TL;DR
- Nearly each awesome open-weight LLM released successful 2025-2026 uses a Mixture of Experts (MoE) architecture — Llama 4, DeepSeek V4, Qwen 3.6, Kimi K2.6, gpt-oss, Cohere Command A+, and more.
- MoE separates progressive parameters (used per token) from full parameters (loaded successful memory). A “400B model” whitethorn only tally 17B per token.
- This shifts the conclusion costs equation: compute per token goes down, but representation footprint stays high.
- MoE wins connected costs erstwhile GPUs enactment saturated. It loses severely astatine debased utilization.
- For astir mid-market teams, a dense exemplary connected right-sized hardware is still the amended economical call. Test earlier you commit: DigitalOcean GPU Droplets fto you benchmark some connected the aforesaid level without agelong contracts.
What is simply a Mixture of Experts (MoE) model?
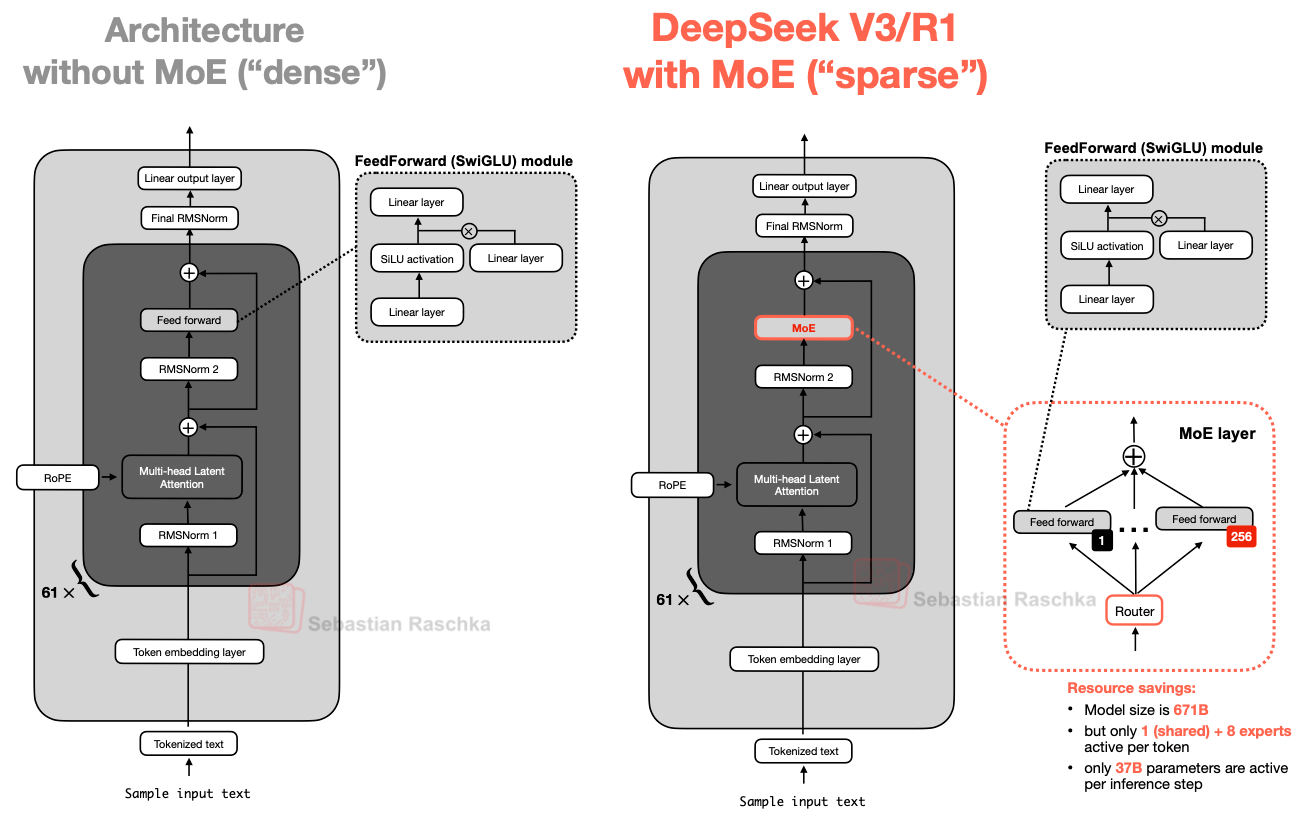
(Source)
A Mixture of Experts (MoE) exemplary is simply a transformer wherever the dense feed-forward layers wrong each artifact are replaced by a group of smaller parallel networks called experts. A mini router (or gating network) looks astatine each token and picks which experts process it — typically 2 to 8 retired of dozens aliases hundreds.
