Introduction
Imagine you’re selecting an LLM for your application. You do extended investigation connected which exemplary will activity champion for your usage case. You mightiness research pinch it successful a sandbox utilizing DigitalOcean Serverless Inference, find it useful well, past perpetrate to different supplier for that exemplary to merge into your app. After pushing to production, the model’s accuracy, time to first token (TTFT), and throughput are each worse than you’d hoped. It was the aforesaid model, truthful what could person happened?
The reply is that models are not each treated arsenic crossed platforms. One level whitethorn dedicate their champion GPUs to 1 group of models, erstwhile different level focuses their champion hardware connected a different group of models. Even if the level offers a model, it whitethorn not person the basal resources down the scenes to make it production-worthy. Behind each API endpoint, providers are making a bid of infrastructure decisions, specified arsenic really galore replicas to support warm, what precision to service the exemplary at, which GPU tier to allocate, and really to prioritize petition queues. These decisions are seldom documented, and they alteration importantly from supplier to supplier and from exemplary to exemplary connected the aforesaid provider.
This article explains what providers really control, why exemplary fame shapes those decisions, and astir importantly, really to measurement it yourself earlier committing a exemplary and supplier operation to production.
The benchmark information successful this article comes from soul testing we conducted to validate these patterns. The supplier names are withheld, but the methodology is described successful capable item that you tin reproduce the aforesaid benignant of comparison yourself.
Key Takeaways
-
Serverless conclusion providers make galore undisclosed infrastructure decisions per exemplary including replica count, quantization, GPU tier, and batching strategy. All of these straight impact the latency and consistency you experience.
-
These decisions are mostly driven by perceived exemplary popularity. Popular models enactment warm, while niche aliases lower-traffic models cold-start much often and person little optimization investment.
-
The aforesaid exemplary tin behave for illustration a wholly different merchandise crossed providers. In our benchmarks, DeepSeek V4 Pro had a coefficient of variety (CV) of 21% connected 1 level and 710% connected another, accounting for a 34x quality successful consistency.
-
There is nary azygous “best” supplier for each models. Which models are well-supported varies by platform, and the only reliable measurement to find retired is to measure.
What Providers Actually Control
Most developers presume that if a exemplary is listed connected a provider’s platform, it is being served successful a standard, balanced way. It isn’t. Providers make respective decisions for each exemplary that compound to nutrient the latency and consistency you observe.
Replica Count and Warm Pool Size
Serverless conclusion useful by dynamically allocating GPU capacity to grip incoming requests. Popular models pinch consistent, high-volume postulation warrant keeping aggregate unrecorded replicas (GPU instances pinch the exemplary already loaded and fresh to serve) sitting idle astatine each times. When a petition arrives, it routes instantly to an disposable replica.
Less celebrated models whitethorn person zero lukewarm replicas extracurricular of highest periods. When a petition arrives for a acold model, the supplier must allocate a GPU, load the exemplary weights from storage, initialize the serving runtime, and past grip the request. For a ample connection model, this process tin return anyplace from 10 to 90 seconds depending connected exemplary size, retention location, and infrastructure. This is simply a acold start.
Cold starts are the superior driver of the high-variance latency patterns we talk later. A exemplary whitethorn person a median TTFT of 0.4 seconds, because astir requests deed a lukewarm replica, but a 95th percentile (p95) that exceeds 6 seconds because astir 1 successful 20 requests triggers a acold start. Median measurements will not uncover this.
Quantization
The aforesaid exemplary weights tin beryllium served astatine different numerical precisions. Full-precision serving (BF16 aliases FP16) uses the astir representation but preserves the original weights exactly. FP8 and INT8 trim representation footprint astir successful half pinch minimal value degradation for astir tasks. INT4 quantization cuts representation further but tin nutrient measurable value differences connected reasoning-heavy benchmarks.
Providers take quantization levels based connected their optimization finance successful each model. Popular models often person observant quantization tuning, choosing the precision that maximizes throughput per GPU while preserving output quality. Niche models whitethorn beryllium served astatine immoderate precision was easiest to configure erstwhile they were onboarded.
