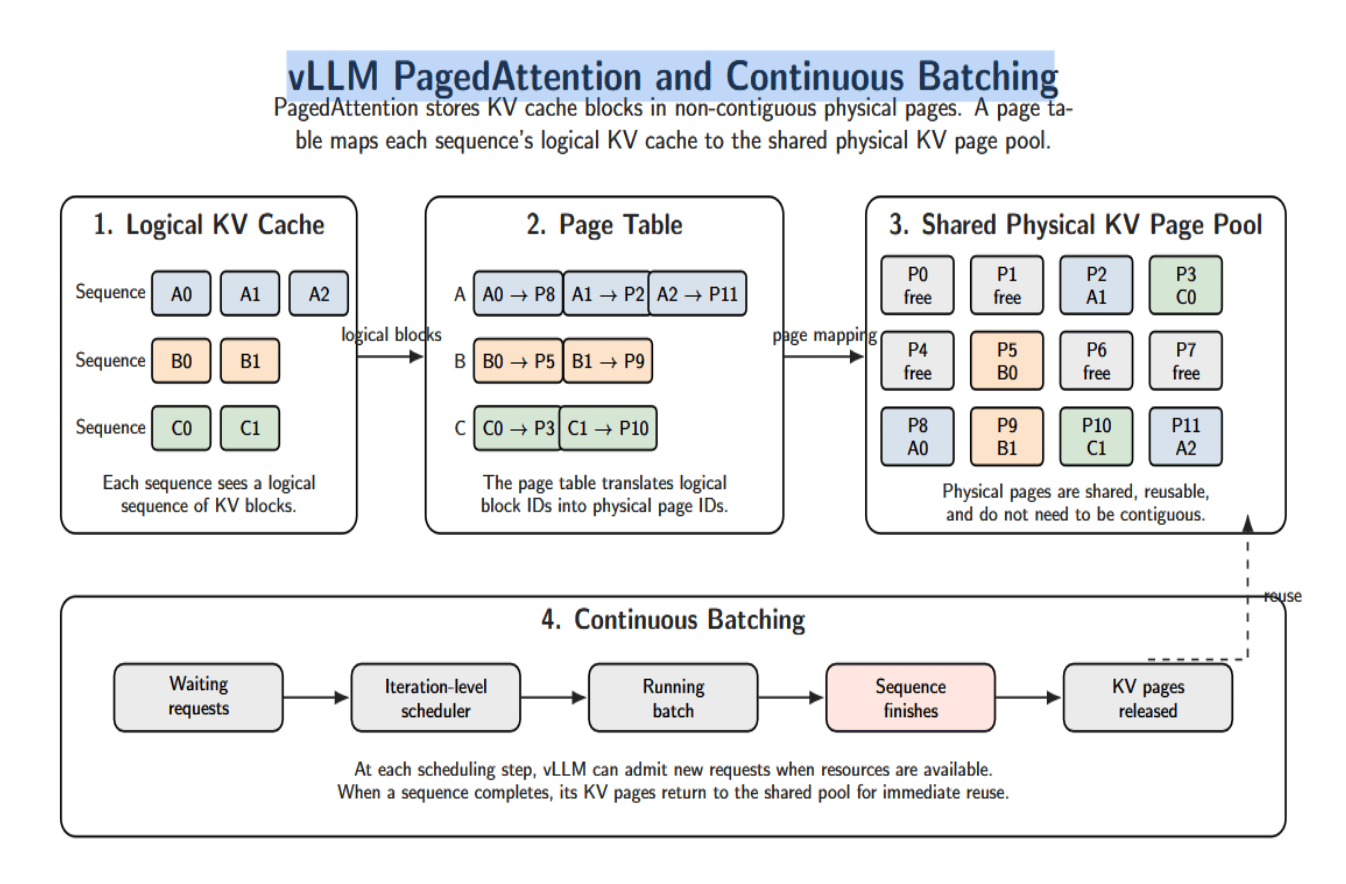
This attack removes soul and outer fragmentation and enables america to stock a azygous KV cache excavation crossed galore sequences. When a series completes, its blocks are released backmost into the excavation for contiguous reuse.