Everything other looks for illustration a normal transformer. The sparsity lives wholly successful those swapped-out feed-forward layers.
Key MoE terminology
- Total parameters — each weight successful the model, including each experts. Determines representation footprint.
- Active parameters — weights really utilized per token. Determines per-token compute (FLOPs) and conclusion latency.
- Experts — the parallel feed-forward sub-networks the router selects between.
- Top-k routing — the norm for selecting k experts per token. Top-2 (Mixtral) and top-8 (newer models) are common.
- Router / gating web — the mini learned constituent that scores experts and routes tokens.
- Shared experts — experts each token passes through, utilized alongside routed experts. Popularized by DeepSeek.
A elemental analogy
A dense transformer is for illustration a azygous knowledgeable wide practitioner who sees each diligent personally. Every sojourn costs the aforesaid magnitude of their time.
A MoE exemplary is simply a infirmary pinch a triage caregiver and a roster of specialists. The caregiver (the router) sends each diligent to the 2 aliases 3 specialists astir applicable to their case. The infirmary knows much than immoderate azygous GP, but you person to salary each master connected unit whether they’re seeing patients aliases not.
That’s MoE conclusion successful 1 sentence: you salary for representation successful full parameters, but you only get compute savings connected progressive parameters.
Why is each awesome laboratory releasing MoE models successful 2025-2026?
What we’re witnessing is champion described arsenic the MoE-ification of the unfastened exemplary ecosystem: a coordinated architectural migration from dense transformers to sparse ones, happening crossed each awesome laboratory successful astir an 18-month window. Three forces are driving it.
Training economics. MoE models deed a fixed value target pinch substantially less training FLOPs than dense equivalents. When frontier training runs costs hundreds of millions of dollars, this matters enormously.
The DeepSeek moment. DeepSeek V3 (late 2024) and R1 (January 2025) proved publically that an MoE could lucifer frontier dense models astatine a fraction of training cost. DeepSeek V4, released arsenic a preview successful April 2026, pushed this further pinch a 1.6T-parameter Pro version that activates conscionable 49B per token. Every awesome laboratory spent 2025 either shipping their ain MoE aliases explaining why their adjacent merchandise would beryllium one.
Hardware caught up. The H100, H200, and B200 generations yet person the representation capacity and interconnect bandwidth to make ample MoE serving practical. You tin tally frontier MoE models cost-effectively coming connected DigitalOcean GPU Droplets pinch NVIDIA H100 and H200 hardware.
Notable open-weight MoE models
| Mixtral 8x7B | 47B / 13B | Dec 2023 | The exemplary that brought MoE mainstream |
| DeepSeek V3 | 671B / 37B | Dec 2024 | First awesome frontier-quality unfastened MoE |
| DeepSeek R1 | 671B / 37B | Jan 2025 | Reasoning-focused; the tipping-point release |
| Llama 4 Scout | 109B / 17B | Apr 2025 | Meta’s first MoE; fits connected a azygous H100 |
| Llama 4 Maverick | 400B / 17B | Apr 2025 | 128 experts; precocious value astatine debased progressive count |
| Kimi K2 | 1T / 32B | Jul 2025 | Modified MIT license |
| gpt-oss-120b / 20b | sparse | Aug 2025 | OpenAI’s open-weight return |
| Qwen 3.5 | 397B / 17B | Feb 2026 | Multimodal, 262K discourse window |
| DeepSeek V4 Pro | 1.6T / 49B | Apr 2026 | Current frontier unfastened MoE, 1M context |
| Cohere Command A+ | 218B / 25B | May 2026 | 128 experts, Apache 2.0, runs connected 2× H100 |
The active-to-total ratio keeps dropping: ~25% successful Mixtral, ~4% successful Llama 4 Maverick and Qwen 3.5, ~3% successful DeepSeek V4 Pro. Sparser models train much efficiently but require much representation per useful FLOP delivered.