Quantization affects capacity successful 2 ways. Lower precision enables much replicas per GPU (reducing acold commencement frequency) and enables faster matrix operations (reducing TTFT erstwhile a replica is warm). Providers seldom people which precision they usage for a fixed model.
GPU Hardware Allocation
Not each GPUs are equal. H100s, A100s, and AMD MI300Xs person meaningfully different representation bandwidth and compute throughput. A exemplary served connected an H100 NVL versus an A100 80GB tin show 2-3x TTFT differences for identical workloads. Providers whitethorn way different models to different GPU tiers based connected demand, disposable inventory, and the economics of that model’s postulation volume.
Inference Engine and Kernel Optimization
How a exemplary is really executed matters arsenic overmuch arsenic the hardware it runs on. vLLM, TensorRT-LLM, SGLang, and custom-built kernels nutrient meaningfully different throughput and latency profiles for the aforesaid exemplary weights. Additional techniques for illustration speculative decoding, which uses a mini draught exemplary to foretell aggregate tokens up of the main model, tin trim TTFT significantly, but requires definitive configuration investment. Each supplier makes these choices independently, which is why the aforesaid exemplary tin execute very otherwise crossed platforms.
Request Queue Priority and Batching
Under load, providers batch aggregate requests together to amended GPU utilization. Popular models pinch steady, predictable postulation batch efficiently. Requests get astatine regular intervals, queues enactment shallow, and batching adds minimal overhead. Niche models pinch sparse, bursty postulation batch poorly. A petition for a rarely-used exemplary whitethorn queue down batches for celebrated models, adding latency that looks indistinguishable from cold-start noise.
The Compounding Effect
These decisions don’t run independently. A niche exemplary mightiness beryllium served astatine a blimpish precision level, connected an older GPU tier, without speculative decoding, pinch nary lukewarm replicas, and pinch mediocre batching efficiency. Each facet adds latency individually, and each of them stack. The consequence is simply a exemplary that whitethorn trial acceptably during a little evaluation, moreover connected the aforesaid platform, but fails successful production.
Why Popularity Drives These Decisions
Serverless conclusion providers run connected bladed GPU margins. Capacity is expensive, and pre-allocating lukewarm replicas for each exemplary successful a 400-model catalog is not economically feasible. The allocation determination is straightforward. They put profoundly successful models that make consistent, high-volume postulation and trim finance successful models that beryllium idle astir of the time.
Catalog size amplifies this effect. When a comparatively mini supplier lists 400 models, only a fraction of those are backed by optimized, lukewarm serving infrastructure. The remainder are disposable successful the consciousness that the weights are coming and tin beryllium loaded, but the acquisition of utilizing them astatine debased postulation volumes whitethorn beryllium very different from utilizing a well-supported flagship model.
Crucially, each supplier makes these bets independently. While 1 supplier whitethorn person invested profoundly successful DeepSeek V4 Pro, different supplier has done the aforesaid for Kimi K2.6. The catalog pages look identical pinch a exemplary name, a value per token, an API endpoint, but the infrastructure decisions down them are wholly different. A exemplary being disposable connected a level is not a awesome of really good that level supports it.
What Internal Testing Revealed
We ran these tests from a DigitalOcean Droplet successful NYC1 utilizing a streamed benchmark harness, fixed prompts, and temperature=0 truthful the comparison stayed focused connected supplier behaviour alternatively than punctual variance. Each model-provider compartment utilized astatine slightest 75 sequential requests astatine concurrency=1, pinch warmup requests discarded, and the runs were dispersed complete a fewer hours truthful we could observe some emblematic and off-peak behavior.
If you tally a system benchmark crossed providers measuring clip to first token (TTFT) astatine concurrency=1, you will spot the differences. Rather than comparing only medians, usage the coefficient of variety (CV%), modular deviation divided by mean, arsenic the superior awesome for consistency. A debased CV intends predictable latency. A precocious CV intends the exemplary is sometimes accelerated and sometimes very slow, which is the fingerprint of acold starts and queue variability.