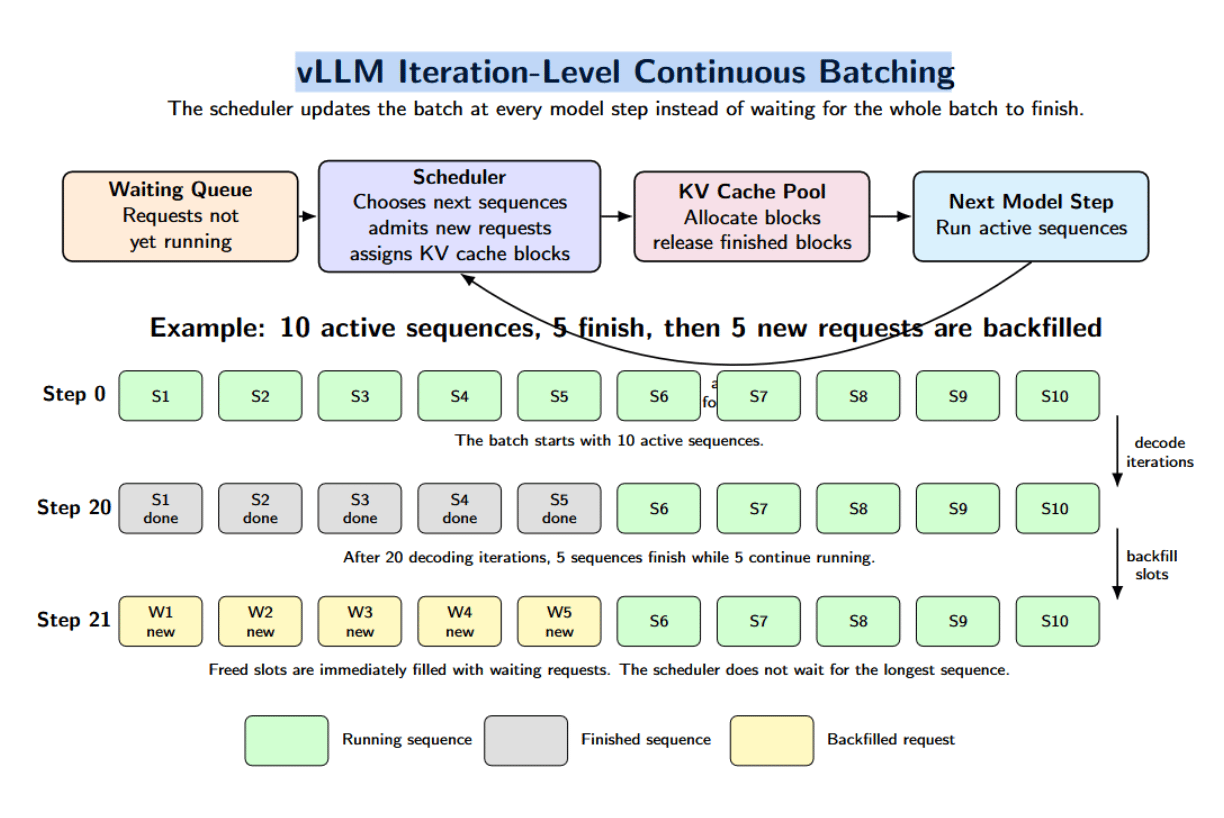
On the scheduling side, vLLM uses iteration-level continuous batching. The scheduler does not hold for an full batch to finish. Instead, it iteratively determines which requests to tally successful the adjacent exemplary step, admits requests erstwhile resources are available, and determines KV cache allocation for sequences presently being processed.
For instance, we whitethorn statesman a batch pinch 10 sequences, but only 5 of them decorativeness aft 20 decoding iterations. Instead of waiting for the longest series to complete, we tin backfill those slots pinch waiting requests successful the adjacent scheduling step. Additional optimizations successful vLLM’s optimization stack see PagedAttention, continuous batching, chunked prefill, prefix caching, speculative decoding, quantization, and CUDA graphs.
