Introduction: The Uniform Model Tax
Here is simply a petition that conscionable deed your accumulation API:
"Are location immoderate syntax issues here? prices_usd = {'laptop': 1200, 'mouse': 25, 'monitor': 300} expensive_items_eur = {k: v * exchange_rate for k, v successful prices_usd.items() if v > 50} print(expensive_items_eur)"A syntax check.
The reply is no, location are nary issues.
Any exemplary from a $0.10/million-token tier tin reply this correctly successful nether a second.
Now present is the adjacent petition from the aforesaid supplier session, 3 seconds later:
"We're migrating our monolith to microservices. The existent architecture uses a shared PostgreSQL lawsuit pinch 47 tables. Identify which tables are safe to split into abstracted work databases without introducing distributed transaction risk, and propose a phased decomposition strategy."This is simply a different query entirely. It requires architectural reasoning, knowing of distributed systems tradeoffs, and the expertise to synthesize a multi-step migration plan. This is simply a analyzable task for a frontier model.
Most accumulation systems coming dainty these 2 requests arsenic the same. They way some to the aforesaid model; typically, the astir tin one, because building thing smarter requires infrastructure that astir teams don’t person clip to build. In this case, you salary frontier rates for each request, including the overwhelming mostly that don’t request frontier capability.
The numbers compound quickly. In a emblematic coding supplier session, the distribution of task complexity looks astir for illustration this: In a emblematic coding supplier session, the mostly of requests are simpler tasks — syntax checks, short lookups, basal explanations — while a smaller stock requires the benignant of multi-step reasoning only frontier models grip well. If you’re routing everything to a exemplary priced astatine $15/million output tokens, you’re paying that complaint for activity that a $0.30/million-token exemplary handles conscionable arsenic well.
Key Takeaways
- Sending each petition to 1 exemplary is expensive. Most requests successful a accumulation workload are elemental — syntax checks, short lookups, basal explanations. Paying frontier exemplary rates for each of them adds up fast.
- The Inference Router picks the correct exemplary per petition automatically. It sounds each request, matches it to a task type you’ve defined, and sends it to the astir cost-effective exemplary disposable for that task.
- Routing accuracy is 87.84% connected the 30B-A3B model — higher than GPT-5.1 (86.93%) and Claude Sonnet 4.5 (86.11%) connected the aforesaid benchmark.
- For agentic loops, usage convention pinning. The X-Model-Affinity header locks a convention to 1 model, which preserves the cached discourse and reduces input token costs by 45–80% per turn.
- Getting started is simply a one-line change. Replace "model": "gpt-5.2" pinch "model": "router:software-engineering" successful your existing API call. Everything other stays the same.
Why Teams Don’t Route Today
Option 1: Hardcoded routing logic successful exertion code. You constitute conditional branches, specified arsenic if the punctual contains “explain” aliases “summarize,” usage the inexpensive model; otherwise, usage the costly one. This breaks immediately. “Explain why this title information occurs and hole it” gets routed to the inexpensive model. “Write hullo world” pinch a sarcastic reside accidentally triggers the costly path. Keyword-based methods cannot understand discourse aliases meaning. Every exemplary aliases task alteration requires a codification deployment. You’ve turned exemplary action into a characteristic you ain and support indefinitely.
Option 2: A classifier LLM arsenic a routing layer. Use a mini exemplary for illustration Claude Haiku aliases GPT-4o-mini to categorize intent, past dispatch to the correct model. This is conceptually sound but introduces a caller problem: you’re paying for 2 conclusion calls per personification request; 1 to classify, 1 to respond. Worse, a general-purpose exemplary prompted to categorize isn’t optimized for that task. Accuracy suffers successful separator cases. And you’ve doubled your latency connected the captious way earlier the personification sees a azygous output token.
Neither action scales. Both put routing logic wherever it doesn’t belong: successful exertion codification aliases successful a general-purpose exemplary that wasn’t built for the job.
What Routing Actually Requires
To way requests correctly astatine scale, you request 3 things:
1. Semantic intent resolution. Not keyword matching and existent knowing of what a speech is asking for, accounting for multi-turn context. A connection that says “do the aforesaid for New York” intends thing without the preceding turns. A connection that says “fix it” successful a coding convention intends “fix the bug we were conscionable discussing,” not “fix the syntax.” Any routing strategy that can’t logic complete speech discourse will neglect connected existent agentic traffic.
2. Live capacity signals. Model costs and latency are not constants. Provider pricing changes. Latency fluctuates by 2–3× passim the time based connected postulation load — the fastest exemplary astatine 2 americium is often the slowest astatine 2 pm. A routing strategy built connected fixed configuration bakes successful assumptions that will beryllium incorrect wrong weeks.
3. Infrastructure-level execution. Routing that lives successful exertion codification is routing that the exertion squad has to maintain. When models are added, deprecated, aliases repriced, the routing logic needs updating. When an agent framework changes, the routing wrapper breaks. Routing belongs astatine the infrastructure furniture — beneath the application, invisible to it, and updatable without rubbing exertion code.
This is wherever inference-time exemplary routing arsenic an infrastructure primitive becomes important.
The Research Foundation
Using different LLMs to equilibrium costs and value is supported by beardown research.
FrugalGPT (Chen et al., 2023) was among the first papers to bring retired this caller approach: By sending requests to models from slightest to astir powerful and stopping erstwhile a exemplary is assured enough, you tin execute GPT-4-level value astatine up to 98% little costs connected modular benchmarks. The halfway penetration was that astir queries don’t request the astir costly model; the difficult portion is knowing which ones do.
RouteLLM (Ong et al., 2024) extended this by learning routing policies from quality penchant information alternatively than constructing them by hand. Their champion router achieved a 2× costs simplification while preserving 95% of GPT-4 value connected the Chatbot Arena benchmark. The cardinal finding: a mini classifier trained specifically for routing substantially outperforms prompting a general-purpose exemplary to make routing decisions. Purpose-built thumps general-purpose for narrow, well-defined tasks.