How does MoE impact your conclusion bill?
MoE changes conclusion economics connected 3 axes: compute, memory, and utilization. Each pulls the measure successful a different direction.
Compute: bully news
Per-token FLOPs standard pinch progressive parameters, not total. A 400B MoE that activates 17B per token does astir the aforesaid mathematics arsenic a 17B dense exemplary — and importantly little than a dense 70B. If you’ve been comparing models by full parameter count, the intuition you built up astir costs is now misleading you.
This is why conclusion providers tin value MoE models truthful aggressively. Lower FLOPs per token intends much tokens per GPU-second, which intends little costs per cardinal tokens astatine the aforesaid hourly rate. Latency benefits follow: prefill is faster because it’s FLOP-bound, and procreation throughput typically thumps dense models of balanced quality.
Memory: bad news
Every master has to unrecorded successful VRAM, whether the router calls connected it aliases not. The router tin only take betwixt experts that are loaded and fresh — you can’t materialize them connected request without crushing latency.
That 400B MoE needs ~400B parameters of memory. The activation sparsity that saves compute does thing for memory. You’re not fitting it connected a azygous H100 successful FP16 — you request multi-GPU deployments pinch master parallelism, fierce quantization (FP8, INT8, INT4), aliases both. Each costs you something: hardware spend, engineering time, aliases quality.
The AMD MI300X GPUs disposable connected DigitalOcean — pinch 192 GB of HBM3 representation per paper — are structurally well-suited to MoE workloads precisely because they push the memory-per-dollar curve successful the correct direction.
KV cache: the 2nd representation tax
There’s a 2nd representation taxation astir articles miss: the KV cache. Every token successful a conversation’s discourse model stores its cardinal and worth activations successful GPU memory, and that cache grows linearly pinch some discourse magnitude and batch size. At short contexts the cache is rounding correction against exemplary weights. At agelong contexts — and respective frontier MoEs now vessel pinch 256K, 1M, aliases longer discourse windows — KV cache tin lucifer aliases transcend the weight footprint.
This hits MoE deployments harder than dense ones for 2 reasons. First, you’ve already spent your VRAM fund loading experts you’re not actively using, truthful there’s little headroom for cache. Second, erstwhile experts are divided crossed GPUs via master parallelism, the KV cache still has to travel each request, which adds cross-GPU representation unit and bandwidth costs that don’t look successful single-GPU sizing calculations.
The applicable implication: erstwhile sizing hardware for a long-context MoE workload, fund representation for weights positive a realistic KV cache estimate based connected your existent batch size and discourse length, not conscionable the weight footprint alone. This is 1 of the astir communal reasons existent deployments under-provision and deed out-of-memory errors weeks aft going live.
Utilization: the hinge
MoE shines nether high-throughput batched inference, wherever galore tokens get astatine erstwhile and the router spreads load crossed experts evenly. Every master successful VRAM earns its keep, the GPU saturates, and per-token economics lucifer the FLOP math.
It struggles nether single-stream, low-batch, latency-sensitive serving. A fistful of in-flight tokens activates a mini subset of experts while the remainder beryllium idle. You tin besides deed master imbalance, wherever 1 aliases 2 “popular” experts get overloaded while others spell untouched — producing inconsistent latency, underutilized GPUs, and astonishing bills.
The applicable takeaway: MoE is purpose-built for high-traffic API endpoints and simply tolerable for low-volume deployments. Same model, other economical outcomes.