How TGI Handles Continuous Batching
Hugging Face Text Generation Inference has besides been utilized extensively for accumulation LLM serving. TGI supports continuous batching, streaming, tensor parallelism, quantization, and different production-ready serving features.
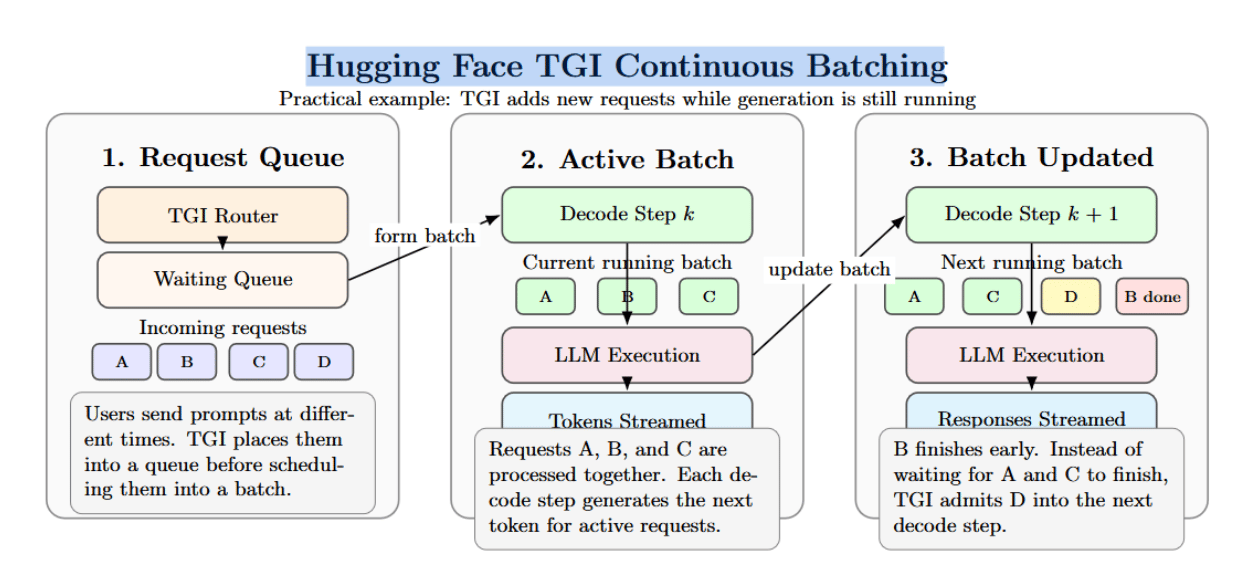
Incoming requests are routed into a queue, wherever they are dynamically grouped into batches for businesslike processing. This helps debar memory-related failures. TGI uses a continuous batching algorithm that tin dynamically adhd requests to a moving batch to maximize performance.
Hugging Face updated their docs to opportunity TGI is successful attraction mode. They propose utilizing conclusion motor options specified arsenic vLLM aliases SGLang for Inference Endpoints. If you presently person a moving deployment pinch TGI, that doesn’t abruptly make it useless. It still tin beryllium important for existent deployments. However, if you’re readying a caller high-throughput serving deployment, your squad whitethorn want to research whether vLLM aliases SGLang provides a much future-proof path.
Throughput Implications
Throughput refers to the magnitude of useful activity completed by the conclusion server per portion time. For LLM serving, this whitethorn beryllium measured successful tokens processed per second, requests per second, aliases generations completed per second.
Static batching tin limit throughput because the server is forced to hold for the slowest petition successful each batch. As shorter requests are completed, their batch slots whitethorn go inactive. The GPU whitethorn still tally the batch, but the magnitude of useful activity decreases.