More recently, LLMRouterBench (2026) introduced a unified information model crossed routing methods, confirming that learned, task-specific routers consistently predominate rule-based and prompted approaches crossed quality, cost, and latency dimensions.
The world lawsuit for intelligent routing is clear. The missing portion was accumulation infrastructure that makes it a one-line alteration alternatively than a multi-week engineering project.
The DigitalOcean Approach
DigitalOcean’s Inference Router is built connected a different premise than the options above. Rather than a general-purpose classifier aliases a group of application-layer rules, it uses a purpose-built Mixture-of-Experts (MoE) exemplary fine-tuned specifically for routing crossed multi-turn conversations. It uses a purpose-built routing exemplary called Plano-Orchestrator, developed by Katanemo (now portion of DigitalOcean) and disposable successful a 4B dense version and a 30B-A3B MoE version that activates only ~3B parameters per routing decision. It runs wrong Plano, the open-source AI-native proxy that powers the Inference Router’s infrastructure layer.
Using it looks for illustration this:
from openai import OpenAI import os client = OpenAI( base_url="https://inference.do-ai.run/v1", api_key=os.environ["MODEL_ACCESS_KEY"] ) # Before: each petition hits gpt-5.2 sloppy of complexity response = client.chat.completions.create( model="openai-gpt-5.2", messages=[{"role": "user", "content": prompt}] ) # After: the MoE router dispatches each petition to the correct model response = client.chat.completions.create( model="router:software-engineering", messages=[{"role": "user", "content": prompt}] ) # Which exemplary really handled this request? print(response.model) # e.g., "openai-gpt-oss-120b" aliases "anthropic-claude-sonnet-4.5"The exemplary section successful the consequence tells you precisely which exemplary handled the request. The routing determination is afloat observable. The exertion codification is identical isolated from for 1 string.
Why is MoE known arsenic the Routing Brain?
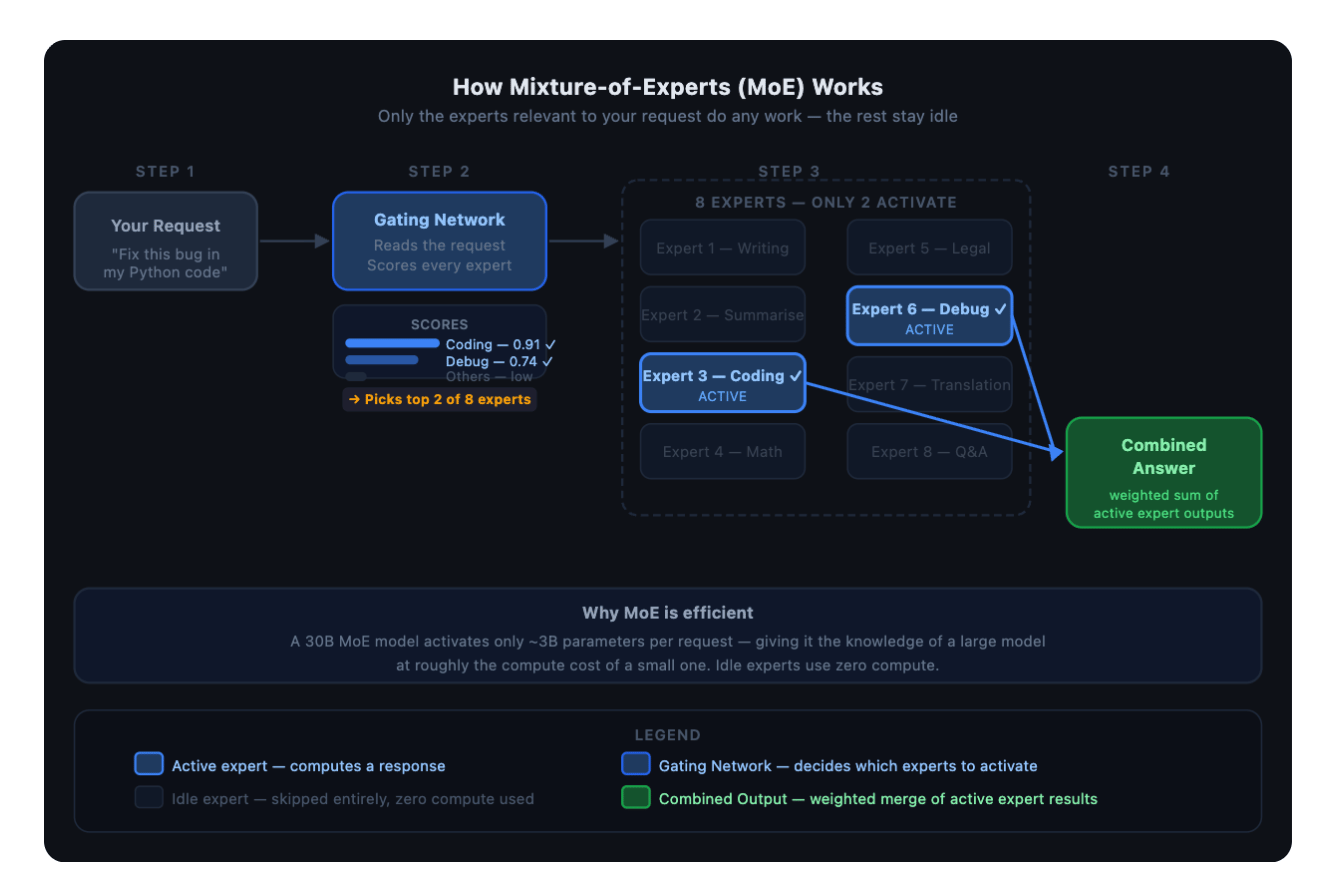
Two concepts travel together successful this article: routing and Mixture-of-Experts (MoE). It’s worthy defining some intelligibly earlier getting into really some of this combines.