MoE is not cheaper because it is sparse. MoE is cheaper erstwhile your postulation is dense capable to amortize sparse activation crossed costly resident memory.
A worked example: MoE vs. dense connected DigitalOcean
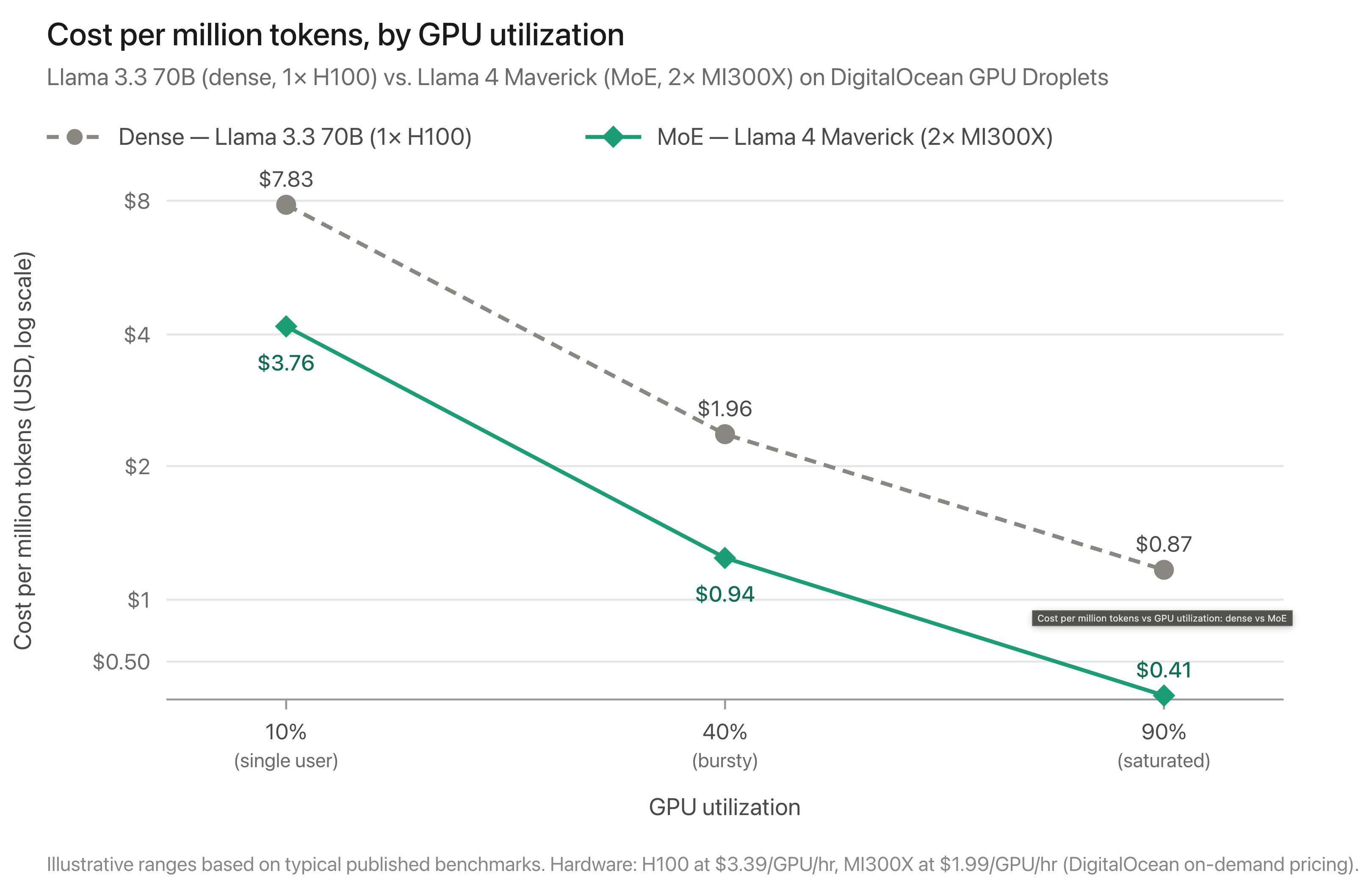
Suppose you’re choosing betwixt Llama 4 Maverick (17B progressive / 400B total) and Llama 3.3 70B (dense) for production conclusion connected DigitalOcean Compute. The published on-demand pricing varies - H100 astatine $3.39/GPU/hour, H200 astatine $3.44/GPU/hour, MI300X astatine $1.99/GPU/hour.