Finding 1: The Same Model Will Behave Differently connected Different Providers
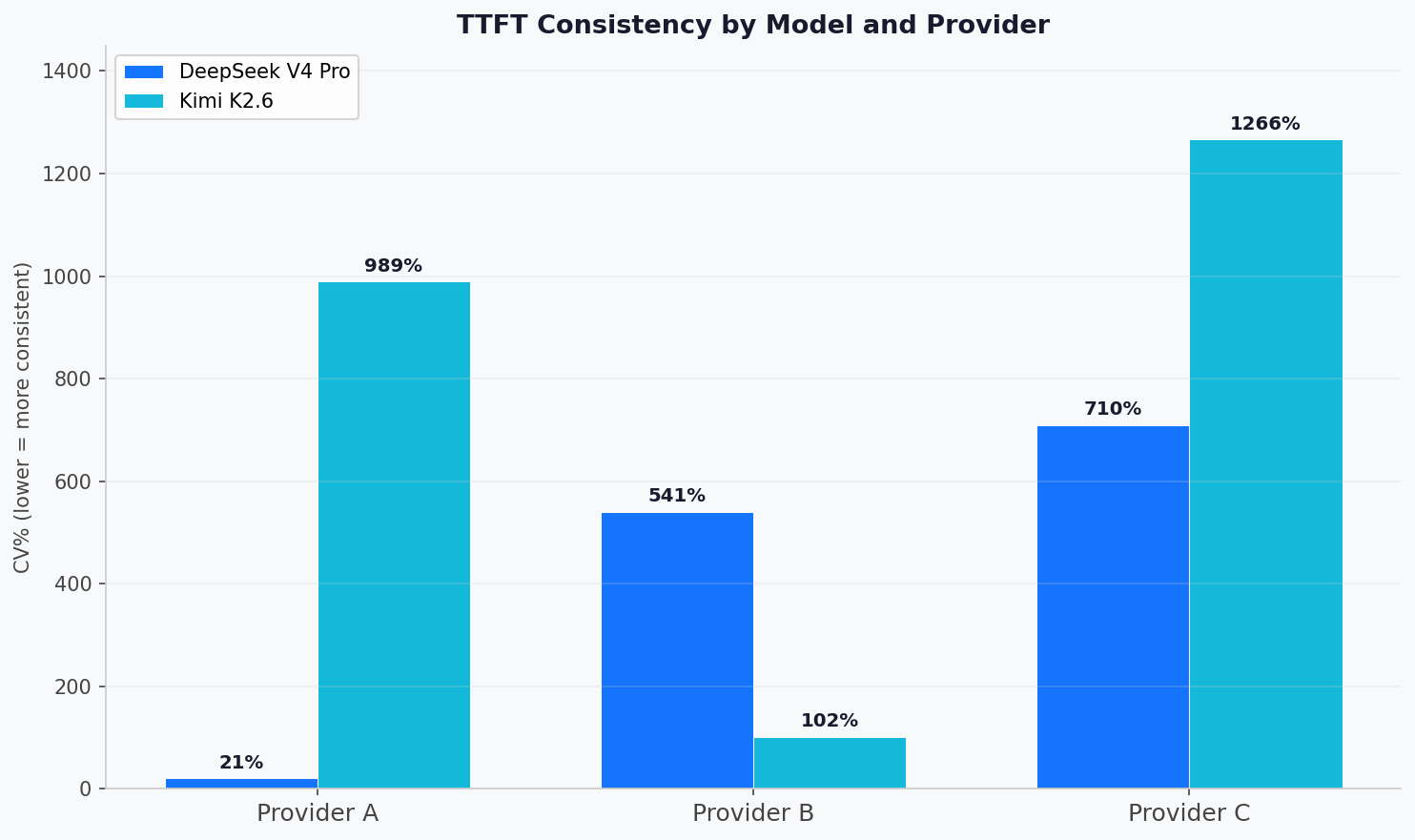
DeepSeek V4 Pro is simply a widely-used exemplary pinch beardown coding and reasoning performance. In our testing, the best-performing supplier for DeepSeek V4 Pro showed a CV of 21%, implying tight, predictable latency pinch a median TTFT of 0.39 seconds and a p95 of 0.57 seconds. A 2nd supplier showed a CV of 541%: median 0.55 seconds, p95 of 6.3 seconds. A 3rd supplier showed a CV of 710%: aforesaid model, median 0.73 seconds, p95 of 6.9 seconds.