Routing intends automatically deciding which exemplary handles a fixed request, alternatively of sending everything to 1 hardcoded model. A router sits successful beforehand of your exemplary pool, sounds each incoming prompt, figures retired what benignant of task it is, and dispatches it to the exemplary champion suited for that task. A elemental syntax cheque goes to a cheap, accelerated model. A analyzable architecture mobility goes to a frontier model. The exertion codification doesn’t change, and only the drawstring successful the exemplary field.
Mixture-of-Experts (MoE) is simply a exemplary architecture where, alternatively of moving each parameters for each input, the exemplary has a group of specialized sub-networks (experts) and a mini gating web that activates only the astir applicable ones. A 30B MoE exemplary mightiness activate only 3B parameters per petition frankincense giving it the capacity of a ample exemplary but the compute costs of a overmuch smaller one.
This conception is intentionally short connected wide MoE mentation (DigitalOcean’s existing articles connected Expert Parallelism and MoE conclusion costs screen that well). The attraction present is connected the circumstantial spot that makes MoE useful arsenic a classifier wrong a routing layer.
Dense vs. Sparse: The Core Difference
A modular Transformer is what astir group mean erstwhile they opportunity “LLM” and is simply a dense model. Every guardant walk activates each parameter. If the exemplary has 70B parameters, each token you make touches each 70B.
A Mixture-of-Experts exemplary replaces the dense feed-forward network (FFN) layers pinch a group of N master networks and a mini gating network. For each token, the gating web selects only the apical k experts (typically k=2) and routes the token done those. The different N - k experts do thing for that token.
The Plano-Orchestrator-30B-A3B exemplary that powers DigitalOcean’s Inference Router has 30B full parameters but only activates astir 3B per guardant pass. That’s what the “A3B” intends successful the exemplary name: 30B total, 3B active.
Dense exemplary (70B): [token] → each 70B parameters activated → output MoE exemplary (30B-A3B): [token] → gating web → top-2 experts (~3B) → output ↑ 28B parameters beryllium idle for this tokenThis separation of total parameters from active parameters is the cardinal property. A MoE exemplary tin person the capacity of a ample exemplary (because its full parameter count is high) while moving astatine the compute costs of a overmuch smaller 1 (because only a fraction activates per pass).
How the Gating Network Selects Experts
The gating web is simply a learned linear furniture that produces a people for each expert, past selects the top-k. In mathematical terms:
For a token practice x and N experts, the gating output is:
scores = x · W_gate # task token into expert-score space top_k_indices = TopK(scores, k) # prime the k highest-scoring experts weights = Softmax(scores[top_k_indices]) # normalize to get publication weights output = Σ weights[i] · Expert_i(x) # weighted sum of selected master outputsThe exemplary learns during training which kinds of inputs each master should handle. Experts don’t get manually assigned topics, and they specialize done gradient descent connected immoderate patterns the training information rewards.
One applicable problem this creates is load imbalance: if the gating web routes astir tokens to the aforesaid 2 experts, the different experts ne'er get trained, and the exemplary degrades. MoE training adds an auxiliary nonaccomplishment word that penalizes imbalanced routing, pushing tokens to administer much evenly crossed experts.
Why MoE Properties Make It Good for Routing
The routing problem, classifying a conversation’s intent and mapping it to the correct model, has a circumstantial structure:
- High capacity needed: The router must generalize crossed hundreds of different task types, personification phrasings, and speech patterns. A 1B dense exemplary whitethorn not person capable representational capacity to grip this well.
- Low compute budget: The routing determination must hap successful the petition path. Every millisecond it takes is milliseconds added to the user’s hold clip earlier the first token.
MoE straight addresses both. The 30B-A3B exemplary has the capacity of a 30B exemplary capable to grip divers routing scenarios good but runs astatine astir the compute costs of a 3B dense model. That’s why it resolves intent successful ~200ms astatine conclusion time.
A 3B dense exemplary would beryllium accelerated but mightiness not generalize good capable crossed analyzable multi-turn conversations. A 30B dense exemplary would generalize well, but would beryllium excessively slow successful the petition path. The MoE architecture finds the mediate ground.