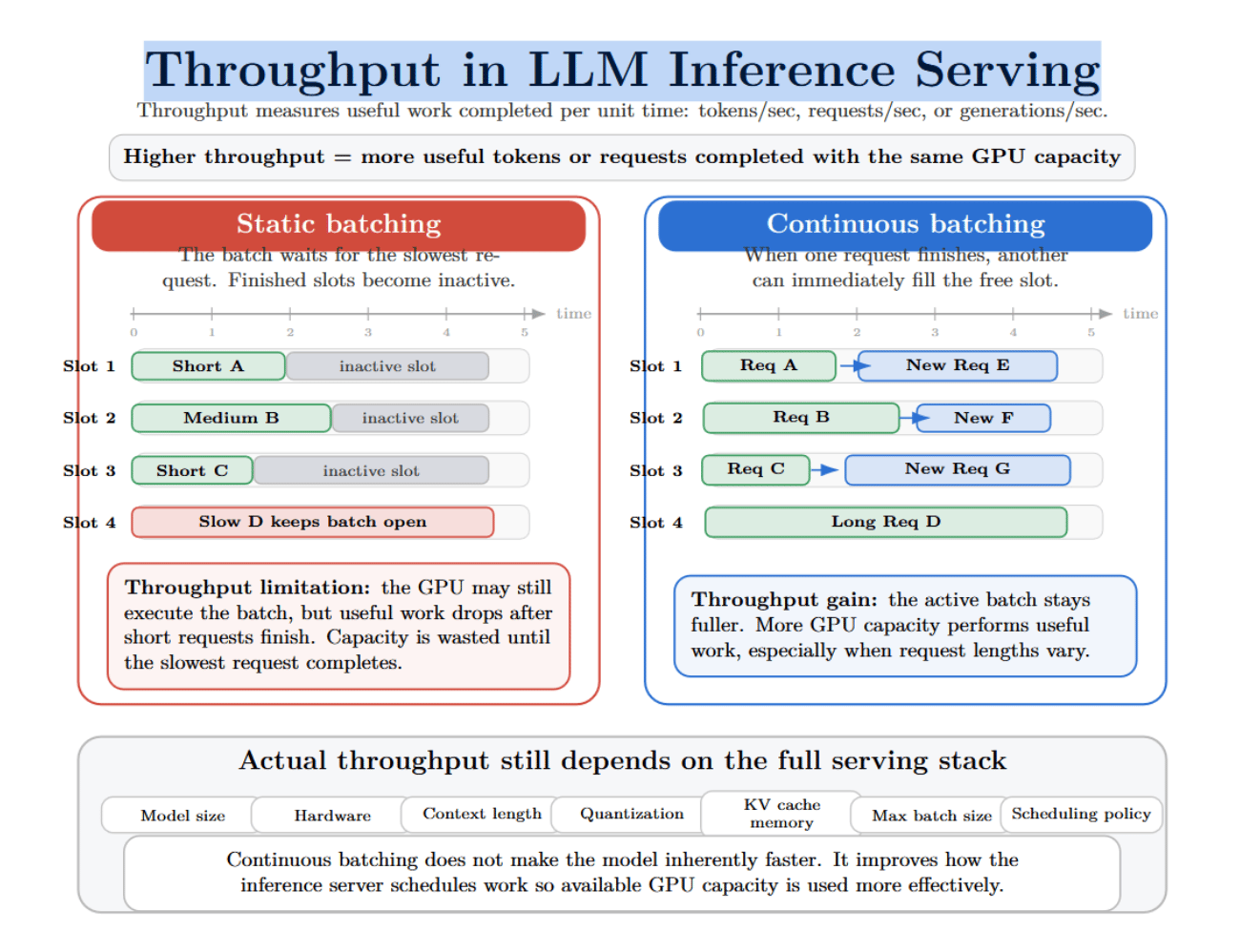
Continuous batching tin summation throughput by keeping the progressive batch fuller. As soon arsenic a petition ends, different tin commencement filling its slot. This improves GPU occupancy, reducing wasted clip connected the GPU. Continuous batching tin besides make it easier connected the server erstwhile requests person adaptable lengths.
Continuous batching optimizes really the server schedules activity truthful that disposable GPU capacity is utilized much effectively. Actual throughput will still alteration pinch exemplary size, hardware, discourse length, quantization method, KV cache footprint successful memory, max batch size, and scheduling policy.