| A | 0.39 s | 0.57 s | 21% |
| B | 0.55 s | 6.30 s | 541% |
| C | 0.73 s | 6.91 s | 710% |
A developer who evaluated DeepSeek V4 Pro connected 1 supplier and past deployed connected different supplier would acquisition accumulation latency that looks wholly broken, moreover though thing changed isolated from the routing.
Finding 2: There Is No Universal “Best” Provider
Kimi K2.6 tells the other story. On 1 provider, the CV was 989%: median 0.35 seconds, p95 of 5.98 seconds. On a 2nd provider, the CV was 1266%: median 0.43 seconds, p95 of 1.70 seconds but pinch utmost outliers driving a modular deviation of 5.4 seconds. On the supplier that supported it best, the CV dropped to 102%: median 0.25 seconds, p95 of 1.08 seconds, which is astir 10x much accordant than connected the different 2 platforms.
| A | 0.35 s | 5.98 s | 989% |
| B | 0.25 s | 1.08 s | 102% |
| C | 0.43 s | 1.70 s | 1266% |
In our testing, the best-supported supplier for DeepSeek V4 Pro was the correct prime for that model, while a different supplier was the correct prime for Kimi K2.6. Both conclusions require measurement. You cannot publication either 1 from the catalog pages.
Finding 3: Breadth-First Providers Require More Thorough Validation
A comparatively mini supplier that lists hundreds of models cannot put arsenic successful each of them. The infrastructure economics don’t let it. A curated catalog implies deliberate choices astir what to support well. A wide catalog implies the opposite. Many models are listed because they tin beryllium loaded, not because they person been optimized.
The information reflects this. For Kimi K2.6, breadth-first providers show CV benchmarks of 989% and 1266%. A curated supplier showed CV of 102%, astir 10x much consistent. For DeepSeek V4 Pro, 1 supplier had invested heavy and showed CV of 21%, while different had not and showed CV of 710%.
With a curated provider, a exemplary being listed is simply a reasonably beardown awesome that it has been deliberately provisioned. With a breadth-first provider, a exemplary being listed tells you almost thing astir the value of support down it. The catalog page looks identical whether the exemplary has 3 lukewarm replicas aliases zero.
That does not mean breadth-first providers are worse overall. For models they person intelligibly invested in, they tin beryllium the champion action available. But the variance successful support value crossed their catalog is higher, which intends the validation load connected you is besides higher. You cannot presume a exemplary is well-supported conscionable because it appears successful a 400-model catalog. You person to check.
The high-CV results are not noise. A CV supra 100% intends the modular deviation exceeds the mean. In practice, this indicates a bimodal distribution pinch a cluster of accelerated requests (warm replica) and a tail of very slow requests (cold start). Median measurements unsocial will not observe this. If you measure a exemplary by firing 10 requests and taking the average, you whitethorn ne'er deed a acold commencement astatine all.
How to Benchmark Before You Commit
Good benchmarks return astatine slightest a fewer hours to run. Here is simply a minimal attack that will show you everything you request to cognize astir a model/provider operation earlier building connected it.
What to measure: Time to first token (TTFT), not end-to-end latency. TTFT isolates whether the exemplary is lukewarm and ready, independent of procreation length. It is the astir nonstop awesome of infrastructure support.
How galore requests: At slightest 75. Ten to 20 requests will show you the median but not the tail. Cold starts are uncommon capable that a 20-request benchmark whitethorn miss them entirely. At 75 requests, you will almost surely brushwood a acold commencement if the exemplary is prone to them.