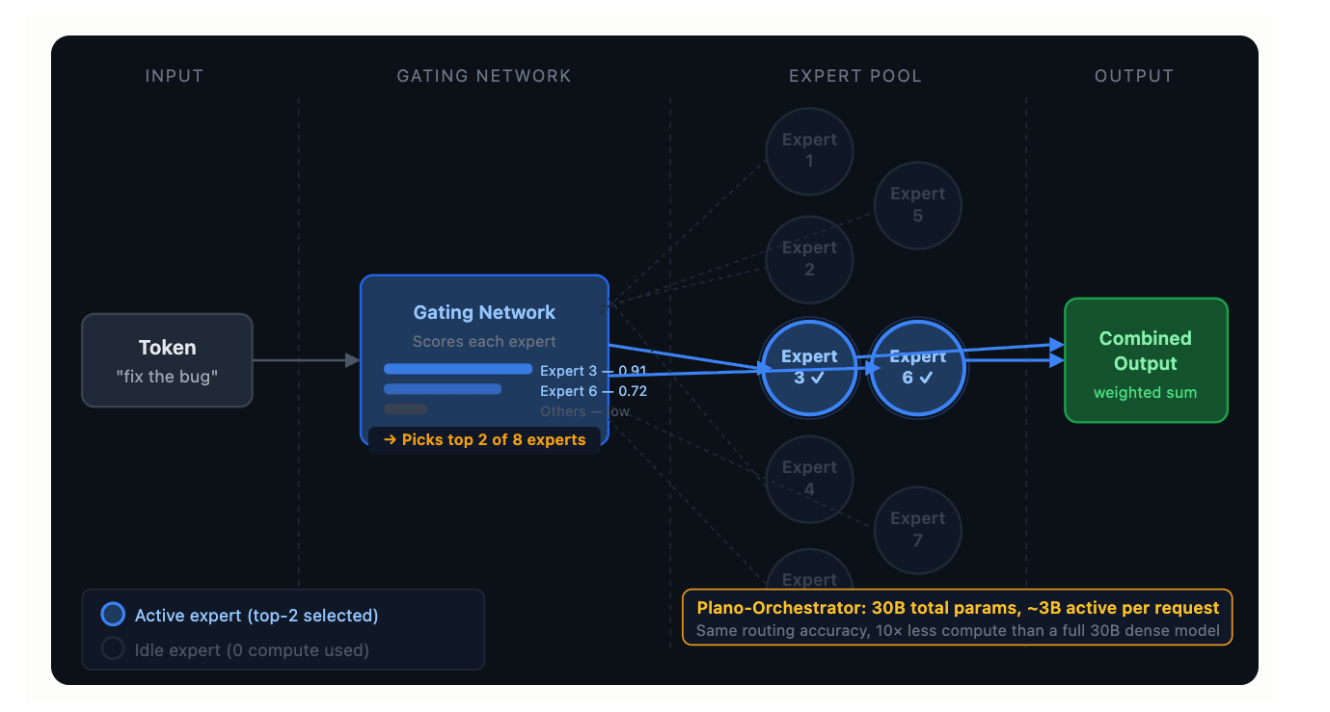
The Bridge: Token Routing → Request Routing
Inside a MoE model, a gating web routes tokens to expert sub-networks. In DigitalOcean’s Inference Router, a MoE exemplary acts arsenic the gating web that routes entire requests to separate exemplary endpoints.
Inside a MoE model: token → gating web → expert_2, expert_7 (of 64) → mixed output In DigitalOcean's Inference Router: petition → Plano-Orchestrator (a MoE model) → model_endpoint_A (of N) → responseThe problem building is the same, that is, categorize an input, nonstop to the champion handler, aggregates aliases passes done the result, conscionable operating astatine a different granularity. The MoE architecture was chosen for the router, not because it’s fashionable, but because its circumstantial properties (high capacity, debased progressive compute) lucifer what routing requires.
How DigitalOcean’s Inference Router Works
Every petition sent to the router:software-engineering aliases immoderate custom router goes done 2 phases earlier it reaches a model. This conception walks done each 1 successful detail.
Phase 1: Intent Resolution
When a petition arrives, Plano (the open-source proxy powering the router) passes the speech on pinch the natural-language descriptions of each configured tasks into the Plano-Orchestrator model. The model’s occupation is to emit a JSON routing decision:
{"route": "code_generation"}or, if thing matches:
json
{"route": "other"}That’s it. The exemplary doesn’t make prose. It doesn’t explicate its reasoning. It sounds the conversation, matches it against the task descriptions, and outputs 1 of N+1 imaginable labels. This constrictive scope is what makes a small, purpose-built exemplary competitory pinch ample general-purpose models connected routing, and the task is structurally elemental moreover if the input (multi-turn conversation) is complex.
How task descriptions participate the model:
The task sanction and explanation you configure are passed into the punctual straight arsenic earthy language. When you write:
{ "name": "bug-fixing", "description": "Identify and hole errors aliases bugs successful user-supplied code" }The exemplary sees thing like: “Does the pursuing speech lucifer the task ‘bug-fixing: Identify and hole errors aliases bugs successful user-supplied code’?” This intends the value of your routing depends connected really you constitute those descriptions.
Handling agelong conversations:
Production conversations tin easy tally to thousands of tokens. The routing exemplary has a token budget, and moving a afloat tokenizer connected each petition successful the basking way adds unacceptable overhead. Plano handles this successful 2 steps:
- Keep the astir caller turns to fresh the token budget.
- If the past personification connection itself still overflows the budget, use a middle-trim strategy connected that message: sphere astir 60% from the commencement and 40% from the end, separated by an ellipsis.
This outperforms head-only truncation because coding and supplier conversations often person a setup shape astatine the commencement (“I’m building a FastAPI work that…”) and the actual existent inquire astatine the extremity (“…now hole the KeyError connected statement 47”). Preserving some edges gives the routing exemplary a stronger awesome than dropping the end.
Phase 2: Model Ranking
Once the intent is resolved and a task is matched, the router has a excavation of campaigner models for that task. It past needs to prime one.
The ranking motor sounds unrecorded information from 2 sources:
- DigitalOcean’s pricing API for existent per-token costs
- Prometheus for unrecorded latency measurements (time-to-first-token, aliases TTFT)
Based connected the task’s configured selection_policy, it sorts the campaigner models:
| prefer: cheapest | Ascending input + output token cost |
| prefer: fastest | Ascending TTFT from unrecorded Prometheus data |
| Manual ranking | Your configured order, nary re-sorting |
The classed database is utilized successful order: the apical exemplary gets the request. If it’s unavailable aliases rate-limited, the adjacent exemplary successful the database is tried. If each task models fail, the petition falls to the fallback models you configured.
Why unrecorded information matters:
Provider latency is not stable. Based connected observations, the aforesaid exemplary tin alteration by 2–3× successful TTFT (Time to First Token — really agelong the exemplary takes to return the very first connection of its response) depending connected clip of day. A exemplary that’s fastest astatine 2 americium is often the slowest astatine 2 p.m. arsenic supplier postulation increases. Static ranking bakes successful the low-traffic presumption and applies it each day. Live ranking catches these shifts connected each request.
The metrics cache uses a read-optimized information building — each routing decisions are publication from it, but writes only hap connected the configured refresh interval. There’s nary fastener contention connected the basking path.