Latency Implications: TTFT, TPOT, and Tail Latency
Latency is much subtle than throughput since latency tin beryllium knowledgeable otherwise by users. Let’s see the pursuing metrics:
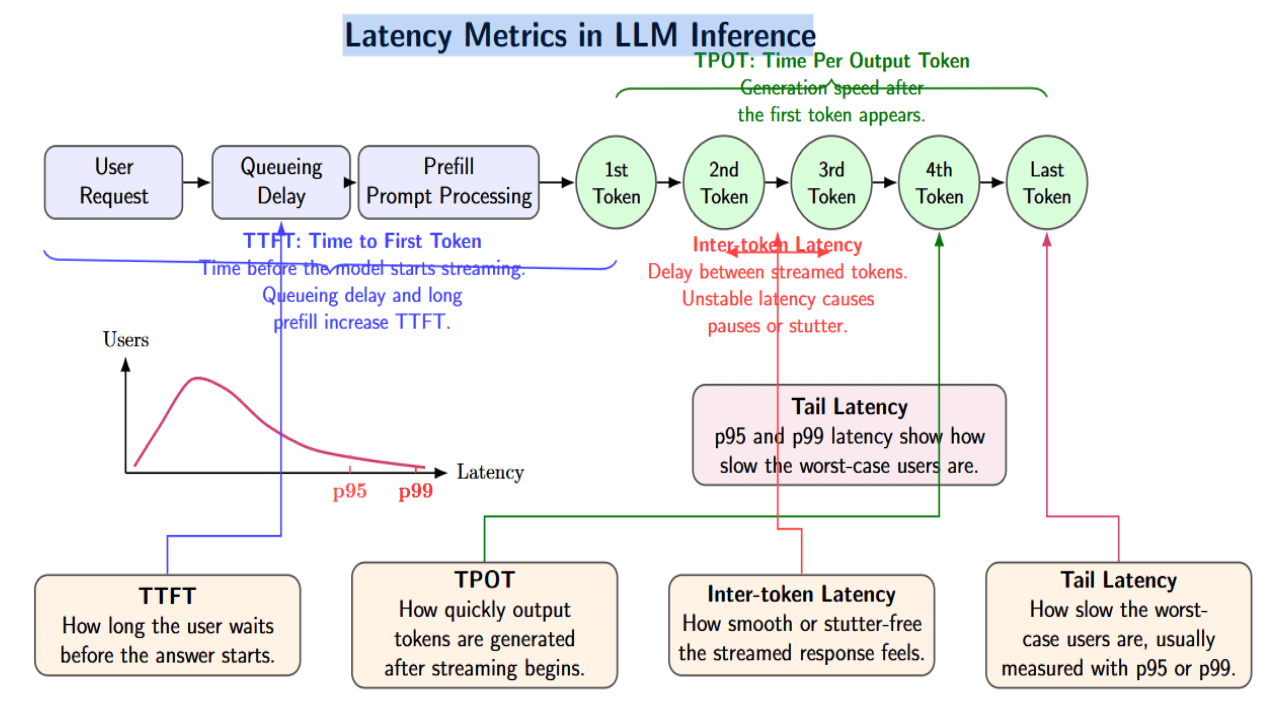
- TTFT, aliases clip to first token. It measures really agelong the users person to hold earlier the exemplary starts streaming their reply backmost to them. Queueing delays and agelong prefills some lend to a precocious TTFT.
- TPOT, aliases clip per output token. This measures the velocity pinch which tokens are generated aft the first token.
- inter-token latency. This refers to the hold betwixt streamed tokens. If inter-token latency is unstable, users whitethorn spot the reply region aliases stutter.
- Tail latency. It is often expressed arsenic p95 latency aliases p99 latency and shows really slow the worst-case users are.
Continuous batching tin trim TTFT by admitting caller requests sooner than fixed batching. But location is simply a tradeoff. If a scheduler aggressively inserts agelong prefills into the progressive batch, existing users whitethorn acquisition slower token streaming.