Prompt consistency: Either usage prompts that bespeak your usage lawsuit accurately aliases usage a fixed short punctual crossed each requests. This eliminates prompt-length variance from the results and keeps the comparison cleanable crossed providers.
Timing: Space requests a fewer seconds apart. This avoids artificially benefiting from petition batching. You want to observe the model’s behaviour nether typical single-request conditions, not sustained throughput.
What to compute: Median TTFT, p95 TTFT, modular deviation, and CV%. Median and p95 together show you the normal acquisition and the tail. CV% is the azygous astir useful awesome for comparing consistency crossed providers.
CV% thresholds arsenic a speedy guide:
- CV < 40%: well-supported, the supplier has this exemplary lukewarm and optimized.
- CV 40-100%: immoderate variability, acceptable for latency-tolerant workloads.
- CV > 100%: acold starts are occurring, measure whether p95 is acceptable for your usage case.
- CV > 300%: Treat arsenic not production-ready connected this supplier for latency-sensitive applications. Consider a dedicated endpoint.
Timing matters: Run benchmarks astatine some highest and non-peak hours (early morning, weekends). Cold-start behaviour is worst erstwhile postulation to the exemplary is lowest. A benchmark tally during business hours whitethorn show artificially bully results because different users person been keeping the exemplary warm.
Common Questions From the Data
Does this mean serverless conclusion is unreliable?
Not universally. Serverless conclusion is highly reliable for well-established models pinch accordant postulation connected a fixed provider. The reliability interest is circumstantial to models wherever the supplier has not made that investment, sloppy of really well-supported that aforesaid exemplary is elsewhere.
How do I debar this problem entirely?
Dedicated endpoints destruct cold-start consequence by giving you reserved GPU capacity for your model. The economics only make consciousness astatine consistent, predictable postulation volumes. Dedicated capacity costs the aforesaid whether you usage it aliases not, but the latency predictability is complete. If you person identified a exemplary you want to usage successful production, a dedicated endpoint connected the supplier that champion supports it is the astir reliable path.
Does the supplier pinch the largest exemplary catalog person the champion support?
No. Catalog size is inversely related to mean support depth. A supplier listing 400 models cannot put arsenic successful each of them. Smaller, much curated catalogs often bespeak deliberate choices astir which models to support well. Catalog size tells you astir breadth. Only measurement tells you astir depth.
Should I usage the aforesaid supplier for each my models?
Not necessarily. As the DeepSeek V4 Pro / Kimi K2.6 inversion shows, different providers person invested successful different models. If you are utilizing aggregate models successful production, the champion supplier for each exemplary whitethorn beryllium different. Routing requests to different providers per exemplary adds architectural complexity, but the latency and reliability benefits tin beryllium important for models wherever supplier support varies widely.
Conclusion
Serverless conclusion catalogs are not level lists of equivalently-supported models. They are gradual systems, pinch models each supplier has chosen to put successful receiving lukewarm replicas, optimized quantization, and dedicated engineering attention, while different models stock immoderate capacity is near over. The tiers are implicit, undocumented, and different connected each platform.
The applicable consequence is that exemplary information and supplier information are 2 abstracted decisions. You tin measure exemplary value connected immoderate supplier pinch a fistful of requests. But earlier committing a exemplary and supplier operation to production, you request to measurement consistency specifically, including p95 latency, not conscionable median, crossed capable requests to expose cold-start behavior.
This is simply a comparatively short experiment. The benchmarks successful this article took a fewer hours to tally and surfaced differences that would person costs days of accumulation debugging. Run the numbers earlier you build connected them.
-
Metrics That Matter pinch Serverless Inference
-
LLM Inference Optimization 101
-
LLM Inference Optimization: Quantization to Speculative Decoding
 This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.






.png "The Hbm Tax: Why Vision Encoders And Language Decoders Fight Over Your Gpu")







") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·