Memory footprint astatine FP8:
- Llama 3.3 70B → ~70 GB; fits connected 1 H100 aliases H200.
- Llama 4 Maverick → ~400 GB; needs 4× H100, 3× H200, aliases 2× MI300X minimum.
Hardware cost:
| Llama 3.3 70B | 1× H100 | $3.39 |
| Llama 3.3 70B | 1× H200 | $3.44 |
| Llama 4 Maverick | 2× MI300X | $3.98 |
| Llama 4 Maverick | 3× H200 | $10.32 |
| Llama 4 Maverick | 4× H100 | $13.56 |
The MI300X configuration is the closest to parity — its higher VRAM-per-card is structurally well-matched to MoE workloads.
Per-token economics crossed utilization levels (illustrative ranges based connected emblematic benchmarks — verify pinch your ain workload):
| 90% (saturated) | ~$0.87 / M tokens | ~$0.41 / M tokens |
| 40% (bursty) | ~$1.96 / M tokens | ~$0.94 / M tokens |
| 10% (single user) | ~$7.83 / M tokens | ~$3.76 / M tokens |
At saturation, MoE wins decisively — astir half the per-token cost. At debased utilization, some options look bad, but the dense option’s little absolute hourly pain intends little wasted money per idle hour. MoE saves money if your utilization is precocious capable to amortize the bigger hardware footprint. Otherwise, you’re paying for representation you’re not using.
Who really wins pinch MoE — and what to deploy where
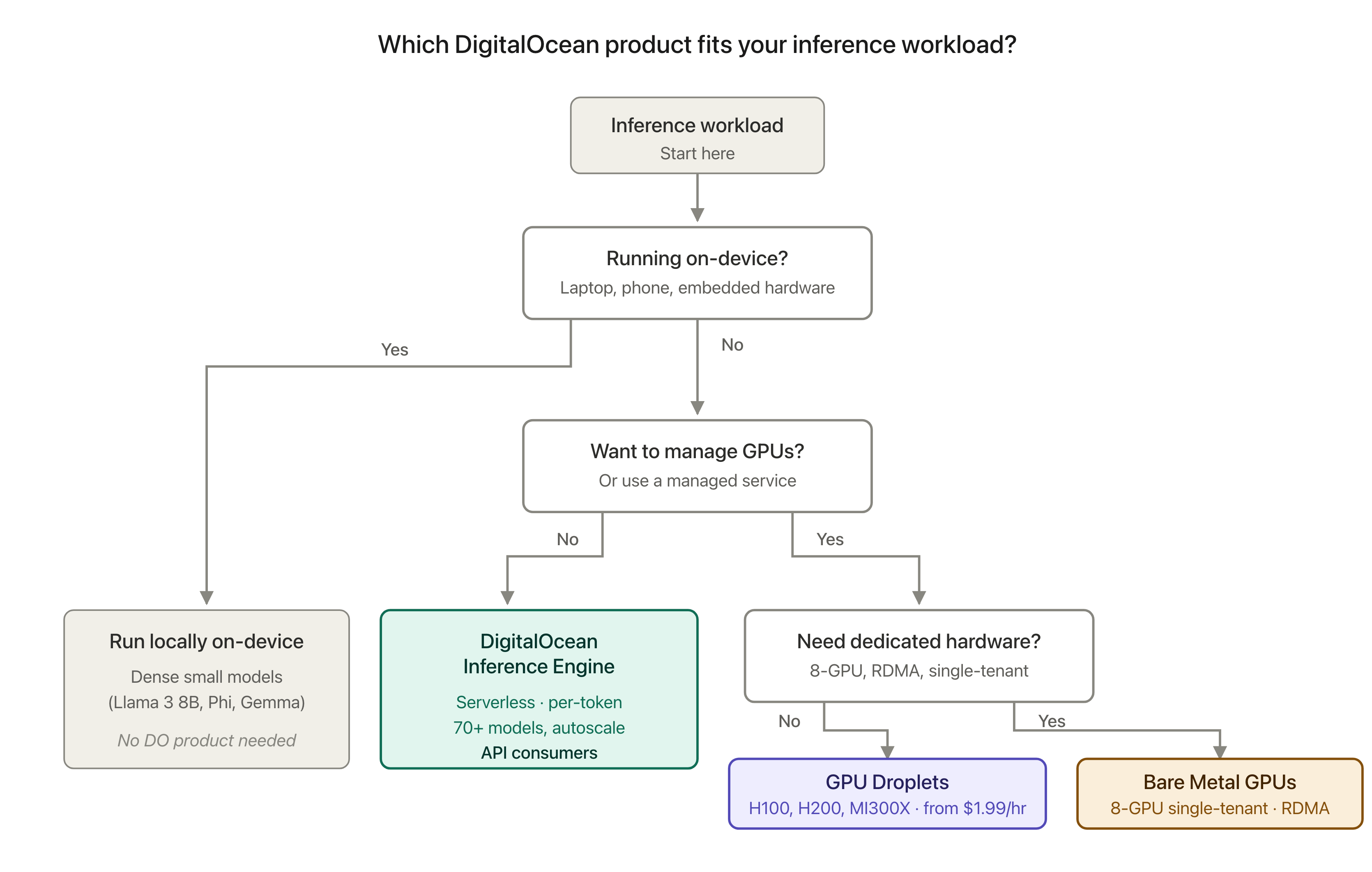
The correct strategy depends connected which spot you’re in.
API consumers are the cleanest winners. You get MoE’s improved portion economics without handling representation aliases routing complexity. The DigitalOcean Inference Engine offers serverless conclusion crossed 70+ unfastened and frontier models — including gpt-oss-120b, gpt-oss-20b, and different sparse models — pinch autoscaling from zero and per-token pricing. If you’re calling a exemplary from accumulation code, this is almost ever the correct starting point. You don’t request to deliberation astir master imbalance; the level handles it.