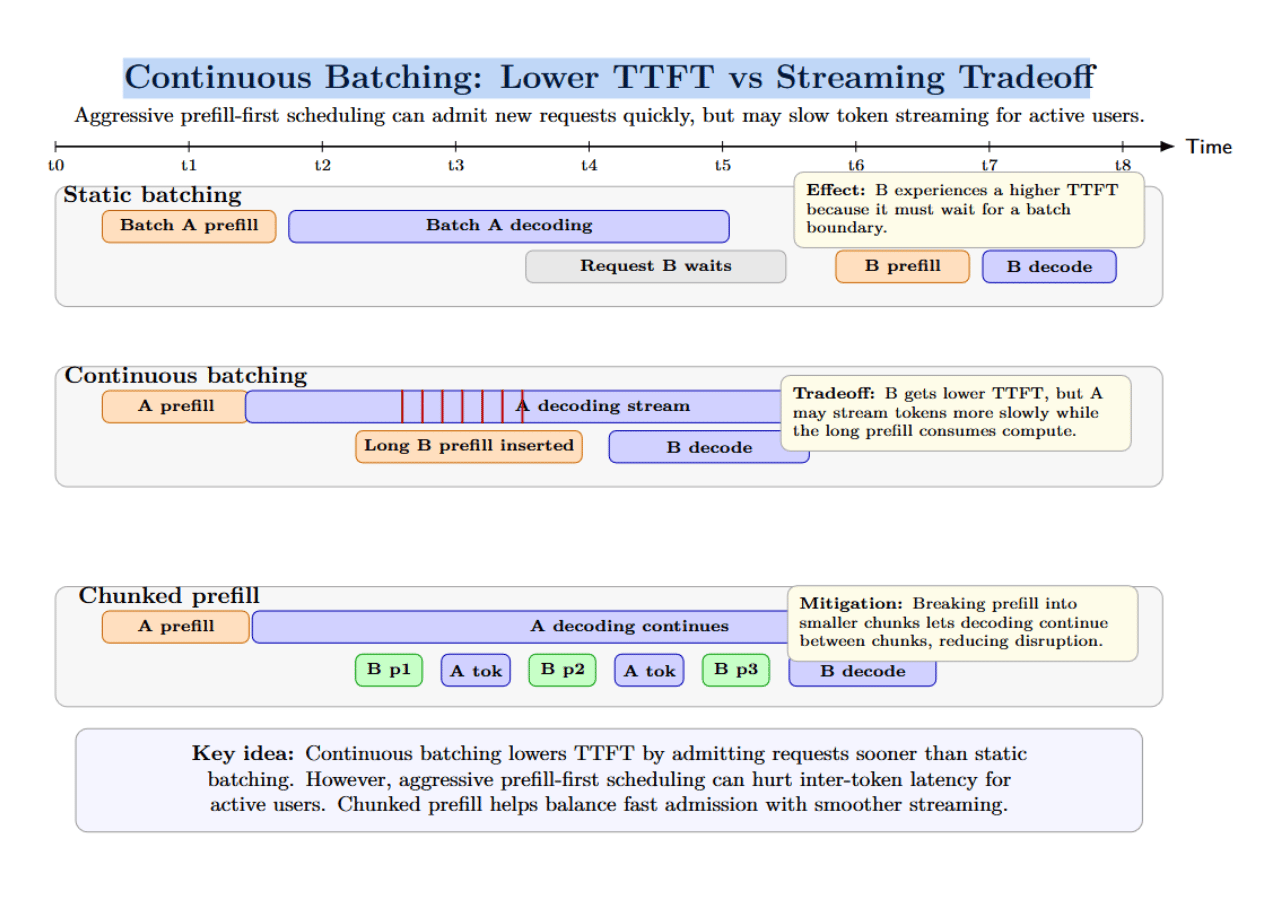
HuggingFace suggests: “prefill-first” scheduling strategies tin trim TTFT for incoming requests astatine the costs of slowing down aliases moreover interrupting decoding connected already-running requests; chunked prefill tin thief debar this rumor by breaking ample prefills into smaller units.
This is why the champion conclusion engines do much than continuous batching. They besides instrumentality chunked prefill, KV cache-aware scheduling, prefix caching, and observant queue management.