The Routing Model History: Arch-Router → Plano-Orchestrator
DigitalOcean’s routing exemplary didn’t commencement astatine 30B. Understanding the progression explains why the existent architecture is shaped the measurement it is.
V1: Arch-Router (1.5B)
Arch-Router is simply a 1.5B generative exemplary fine-tuned specifically for single-route classification. It was trained connected task-specific routing data, not wide instruction-following data, and its only occupation is to return a JSON way explanation fixed a speech and a group of task descriptions.
The results, published successful Arch-Router: Aligning LLM Routing pinch Human Preferences, were the first validation that purpose-built thumps general-purpose for routing:
| Arch-Router (1.5B) | 51ms ± 12ms | 93.17% |
| Claude 3.7 Sonnet | 1,450ms ± 385ms | 92.79% |
| GPT-4o | 836ms ± 239ms | 89.74% |
| Gemini 2.0 Flash | 581ms ± 101ms | 85.63% |
| GPT-4o-mini | 737ms ± 164ms | 82.79% |
Arch-Router achieved higher accuracy than each frontier exemplary tested astatine 51ms, 28× faster than Claude 3.7 Sonnet and 16× faster than GPT-4o. This validated the halfway creation premise: a exemplary trained specifically for routing outperforms a overmuch larger exemplary prompted to do routing.
The limitation of Arch-Router was generalization. It performed good connected clean, single-turn queries but struggled pinch the messiness of existent agentic traffic; ambiguous follow-ups, taxable shifts mid-conversation, messages that don’t request routing astatine all.
V2: Plano-Orchestrator (4B dense / 30B-A3B MoE)
Plano-Orchestrator is the exemplary that runs successful DigitalOcean’s Inference Router today. It uses the aforesaid generative attack arsenic Arch-Router — task descriptions successful the prompt, JSON output — but is trained connected richer multi-turn conversational information covering 3 scenarios Arch-Router wasn’t built for:
- Context-dependent routing: Messages for illustration “do the aforesaid for London” that only make consciousness fixed anterior turns
- Multi-turn travel handling: Follow-ups, clarifications, corrections, and off-topic messages
- Negative lawsuit detection: Recognizing erstwhile nary specialized routing is needed (so requests autumn done to fallback models cleanly)
It’s disposable successful 2 sizes:
| Plano-Orchestrator-4B | Dense | 4B | 84.68% |
| Plano-Orchestrator-30B-A3B | MoE | ~3B progressive / 30B total | 87.84% |
Evaluated crossed 1,958 personification messages successful 605 multi-turn conversations spanning 130+ different agents:
| Plano-Orchestrator-30B-A3B | 88.87% | 83.51% | 86.81% | 87.84% |
| GPT-5.1 | 89.71% | 77.54% | 81.28% | 86.93% |
| Claude Sonnet 4.5 | 88.53% | 74.39% | 85.53% | 86.11% |
| Plano-Orchestrator-4B | 87.41% | 71.23% | 84.26% | 84.68% |
| Gemini 2.5 Flash | 84.42% | 66.32% | 82.13% | 81.51% |
| Claude Haiku 4.5 | 81.99% | 72.63% | 85.53% | 81.05% |
The coding class shows the largest gap. The 30B-A3B exemplary scores 83.51% versus GPT-5.1’s 77.54%, a 6-point difference. Coding conversations nutrient short, context-dependent messages (“fix it,” “try again,” “what astir the separator case?”) that are almost meaningless without the speech history. A exemplary trained specifically connected routing patterns successful multi-turn conversations handles these amended than a general-purpose exemplary that’s been prompted to classify.
FP8 quantized variants of some models are available, reducing the representation footprint without meaningful accuracy loss.
Infrastructure: How Routing Stays Fast
The 200ms routing overhead comes from Plano’s three-layer design: Envoy handles the web furniture (TLS, HTTP/2, relationship pooling), a WASM filter moving wrong Envoy handles supplier format translator betwixt OpenAI, Anthropic, Gemini, and others astatine zero web cost, and Brightstaff a Rust binary and runs the existent intent solution and exemplary ranking logic utilizing async tasks alternatively than threads, pinch nary garbage postulation pauses that could stutter token delivery.
For a elaborate walkthrough of why each furniture is built the measurement it is, DigitalOcean’s engineering blog station How We Built DigitalOcean Inference Router covers the implementation successful full, including the WASM sandbox constraints, the hermesllm supplier abstraction crate, and the Brightstaff concurrency model.
Setting Up DigitalOcean Inference Router
For a afloat walkthrough of credentials, preset routers, civilization router creation via API, and Python SDK usage, mention to:
- Inference Routing: Matching Models to Tasks, Not Just Requests — hands-on tutorial covering authentication, preset routers, and civilization router setup pinch moving code.
- How to Use Inference Router — DigitalOcean Docs — charismatic reference for the router configuration options, and the Control Panel workflow.
The short version: group MODEL_ACCESS_KEY, constituent immoderate OpenAI-compatible customer astatine https://inference.do-ai.run/v1, and alteration "model" to "router:your-router-name".
Session Pinning for Agentic Loops
This is the slightest evident feature, and besides 1 of the astir important for agentic workloads.
When an AI supplier runs a multi-turn task, which tin see plan, execute, cheque output, and iterate, successive prompts look different capable that the router whitethorn prime different models crossed turns. This creates 2 compounding problems:
Problem 1: Behavioral inconsistency. Different models person different output formats, tool-calling conventions, and penning styles. Switching models mid-session intends the agent’s parser whitethorn neglect connected a consequence that uses a somewhat different JSON building than the erstwhile turn.