Cloud self-hosters look the astir absorbing math, and the worked illustration supra is for you. You request to size hardware for full parameters but salary for tokens proportional to progressive parameters. DigitalOcean GPU Droplets fto you trial empirically without agelong contracts: rotation up an MI300X for $1.99/hr if you fishy representation is your binding constraint, an H100 for $3.39/hr if compute is, tally your existent workload for a day, and look astatine the numbers. The Inference-Optimized Image (PyTorch, CUDA, FlashAttention pre-configured) gets you from motorboat to unrecorded conclusion successful minutes. 1-Click Models grip celebrated open-weight deployments without setup.
On-prem and endeavor workloads tin agelong existing hardware further pinch MoE — if the workload matches. DigitalOcean Bare Metal GPUs are built for this profile: dedicated single-tenant servers pinch 8 GPUs per machine, RDMA interconnect up to 3.2 Tbps, nary neighbour noise, and the web topology MoE master parallelism really needs. A slope moving batched overnight archive classification will emotion MoE connected bare metal. The aforesaid slope moving an interactive expert adjunct for 50 users whitethorn find a dense Llama 3.3 70B connected a azygous H200 GPU Droplet serves them amended astatine little full cost.
Edge and section conclusion is still dense territory. Memory-constrained environments — laptops, phones, azygous user GPUs, embedded devices — get nary use from holding 100 experts successful RAM to usage 2. Dense mini models for illustration Llama 3 8B, Phi, and Gemma stay the correct tool, and the spread isn’t closing.
A fewer things don’t show up connected benchmark sheets but will show up successful your engineering estimates.