When Static Batching Still Makes Sense
Static batching is not ever wrong. It is good erstwhile your workload is predictable, and latency is not critical. Examples include:
- offline evaluation;
- synthetic benchmarks;
- batch archive summarization;
- translation jobs pinch akin input lengths;
- internal information processing pipelines;
- research experiments wherever reproducibility matters much than serving efficiency.
If requests are disposable successful beforehand and are comparatively azygous successful length, fixed batching tin beryllium easy and effective. There’s nary request to dynamically schedule.
When Continuous Batching Is Better
Continuous batching is champion for online, multi-user LLM serving.
It is particularly useful for:
- chat applications;
- coding assistants;
- AI agents;
- customer support bots;
- developer APIs;
- SaaS AI features;
- high-concurrency conclusion endpoints;
- streaming matter generation;
- workloads pinch adaptable punctual and output lengths.
Requests don’t get successful these environments successful convenient batches. They travel successful astatine different times and petition varying amounts of compute and memory. Continuous batching allows a server to accommodate to that reality.
When deploying these systems, operators shouldn’t ask, “Does my server support batching?” They should ask: “How does my server schedule prefill and decode activity nether existent traffic?”
vLLM vs. TGI: Which Should You Choose?
TGI and vLLM play complementary roles successful the LLM conclusion ecosystem. TGI pioneered galore features that made matter procreation practical, particularly for teams already invested successful Hugging Face tooling. TGI enabled continuous batching and different convenient serving features.
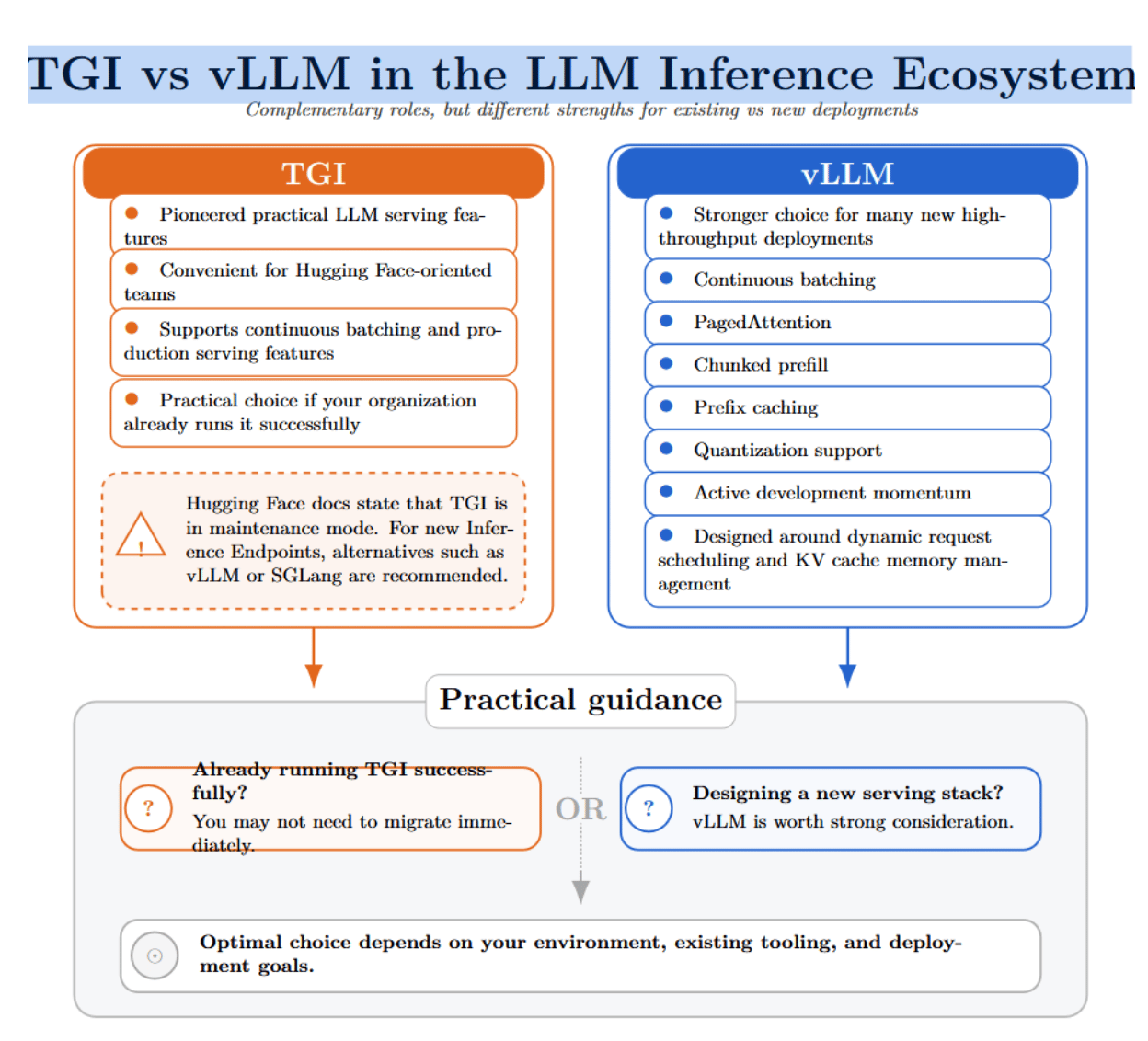
Typically, vLLM will beryllium the stronger prime for caller high-throughput deployments. vLLM offers continuous batching, PagedAttention, chunked prefill, prefix caching, quantization support, and progressive improvement momentum. vLLM is designed astir the 2 superior bottlenecks of LLM serving: move petition scheduling and KV cache representation management.
That being said, the optimal prime depends connected your circumstantial environment. If your statement is already moving TGI successfully, location whitethorn not beryllium a request to migrate away. However, if you are architecting a caller serving solution from scratch, we deliberation vLLM is worthy your consideration.
FAQ SECTION
1. What is the main quality betwixt fixed batching and continuous batching?