Problem 2: KV cache invalidation. Model providers usage prefix-based KV caching: if the aforesaid token series hits the aforesaid model, the attraction authorities for those tokens is reused from cache. Cached input tokens are billed astatine 50–90% little rates than caller tokens (exact discount depends connected provider). In a 15-turn agentic loop wherever the strategy punctual and earlier turns dress up 90% of the input, model-switching intends 0% cache hits — afloat value each turn.
DigitalOcean’s Inference Router solves this pinch the X-Model-Affinity header. Send a convention identifier pinch the first request; the router makes a normal routing determination and caches which exemplary it selected. All consequent requests pinch the aforesaid affinity ID skip routing and spell straight to the cached model.
import os import httpx MODEL_ACCESS_KEY = os.environ["MODEL_ACCESS_KEY"] SESSION_ID = "agent-session-42" # immoderate unsocial identifier per supplier session headers = { "Authorization": f"Bearer {MODEL_ACCESS_KEY}", "Content-Type": "application/json", "X-Model-Affinity": SESSION_ID # <-- pin this session } # Turn 1: Normal routing decision, consequence cached for SESSION_ID response_1 = httpx.post( "https://inference.do-ai.run/v1/chat/completions", headers=headers, json={ "model": "router:software-engineering", "messages": [ {"role": "user", "content": "Write a FastAPI endpoint that accepts a personification ID and returns their profile"} ] } ) result_1 = response_1.json() print(f"Turn 1 - Model selected: {result_1['model']}") # Turn 2: Routing skipped, aforesaid exemplary reused. KV cache from Turn 1 is valid. response_2 = httpx.post( "https://inference.do-ai.run/v1/chat/completions", headers=headers, json={ "model": "router:software-engineering", "messages": [ {"role": "user", "content": "Write a FastAPI endpoint that accepts a personification ID and returns their profile"}, {"role": "assistant", "content": result_1["choices"][0]["message"]["content"]}, {"role": "user", "content": "Now adhd input validation and return a 404 if the personification doesn't exist"} ] } ) result_2 = response_2.json() print(f"Turn 2 - Model selected: {result_2['model']}") # Same arsenic Turn 1For a 15-turn loop pinch a 4,000-token strategy punctual and 90% cache deed rate, the costs savings connected input tokens unsocial are successful the scope of 45–80% per move compared to nary caching.
Benchmarks — What Routing Actually Saves
This conception uses actual numbers from DigitalOcean’s published benchmarks and a worked costs illustration to show wherever routing saves money, wherever it doesn’t, and what the latency tradeoff looks like.
Routing Accuracy: What 87.84% Means successful Practice
The Plano-Orchestrator-30B-A3B exemplary achieves 87.84% mean routing accuracy crossed 1,958 messages successful 605 multi-turn conversations.
What happens erstwhile routing is wrong? Three outcomes are possible:
- The fallback handles it correctly. If the router routes to “fallback,” the fallback exemplary (typically a tin general-purpose model) answers the petition adequately. No value loss.
- A neighboring task handles it adequately. A code-review petition routed to code-generation still gets a useful consequence — the exemplary isn’t unsighted to the existent content, conscionable the routing label.
- Quality degrades. A analyzable architecture mobility routed to a inexpensive summarization exemplary produces a worse answer.
Outcome 3 is the concern. In practice, DigitalOcean’s preset routers are designed truthful that adjacent tasks stock overlapping exemplary pools, and the value quality betwixt “routed correctly” and “routed to a neighboring task” is small. But this is why testing your router against existent postulation earlier accumulation matters.
The comparison constituent isn’t “87.84% vs 100%.” It’s “87.84% from a 200ms exemplary vs 0% from a fixed config that ever routes everything to 1 costly model.” Static routing has 100% determinism but 0% intelligence.
Routing Overhead: When 200ms Matters and When It Doesn’t
Every routing determination adds astir 200ms earlier the first token. This is not zero, and it’s worthy being clear astir erstwhile it matters.
When 200ms is negligible: In interactive chat applications, users hold for the first token anyway. A frontier exemplary for illustration GPT-5.2 whitethorn person a TTFT of 800ms–2s nether load. Adding 200ms routing overhead connected apical of a 1.2s TTFT results successful a 1.4s perceived latency, a 17% increase, not noticeable during normal conversations.
When 200ms is significant: Real-time applications wherever TTFT is the ascendant personification acquisition metric. If you’re building a sound adjunct wherever the first token successful nether 300ms is simply a difficult requirement, and the routing overhead unsocial is 200ms, that’s 67% of your fund connected routing. In this case, either usage the 4B dense exemplary version (lower overhead) aliases a preset router that doesn’t require intent classification (e.g., a single-task router pinch velocity optimization policy).
When 200ms saves much than it costs: When routing sends a petition to a faster exemplary than you would person utilized otherwise. If your fixed config defaults to GPT-5.2 (TTFT: ~1,100ms), and the router classifies the petition arsenic elemental and sends it to a faster exemplary (TTFT: ~350ms), the nett latency is 350ms + 200ms = 550ms — still 50% faster than the fixed config.
Static routing: [request] ──────────────────── GPT-5.2 ── TTFT: 1,100ms Router: [request] ── 200ms routing ─── Cheaper/faster exemplary ── TTFT: 350ms Net TTFT pinch routing: 550ms (50% faster than static)Cost: A Worked Example
Suppose you’re moving a coding supplier that generates 10 cardinal output tokens per day. Based connected the emblematic task distribution successful a coding agent:
| Simple lookups, syntax checks, explanations | 35% | “What does this correction mean?” |
| Moderate codification generation | 40% | “Write a usability to validate this input” |
| Complex reasoning, architecture, and debugging | 25% | “Why is this causing a title condition?” |
With a frontier-only fixed config astatine $15/million output tokens (approximate GPT-5.2 pricing):
10M tokens/day × $15/M = $150/day → $4,500/monthWith routing that sends the 35% elemental tasks to a $1/M token model, 40% mean tasks to a $5/M model, and keeps 25% analyzable tasks connected the $15/M model:
3.5M tokens × $1/M = $3.50/day 4.0M tokens × $5/M = $20.00/day 2.5M tokens × $15/M = $37.50/day Total: $61/day → $1,830/monthThat’s a 59% simplification connected the output token measure from routing alone, pinch nary changes to which exemplary handles analyzable tasks. Your existent savings will alteration based connected task operation and existent exemplary pricing.