Quantization is trickier. Individual experts are smaller than the dense FFNs they replaced, making weights much delicate to precision loss. INT4 quantization that useful good connected Llama 3 70B tin degrade an MoE of balanced full size successful subtle ways — worse behaviour connected circumstantial topics alternatively than azygous value drops. Evaluate quantized MoEs connected your workload, not conscionable MMLU.
Fine-tuning is harder. Open tooling grew up astir dense transformers. LoRA and afloat fine-tuning recipes for MoE beryllium but are little well-trodden, and router behaviour is peculiarly delicate — naive runs tin illness master specialization. If your roadmap depends connected dense customization, facet successful other engineering time.
Serving complexity adds up. Expert placement, all-to-all connection tuning, and load balancing are existent engineering work. vLLM, SGLang, and TensorRT-LLM person matured quickly and grip astir awesome MoE architectures good — but support for caller releases tends to lag by days aliases weeks, and separator cases (specific quantization formats, parallelism strategies, agelong contexts) still aboveground bugs.
The contrarian case: astir teams shouldn’t move yet
Here’s what the remainder of the net won’t show you: the MoE-ification of the unfastened exemplary ecosystem is existent and important — and for astir teams reference this, it shouldn’t alteration your deployment strategy this quarter.
The teams that use from frontier MoEs tally steady, high-throughput, multi-tenant workloads astatine scale: API providers, archive pipelines that ne'er sleep, large-scale embedding generation, soul devices astatine companies pinch thousands of regular progressive users hitting 1 endpoint. If that’s you, the worked illustration shows existent savings — 50%+ astatine the per-token level — and you should measure MoE seriously.
For everyone else, the mathematics is little flattering. The single-engineer startup pinch bursty traffic. The mid-market SaaS embedding LLM features into an existing product. The R&D squad building a proof-of-concept. The agency moving conclusion for mini clients. In each case, a well-served dense exemplary connected a azygous H100 aliases H200 will usually present little full cost, simpler operations, much predictable latency, and an easier fine-tuning way than a frontier MoE connected the multi-GPU rig it needs.
The asymmetric risk: you move to MoE because the benchmarks look awesome and the per-token value is irresistible, past observe six months later that your workload — your batch sizes, your tail latency requirements, your fine-tuning needs — is connected the incorrect broadside of MoE’s saccharine spot, and you’ve taken connected infrastructure complexity that’s difficult to locomotion back. Staying dense excessively agelong is overmuch cheaper to correct.
| Low traffic, bursty app | Serverless inference |
| Medium traffic, predictable latency | Dense exemplary connected H100/H200 |
| High-throughput batched workload | MoE connected multi-GPU / MI300X / bare metal |
| Heavy fine-tuning roadmap | Dense first |
| Long-context archive workloads | Model weights + KV cache sizing trial required |
Our recommendation: commencement pinch a dense exemplary connected right-sized infrastructure, measurement your existent utilization and postulation patterns for astatine slightest a month, and only past revisit whether MoE makes economical consciousness for your circumstantial workload. On DigitalOcean, that’s a azygous H100 aliases H200 GPU Droplet moving Llama 3.3 70B (or a smaller dense model), pinch the DigitalOcean Inference Engine arsenic a fallback for adaptable traffic. When your utilization information tells you to switch, the aforesaid level supports the upgrade.
What to watch next
The active-to-total ratio race. Mixtral was ~25%; Llama 4 Maverick is ~4%; DeepSeek V4 Pro is ~3%. How acold this tin beryllium pushed earlier value breaks is an unfastened empirical mobility — and the reply shapes what “frontier” looks for illustration successful 2027.
MoE-aware quantization. Generic dense techniques time off value connected the table. Expert-specific quantization and move precision allocation could straight little the representation costs that makes MoE achy for smaller deployers.
Routing innovations. Shared experts, fine-grained experts, and learned routing each alteration the costs structure. Router value determines really good a exemplary uses experts you’re already paying representation for.
Closed labs. ChatGPT has agelong been rumored sparse. Anthropic and Google don’t people architectural details. If the closed frontier is besides MoE, the architectural spread betwixt unfastened and closed shrinks, and deployment ratio becomes the main competitory axis.