Static batching forms a fixed batch and waits until each requests finish. Continuous batching updates the progressive batch during procreation and admits caller requests arsenic soon arsenic capacity becomes available.
2. Why does continuous batching amended throughput?
It keeps GPU slots active. When 1 petition finishes, different petition tin participate the moving batch alternatively of waiting for the longest petition to complete.
3. Does continuous batching ever trim latency?
Not always. It tin trim queueing hold and TTFT, but mediocre scheduling of agelong prefills tin wounded inter-token latency for progressive users.
4. How does vLLM amended continuous batching?
vLLM combines continuous batching pinch PagedAttention, which manages KV cache representation efficiently utilizing block-based allocation. This helps the server fresh much progressive requests and trim representation waste.
5. Is TGI still relevant?
Yes, particularly for existing Hugging Face-based deployments. But Hugging Face archiving states that TGI is now successful attraction mode and recommends alternatives specified arsenic vLLM aliases SGLang for early Inference Endpoint deployments.
Conclusion
Continuous batching is 1 of the important LLMs conclusion serving optimizations. Static batching useful good if your postulation is predictable and well-behaved. Unfortunately, postulation seldom behaves for illustration this successful accumulation for LLM requests owed to differing punctual lengths, output lengths, and presence distributions. Static batching will wholly discarded GPU cycles waiting for the slowest petition to decorativeness successful a batch.
Continuous batching attempts to reside this by batching requests astatine the loop level. As requests finish, they postgraduate retired of the progressive batch, while incoming requests return their place. This keeps the GPU fed while improving throughput, slot utilization, and perchance reducing queueing hold knowledgeable by caller users.
However, batching is only 1 portion of the conclusion stack. Production-grade LLM serving besides requires businesslike KV cache management, chunked prefill, prefix caching, observability, quantization, and observant latency monitoring. vLLM and TGI some support continuous batching, but vLLM has go a stronger forward-looking action for galore caller deployments because of its operation of scheduling and representation optimizations.
The cardinal instruction is clear: successful LLM inference, capacity is not only astir the model. It is besides astir really intelligently the server schedules work.
 This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
")





")


.png "Why Serverless Inference Consistency Varies On The Same Model")





") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·