DigitalOcean Inference Engine
Inference Router is 1 furniture wrong DigitalOcean’s Inference Engine — the broader level for moving instauration models successful production. Understanding the afloat stack helps find what the router tin and can’t dispatch.
The Inference Engine has 3 serving modes:
Serverless Inference — salary per token, nary GPU reservation. Requests are served from shared GPU capacity. Best for adaptable aliases unpredictable postulation wherever you don’t want to pre-commit to dedicated hardware. The router tin dispatch to serverless models.
Dedicated Inference — reserved GPU capacity for your workload. Predictable latency, nary cold-start overhead, suitable for compliance requirements wherever you request isolated compute. The router tin dispatch to dedicated conclusion endpoints erstwhile the action argumentation is Speed Optimization aliases Manual Ranking (dedicated instances are excluded from the Cost Efficiency auto-ranking because their pricing exemplary is hourly, not per-token).
Batch Inference — async processing for offline workloads. Not successful the router’s way — batch jobs are submitted separately done the batch API.
The Model Catalog presently includes 40+ models crossed text, image, audio, and video from OpenAI, Anthropic, Meta, Mistral, and open-source providers. Inference Router tin only dispatch to text/chat models.
Analyze dashboard metrics:
Once your router is receiving traffic, the Control Panel’s Analyze tab shows:
- Total requests routed per clip window
- Total token usage (input + output) crossed each routed models
- Task lucifer rate: percent of requests matched to a configured task (vs. falling done to fallback)
- Fallback rate: percent of requests that deed the fallback exemplary pool
A patient router typically shows a task lucifer complaint supra 85%. If your fallback complaint is supra 20%, your task descriptions are apt excessively constrictive — requests that should lucifer a task are falling through.
Evaluating earlier production:
Before switching accumulation postulation to a router, usage the Playground’s comparison mode: way a group of trial prompts done some the router and a azygous frontier exemplary broadside by side. Each consequence shows the exemplary selected, end-to-end latency, and costs per request. The Evals characteristic extends this to datasets — upload 50–100 typical prompts, tally evaluation, and get LLM-as-a-Judge correctness and completeness scores for the router vs. your fixed baseline.
Writing Task Descriptions That Actually Work
One of the little evident findings from moving Inference Router successful accumulation is that routing accuracy is highly delicate to really task descriptions are written. The routing exemplary sounds these descriptions straight to lucifer each request; really you constitute them determines really good routing works.
Here’s why this matters technically: the Plano-Orchestrator exemplary compares each incoming connection against your task descriptions utilizing semantic matching, not keyword matching. That intends your descriptions request to beryllium circumstantial capable to separate betwixt tasks, but wide capable to screen the existent variations successful really users building the aforesaid intent.
Align Name and Description
The task sanction and explanation should beryllium consistent, the sanction is simply a label, and the explanation is the elaboration. If they contradict each other, the exemplary has a conflicting signal.
// Good: sanction and explanation reenforce each other { "name": "bug_fixing", "description": "Identify and hole errors, exceptions, aliases incorrect behaviour successful user-supplied code" } // Bad: sanction says "math" but explanation is vague and could lucifer almost anything { "name": "math", "description": "handle thing related to numbers aliases calculations" }Be Specific Enough to Distinguish Tasks
If 2 task descriptions overlap significantly, the router will person trouble distinguishing betwixt them. This is particularly problematic erstwhile some tasks constituent to very different exemplary pools.
// Problematic: these 2 descriptions lucifer galore of the aforesaid prompts [ { "name": "technical_writing", "description": "Write method content, documentation, aliases explanations" }, { "name": "code_documentation", "description": "Document code, constitute docstrings, aliases create API references" } ] // Better: make the distinctions explicit [ { "name": "technical_writing", "description": "Write tutorials, blog posts, aliases conceptual explanations for method audiences, not involving nonstop codification documentation" }, { "name": "code_documentation", "description": "Write inline docstrings, usability comments, README files, aliases API reference archiving straight tied to code" } ]Use Noun-Centric Descriptions
Descriptions that halfway connected the type of task (nouns) alternatively than the feeling of the task (adjectives) nutrient much unchangeable routing. The routing exemplary was trained connected task-type patterns, not sentiment-style signals.
// Less stable: "creative" and "engaging" are vague modifiers { "description": "Write creative, engaging contented that users will enjoy" } // More stable: describes the existent task structure { "description": "Write blog posts, societal media copy, trading emails, aliases promotional content" }Test pinch Real Traffic Before Tuning
The fastest measurement to find gaps successful your task descriptions is to look astatine the router’s fallback rate. If it’s supra 15–20%, propulsion a sample of the requests that fell done to fallback and ask: should these person matched 1 of my tasks? If yes, the explanation missed them — adhd the applicable phrasing. If no, the fallback handling is moving correctly.
# Use the consequence header to way routing decisions successful your ain logs import httpx response = httpx.post( "https://inference.do-ai.run/v1/chat/completions", headers={ "Authorization": f"Bearer {os.environ['MODEL_ACCESS_KEY']}", "Content-Type": "application/json" }, json={ "model": "router:my-coding-router", "messages": [{"role": "user", "content": user_message}] } ) route_selected = response.headers.get("x-model-router-selected-route") model_used = response.json()["model"] # Log these for analysis print(f"Route: {route_selected}, Model: {model_used}")Build a spreadsheet of (prompt, route_selected, model_used) from a time of traffic. Look astatine the “fallback” rows — those are your explanation gaps.