Frequently asked questions
What does MoE guidelines for successful AI?
MoE stands for Mixture of Experts: an architecture wherever a router sends each token to a mini subset of specialized “expert” networks alternatively of moving each parameter for each token.
How is an MoE exemplary different from a dense model?
A dense exemplary uses each of its parameters for each token. An MoE exemplary keeps galore much full parameters successful memory, but activates only a fraction of them per token.
Are MoE models cheaper to tally than dense models?
MoE models are cheaper erstwhile postulation is precocious capable to support GPUs good utilized. At debased utilization, they tin costs much because you still salary to support each master weights loaded successful memory.
Which numbers matter astir for MoE conclusion cost?
The 2 cardinal numbers are full parameters and progressive parameters. Total parameters find representation footprint; progressive parameters find per-token compute.
How overmuch VRAM do MoE models need?
MoE models request capable VRAM for the afloat exemplary weights, not conscionable the progressive parameters. Long discourse windows besides require other representation for KV cache, which tin materially alteration hardware sizing.
When should I usage an MoE model?
Use MoE for high-throughput, batched workloads wherever the hardware stays busy. For bursty, low-volume, latency-sensitive, aliases heavy fine-tuned workloads, a dense exemplary is often simpler and cheaper.
Should astir teams move from dense models to MoE?
Not automatically. Start pinch a right-sized dense model, measurement existent utilization, and only move to MoE if your postulation shape tin amortize the larger representation footprint.
When should I usage serverless conclusion alternatively of self-hosting?
Use serverless conclusion erstwhile postulation is adaptable aliases unpredictable. Self-hosting makes much consciousness erstwhile workload measurement is dependable capable to warrant always-on GPU capacity.
What should stakeholders retrieve astir MoE and conclusion bills?
MoE does not make conclusion automatically cheaper. It lowers compute per token, but the last measure depends connected representation footprint, utilization, batching, discourse length, and serving complexity.
Conclusion
The MoE-ification of the unfastened exemplary ecosystem isn’t a niche architectural footnote — it’s the astir consequential alteration to really open-weight models are built, served, and priced since the original Llama release. Nearly each awesome laboratory now ships MoE by default.
The costs image isn’t uniformly amended aliases worse than the dense era. It’s different. Per-token compute went down; representation footprint went up; batching matters much than ever; quantization and fine-tuning sewage harder; serving infrastructure sewage much complex. Whether your measure ends up smaller aliases larger depends wholly connected whether your workload looks for illustration the 1 MoE is optimized for.
The deeper change: comparing models by parameter count is efficaciously over. “70B” utilized to beryllium a meaningful shorthand for cost, latency, and capability. In an MoE world, it’s almost meaningless. The numbers you request to logic astir — progressive parameters, full parameters, representation footprint, throughput nether load, postulation shape — are much analyzable than a azygous header figure.
That’s a taxation connected everyone’s intelligence model, but it’s besides the caller baseline. Teams that internalize it first will extremity up pinch cheaper, faster, better-deployed inference. Teams that don’t will walk the adjacent twelvemonth wondering why their GPU measure keeps astonishing them.
Get started connected DigitalOcean. Start by benchmarking 3 numbers connected your ain workload: GPU utilization, tokens/sec astatine target latency, and KV cache representation astatine realistic discourse length. DigitalOcean lets you tally that trial crossed Serverless Inference, Dedicated Inference and GPU Droplets, without committing to a azygous serving strategy upfront.
 This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.








.png "The Llm Inference Optimization: Quantization To Speculative Decoding Part 2")
.png "Opencode: An Open-source Claude Code Alternative")



![Stanford's Youngest Instructor On Infosec, Ai, Catching Cheaters - Rachel Fernandez [podcast #217]](https://i1.ytimg.com/vi/GmtOxMl39Tc/maxresdefault.jpg "Stanford's Youngest Instructor On Infosec, Ai, Catching Cheaters - Rachel Fernandez [podcast #217]")


") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·