Production Considerations
Fallback Behavior
Every router has fallback models. These grip 2 chopped cases:
- No task matched: The routing exemplary classified the petition arsenic different — nary configured task was a bully fit.
- Selected exemplary is unavailable: The top-ranked exemplary is down, returning errors, aliases rate-limited.
In lawsuit 2, the router cycles done remaining task-pool models successful classed order, past falls done to fallback models. Fallback models are tried successful the bid you specified. If each fail, the petition returns an error.
The applicable implication: your fallback exemplary should beryllium a exemplary you’re comfortable serving any petition to, since it’s your catch-all. A general-purpose exemplary for illustration openai-gpt-oss-120b is simply a communal prime because it handles divers inputs adequately and has a little per-token costs than frontier models.
Model Aliases and Naming
The pricing API and your routing config whitethorn usage different names for the aforesaid model. For example, the pricing catalog mightiness database openai-gpt-5.2 while your YAML uses openai/gpt-5.2. Plano’s model_aliases representation bridges this:
# In Plano config for self-hosted deployments model_aliases: "openai/gpt-5.2": "openai-gpt-5.2" "anthropic/claude-sonnet-4": "anthropic-claude-sonnet-4.5"On DigitalOcean’s managed router, this is handled automatically — usage the exemplary slugs from the Model Catalog.
Frequently Asked Questions
- What does the Inference Router really do? It automatically picks which AI exemplary should grip each petition based connected what the petition is asking. Instead of ever utilizing 1 costly model, it matches each petition to the astir due and cost-effective exemplary for that task.
- How does it cognize which exemplary to use? It runs a mini AI exemplary (Plano-Orchestrator) successful the petition way that sounds your connection and matches it to a task type you’ve configured, for illustration “code review” aliases “general questions.” It past picks the champion disposable exemplary for that task, sorted by costs aliases velocity depending connected your preference.
- Does it slow down my application? It adds astir 200ms earlier the first consequence token. For astir chat aliases supplier workloads, this is not noticeable frontier models already return 800ms–2s to respond nether load. If you person strict real-time requirements, the lighter 4B exemplary version has little overhead.
- How overmuch tin it trim my costs? It depends connected your workload, but accumulation information shows 40–60% costs simplification compared to routing everything to a azygous frontier model. Results will alteration based connected your task operation and exemplary pricing astatine the time.
- What happens if the selected exemplary is unavailable? The router automatically tries the adjacent exemplary successful the task pool, past moves to your configured fallback models. Your exertion doesn’t request to grip this — it happens transparently, pinch nary dropped requests.
- What if my petition doesn’t lucifer immoderate task I’ve configured? It gets routed to your fallback models a database of general-purpose models that enactment arsenic a catch-all. The router ne'er returns an correction conscionable because a task didn’t match.
- How do I get started? Change the exemplary section successful your existing API telephone from a circumstantial exemplary sanction to "router:software-engineering" (or different preset). No different codification changes are required. Full setup instructions are successful the DigitalOcean Inference Router docs.
Conclusion: What MoE-Based Routing Actually Solves
Routing each petition to the aforesaid exemplary is simply a costs problem, and the solutions teams person historically reached for — fixed exemplary action aliases application-layer classifiers — some person basal problems. One overpays for each request. The different adds an other conclusion telephone connected apical of each petition and introduces routing logic that personification has to maintain.
The attack DigitalOcean’s Inference Router takes is different successful 1 important way: it puts a purpose-built MoE exemplary successful the infrastructure furniture and makes it portion of the petition path, not the exertion layer. The 30B-A3B Plano-Orchestrator exemplary activates ~3B parameters to resoluteness intent successful ~200ms — accelerated capable to not meaningfully impact latency connected interactive workloads, meticulous capable (87.84% vs GPT-5.1’s 86.93%) to way correctly crossed analyzable multi-turn coding and long-context conversations.
The numbers from accumulation support the premise: routing correctly crossed a mixed workload pinch a reasonable task distribution cuts conclusion costs by 40–60% compared to a azygous frontier model.
For astir accumulation agentic workloads — wherever the task operation is genuinely varied, the measurement is precocious capable for costs to matter, and latency requirements person astatine slightest 200ms of headroom — the tradeoff is favorable.
Start pinch a preset router if your workload fits package engineering, writing, knowledge base, aliases wide patterns. The exemplary pools and action policies are benchmarked by DigitalOcean’s information subject team, and you’re routing successful minutes pinch 1 drawstring change.
Build a civilization router erstwhile your task taxonomy is circumstantial to your domain — ineligible archive analysis, aesculapian Q&A, financial modeling — wherever the preset categories don’t representation cleanly.
References
DigitalOcean Resources
- How We Built DigitalOcean Inference Router — Adil Hafeez, Principal Engineer
- Inference Router Documentation
- Introducing DigitalOcean AI-Native Cloud — Paddy Srinivasan, CEO
- Inference Engine Product Page
- Plano (open source)
Research Papers
- Arch-Router: Aligning LLM Routing pinch Human Preferences
- RouteLLM: Learning to Route LLMs pinch Preference Data
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
- LLMRouterBench: A Massive Benchmark and Unified Framework for LLM Routing
- Universal Model Routing for Efficient LLM Inference
- Signals: Trajectory Sampling and Triage for Agentic Interactions
- Shazeer et al., 2017 — Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Fedus et al., 2021 — Switch Transformers: Scaling to Trillion Parameter Models
Plano-Orchestrator Models (HuggingFace)
- Plano-Orchestrator-4B
- Arch-Router-1.5B
 This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This activity is licensed nether a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.


.png "Python Array Add: How To Append, Extend & Insert Elements")




.png "What Breaks When Multi-agent Systems Scale")





") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·